 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Generative Adversarial Networks: A Review
Nov 04, 2020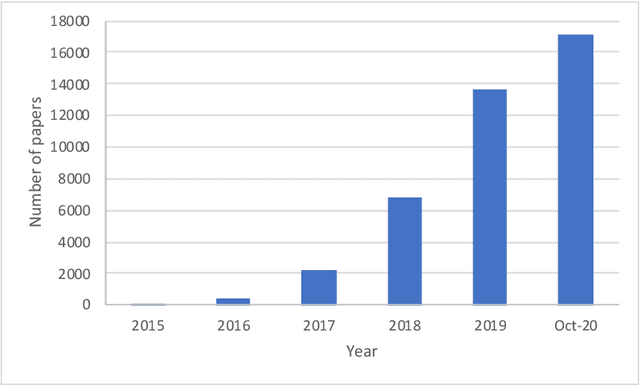
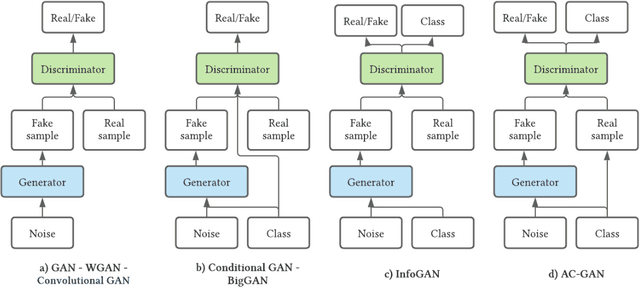
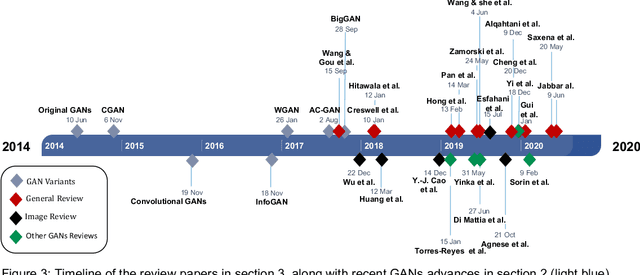
With the increasing interest in the content creation field in multiple sectors such as media, education, and entertainment, there is an increasing trend in the papers that uses AI algorithms to generate content such as images, videos, audio, and text. Generative Adversarial Networks (GANs) in one of the promising models that synthesizes data samples that are similar to real data samples. While the variations of GANs models, in general, have been covered to some extent in several survey papers, to the best of our knowledge, this is among the first survey papers that reviews the state-of-the-art video GANs models. This paper first categorized GANs review papers into general GANs review papers, image GANs review papers, and special field GANs review papers such as anomaly detection, medical imaging, or cybersecurity. The paper then summarizes the main improvements in GANs frameworks that are not initially developed for the video domain but have been adopted in multiple video GANs variations. Then, a comprehensive review of video GANs models is provided under two main divisions according to the presence or non-presence of a condition. The conditional models then further grouped according to the type of condition into audio, text, video, and image. The paper is concluded by highlighting the main challenges and limitations of the current video GANs models. A comprehensive list of datasets, applied loss functions, and evaluation metrics is provided in the supplementary material.