 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Permuted Autoregressive Approach to Word-Level Recognition for Urdu Digital Text
Aug 30, 2024
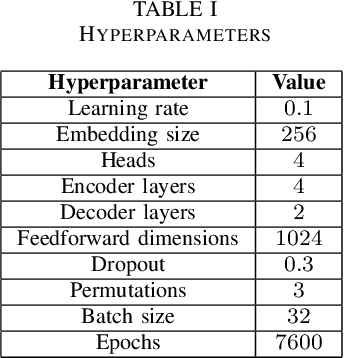
This research paper introduces a novel word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text, leveraging transformer-based architectures and attention mechanisms to address the distinct challenges of Urdu script recognition, including its diverse text styles, fonts, and variations. The model employs a permuted autoregressive sequence (PARSeq) architecture, which enhances its performance by enabling context-aware inference and iterative refinement through the training of multiple token permutations. This method allows the model to adeptly manage character reordering and overlapping characters, commonly encountered in Urdu script. Trained on a dataset comprising approximately 160,000 Urdu text images, the model demonstrates a high level of accuracy in capturing the intricacies of Urdu script, achieving a CER of 0.178. Despite ongoing challenges in handling certain text variations, the model exhibits superior accuracy and effectiveness in practical applications. Future work will focus on refining the model through advanced data augmentation techniques and the integration of context-aware language models to further enhance its performance and robustness in Urdu text recognition.