 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023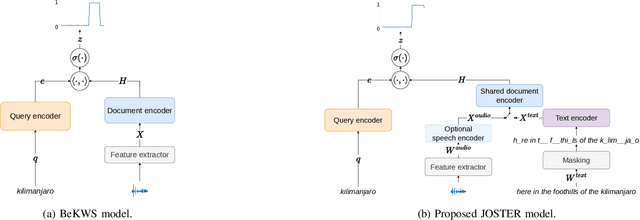

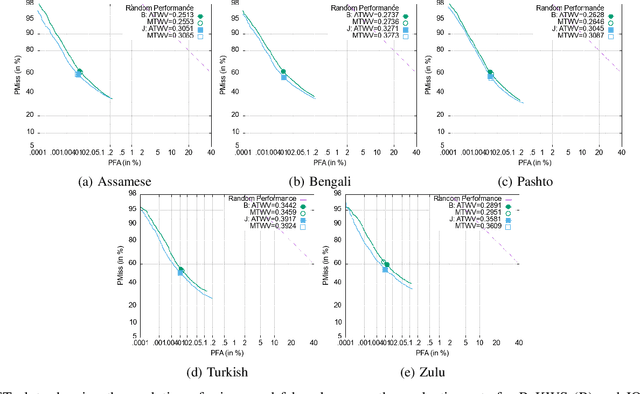
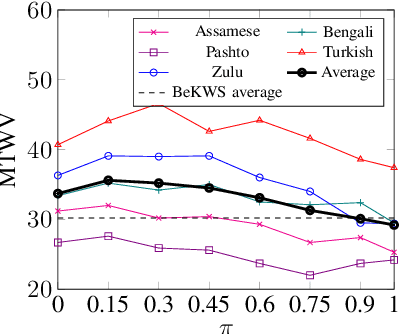
Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
End-to-End Open Vocabulary Keyword Search
Aug 23, 2021



Recently, neural approaches to spoken content retrieval have become popular. However, they tend to be restricted in their vocabulary or in their ability to deal with imbalanced test settings. These restrictions limit their applicability in keyword search, where the set of queries is not known beforehand, and where the system should return not just whether an utterance contains a query but the exact location of any such occurrences. In this work, we propose a model directly optimized for keyword search. The model takes a query and an utterance as input and returns a sequence of probabilities for each frame of the utterance of the query having occurred in that frame. Experiments show that the proposed model not only outperforms similar end-to-end models on a task where the ratio of positive and negative trials is artificially balanced, but it is also able to deal with the far more challenging task of keyword search with its inherent imbalance. Furthermore, using our system to rescore the outputs an LVCSR-based keyword search system leads to significant improvements on the latter.
A Hierarchical Subspace Model for Language-Attuned Acoustic Unit Discovery
Nov 09, 2020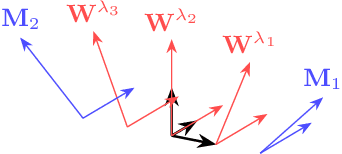
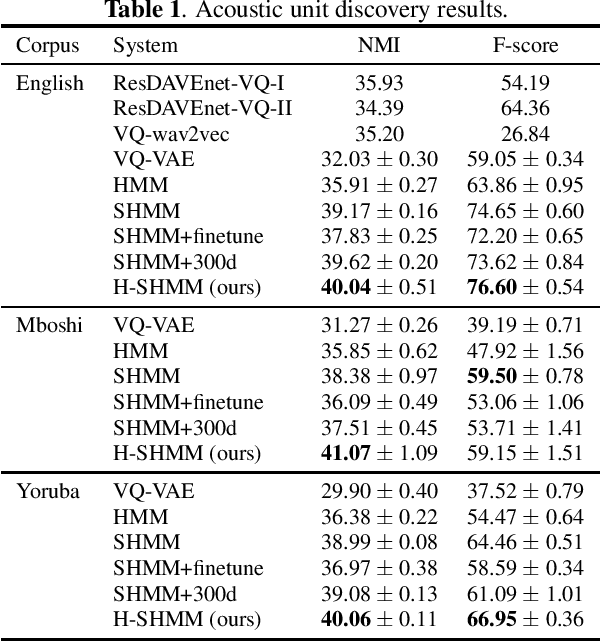
In this work, we propose a hierarchical subspace model for acoustic unit discovery. In this approach, we frame the task as one of learning embeddings on a low-dimensional phonetic subspace, and simultaneously specify the subspace itself as an embedding on a hyper-subspace. We train the hyper-subspace on a set of transcribed languages and transfer it to the target language. In the target language, we infer both the language and unit embeddings in an unsupervised manner, and in so doing, we simultaneously learn a subspace of units specific to that language and the units that dwell on it. We conduct our experiments on TIMIT and two low-resource languages: Mboshi and Yoruba. Results show that our model outperforms major acoustic unit discovery techniques, both in terms of clustering quality and segmentation accuracy.