 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Adaptive Traffic Signal Control: Turn-Based and Time-Based Approaches to Reduce Congestion
Sep 01, 2024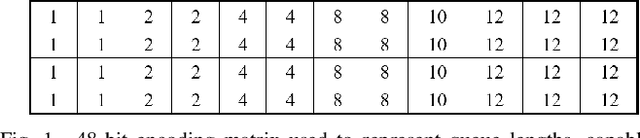
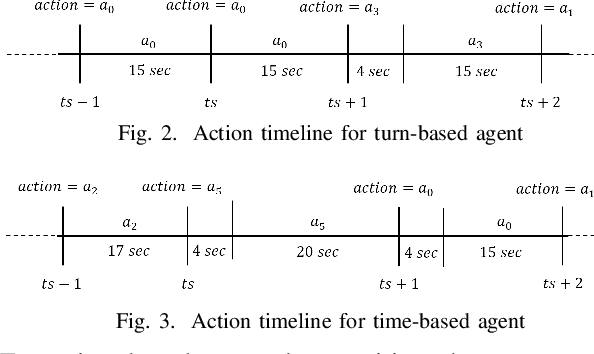
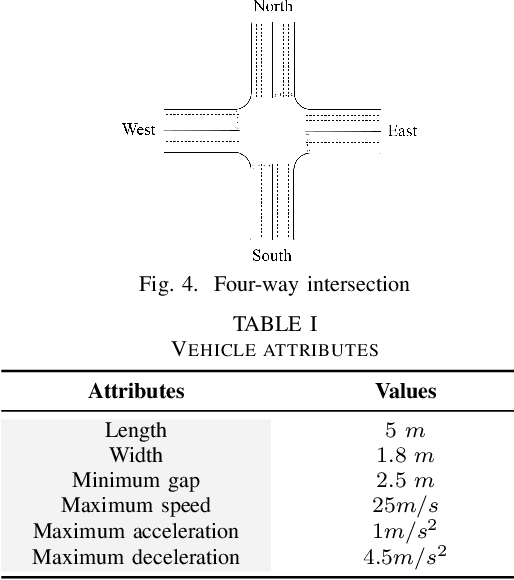
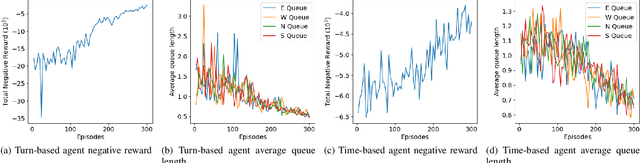
The growing demand for road use in urban areas has led to significant traffic congestion, posing challenges that are costly to mitigate through infrastructure expansion alone. As an alternative, optimizing existing traffic management systems, particularly through adaptive traffic signal control, offers a promising solution. This paper explores the use of Reinforcement Learning (RL) to enhance traffic signal operations at intersections, aiming to reduce congestion without extensive sensor networks. We introduce two RL-based algorithms: a turn-based agent, which dynamically prioritizes traffic signals based on real-time queue lengths, and a time-based agent, which adjusts signal phase durations according to traffic conditions while following a fixed phase cycle. By representing the state as a scalar queue length, our approach simplifies the learning process and lowers deployment costs. The algorithms were tested in four distinct traffic scenarios using seven evaluation metrics to comprehensively assess performance. Simulation results demonstrate that both RL algorithms significantly outperform conventional traffic signal control systems, highlighting their potential to improve urban traffic flow efficiently.
A Permuted Autoregressive Approach to Word-Level Recognition for Urdu Digital Text
Aug 30, 2024
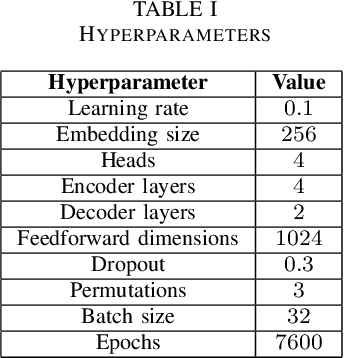
This research paper introduces a novel word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text, leveraging transformer-based architectures and attention mechanisms to address the distinct challenges of Urdu script recognition, including its diverse text styles, fonts, and variations. The model employs a permuted autoregressive sequence (PARSeq) architecture, which enhances its performance by enabling context-aware inference and iterative refinement through the training of multiple token permutations. This method allows the model to adeptly manage character reordering and overlapping characters, commonly encountered in Urdu script. Trained on a dataset comprising approximately 160,000 Urdu text images, the model demonstrates a high level of accuracy in capturing the intricacies of Urdu script, achieving a CER of 0.178. Despite ongoing challenges in handling certain text variations, the model exhibits superior accuracy and effectiveness in practical applications. Future work will focus on refining the model through advanced data augmentation techniques and the integration of context-aware language models to further enhance its performance and robustness in Urdu text recognition.