 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs4Life: Large Language Models for Ontology Learning in Life Sciences
Dec 02, 2024
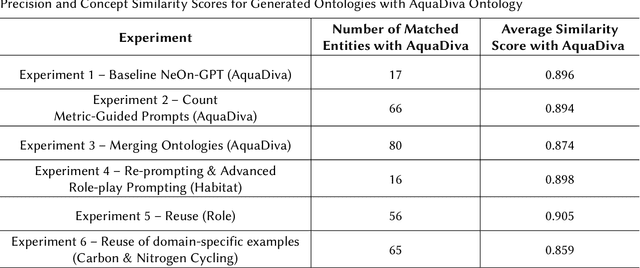
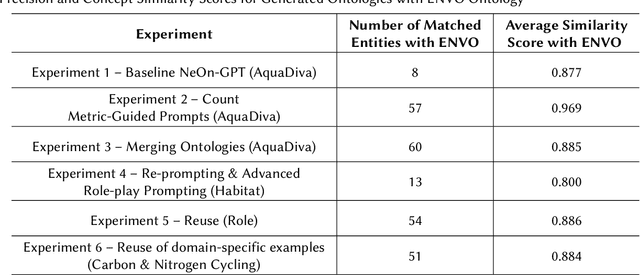
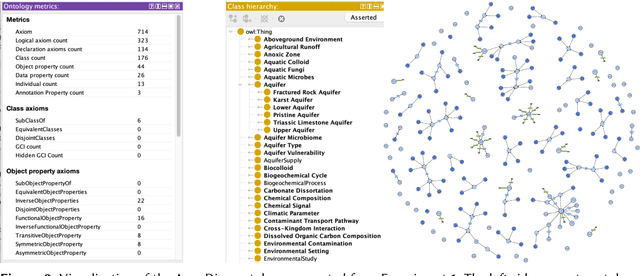
Ontology learning in complex domains, such as life sciences, poses significant challenges for current Large Language Models (LLMs). Existing LLMs struggle to generate ontologies with multiple hierarchical levels, rich interconnections, and comprehensive class coverage due to constraints on the number of tokens they can generate and inadequate domain adaptation. To address these issues, we extend the NeOn-GPT pipeline for ontology learning using LLMs with advanced prompt engineering techniques and ontology reuse to enhance the generated ontologies' domain-specific reasoning and structural depth. Our work evaluates the capabilities of LLMs in ontology learning in the context of highly specialized and complex domains such as life science domains. To assess the logical consistency, completeness, and scalability of the generated ontologies, we use the AquaDiva ontology developed and used in the collaborative research center AquaDiva as a case study. Our evaluation shows the viability of LLMs for ontology learning in specialized domains, providing solutions to longstanding limitations in model performance and scalability.
Empowering the Deaf and Hard of Hearing Community: Enhancing Video Captions Using Large Language Models
Nov 30, 2024



In today's digital age, video content is prevalent, serving as a primary source of information, education, and entertainment. However, the Deaf and Hard of Hearing (DHH) community often faces significant challenges in accessing video content due to the inadequacy of automatic speech recognition (ASR) systems in providing accurate and reliable captions. This paper addresses the urgent need to improve video caption quality by leveraging Large Language Models (LLMs). We present a comprehensive study that explores the integration of LLMs to enhance the accuracy and context-awareness of captions generated by ASR systems. Our methodology involves a novel pipeline that corrects ASR-generated captions using advanced LLMs. It explicitly focuses on models like GPT-3.5 and Llama2-13B due to their robust performance in language comprehension and generation tasks. We introduce a dataset representative of real-world challenges the DHH community faces to evaluate our proposed pipeline. Our results indicate that LLM-enhanced captions significantly improve accuracy, as evidenced by a notably lower Word Error Rate (WER) achieved by ChatGPT-3.5 (WER: 9.75%) compared to the original ASR captions (WER: 23.07%), ChatGPT-3.5 shows an approximate 57.72% improvement in WER compared to the original ASR captions.