 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Distinct, Effective Treatments for Acute Hypotension with SODA-RL: Safely Optimized Diverse Accurate Reinforcement Learning
Jan 09, 2020

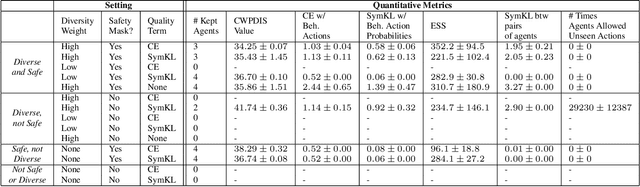
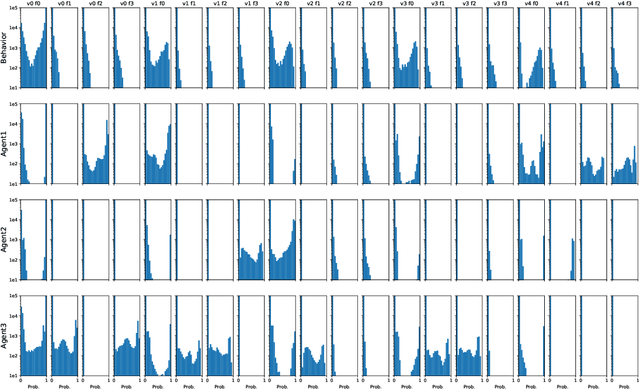
Hypotension in critical care settings is a life-threatening emergency that must be recognized and treated early. While fluid bolus therapy and vasopressors are common treatments, it is often unclear which interventions to give, in what amounts, and for how long. Observational data in the form of electronic health records can provide a source for helping inform these choices from past events, but often it is not possible to identify a single best strategy from observational data alone. In such situations, we argue it is important to expose the collection of plausible options to a provider. To this end, we develop SODA-RL: Safely Optimized, Diverse, and Accurate Reinforcement Learning, to identify distinct treatment options that are supported in the data. We demonstrate SODA-RL on a cohort of 10,142 ICU stays where hypotension presented. Our learned policies perform comparably to the observed physician behaviors, while providing different, plausible alternatives for treatment decisions.
Diversity-Inducing Policy Gradient: Using Maximum Mean Discrepancy to Find a Set of Diverse Policies
May 31, 2019



Standard reinforcement learning methods aim to master one way of solving a task whereas there may exist multiple near-optimal policies. Being able to identify this collection of near-optimal policies can allow a domain expert to efficiently explore the space of reasonable solutions. Unfortunately, existing approaches that quantify uncertainty over policies are not ultimately relevant to finding policies with qualitatively distinct behaviors. In this work, we formalize the difference between policies as a difference between the distribution of trajectories induced by each policy, which encourages diversity with respect to both state visitation and action choices. We derive a gradient-based optimization technique that can be combined with existing policy gradient methods to now identify diverse collections of well-performing policies. We demonstrate our approach on benchmarks and a healthcare task.