 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Spatial, Angular, and Temporal Information for Enhanced Lane Detection
May 05, 2024
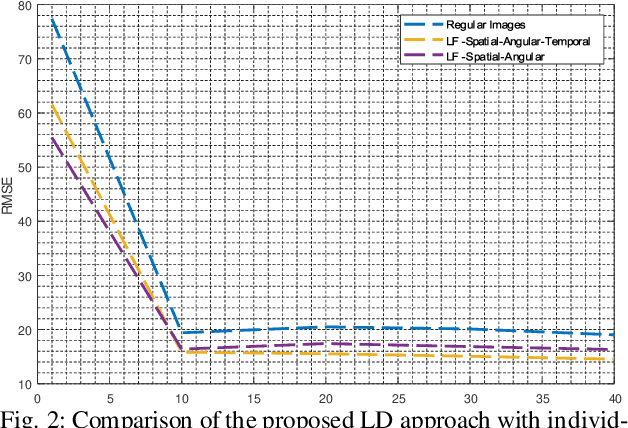
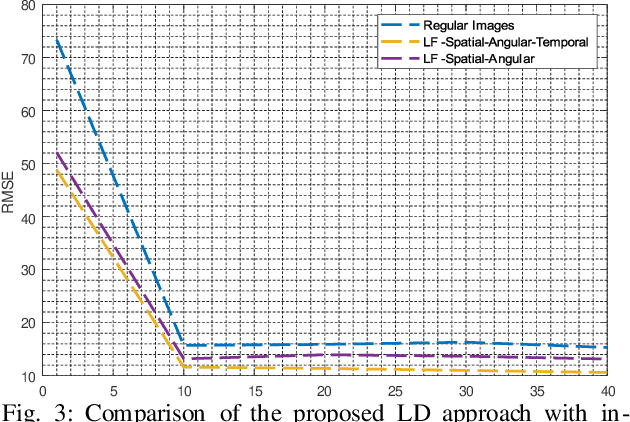
This paper introduces a novel approach for enhanced lane detection by integrating spatial, angular, and temporal information through light field imaging and novel deep learning models. Utilizing lenslet-inspired 2D light field representations and LSTM networks, our method significantly improves lane detection in challenging conditions. We demonstrate the efficacy of this approach with modified CNN architectures, showing superior per- formance over traditional methods. Our findings suggest this integrated data approach could advance lane detection technologies and inspire new models that leverage these multidimensional insights for autonomous vehicle percep- tion.
Trade-off Between Spatial and Angular Resolution in Facial Recognition
Feb 11, 2024Ensuring robustness in face recognition systems across various challenging conditions is crucial for their versatility. State-of-the-art methods often incorporate additional information, such as depth, thermal, or angular data, to enhance performance. However, light field-based face recognition approaches that leverage angular information face computational limitations. This paper investigates the fundamental trade-off between spatio-angular resolution in light field representation to achieve improved face recognition performance. By utilizing macro-pixels with varying angular resolutions while maintaining the overall image size, we aim to quantify the impact of angular information at the expense of spatial resolution, while considering computational constraints. Our experimental results demonstrate a notable performance improvement in face recognition systems by increasing the angular resolution, up to a certain extent, at the cost of spatial resolution.
SafeSpace MFNet: Precise and Efficient MultiFeature Drone Detection Network
Nov 30, 2022Unmanned air vehicles (UAVs) popularity is on the rise as it enables the services like traffic monitoring, emergency communications, deliveries, and surveillance. However, the unauthorized usage of UAVs (a.k.a drone) may violate security and privacy protocols for security-sensitive national and international institutions. The presented challenges require fast, efficient, and precise detection of UAVs irrespective of harsh weather conditions, the presence of different objects, and their size to enable SafeSpace. Recently, there has been significant progress in using the latest deep learning models, but those models have shortcomings in terms of computational complexity, precision, and non-scalability. To overcome these limitations, we propose a precise and efficient multiscale and multifeature UAV detection network for SafeSpace, i.e., \textit{MultiFeatureNet} (\textit{MFNet}), an improved version of the popular object detection algorithm YOLOv5s. In \textit{MFNet}, we perform multiple changes in the backbone and neck of the YOLOv5s network to focus on the various small and ignored features required for accurate and fast UAV detection. To further improve the accuracy and focus on the specific situation and multiscale UAVs, we classify the \textit{MFNet} into small (S), medium (M), and large (L): these are the combinations of various size filters in the convolution and the bottleneckCSP layers, reside in the backbone and neck of the architecture. This classification helps to overcome the computational cost by training the model on a specific feature map rather than all the features. The dataset and code are available as an open source: github.com/ZeeshanKaleem/MultiFeatureNet.