 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Adaptive Successive Doubling for Hyperparameter Optimization with Large Datasets on High-Performance Computing Systems
Dec 03, 2024



On High-Performance Computing (HPC) systems, several hyperparameter configurations can be evaluated in parallel to speed up the Hyperparameter Optimization (HPO) process. State-of-the-art HPO methods follow a bandit-based approach and build on top of successive halving, where the final performance of a combination is estimated based on a lower than fully trained fidelity performance metric and more promising combinations are assigned more resources over time. Frequently, the number of epochs is treated as a resource, letting more promising combinations train longer. Another option is to use the number of workers as a resource and directly allocate more workers to more promising configurations via data-parallel training. This article proposes a novel Resource-Adaptive Successive Doubling Algorithm (RASDA), which combines a resource-adaptive successive doubling scheme with the plain Asynchronous Successive Halving Algorithm (ASHA). Scalability of this approach is shown on up to 1,024 Graphics Processing Units (GPUs) on modern HPC systems. It is applied to different types of Neural Networks (NNs) and trained on large datasets from the Computer Vision (CV), Computational Fluid Dynamics (CFD), and Additive Manufacturing (AM) domains, where performing more than one full training run is usually infeasible. Empirical results show that RASDA outperforms ASHA by a factor of up to 1.9 with respect to the runtime. At the same time, the solution quality of final ASHA models is maintained or even surpassed by the implicit batch size scheduling of RASDA. With RASDA, systematic HPO is applied to a terabyte-scale scientific dataset for the first time in the literature, enabling efficient optimization of complex models on massive scientific data. The implementation of RASDA is available on https://github.com/olympiquemarcel/rasda
A Single-Step Multiclass SVM based on Quantum Annealing for Remote Sensing Data Classification
Mar 21, 2023



In recent years, the development of quantum annealers has enabled experimental demonstrations and has increased research interest in applications of quantum annealing, such as in quantum machine learning and in particular for the popular quantum SVM. Several versions of the quantum SVM have been proposed, and quantum annealing has been shown to be effective in them. Extensions to multiclass problems have also been made, which consist of an ensemble of multiple binary classifiers. This work proposes a novel quantum SVM formulation for direct multiclass classification based on quantum annealing, called Quantum Multiclass SVM (QMSVM). The multiclass classification problem is formulated as a single Quadratic Unconstrained Binary Optimization (QUBO) problem solved with quantum annealing. The main objective of this work is to evaluate the feasibility, accuracy, and time performance of this approach. Experiments have been performed on the D-Wave Advantage quantum annealer for a classification problem on remote sensing data. The results indicate that, despite the memory demands of the quantum annealer, QMSVM can achieve accuracy that is comparable to standard SVM methods and, more importantly, it scales much more efficiently with the number of training examples, resulting in nearly constant time. This work shows an approach for bringing together classical and quantum computation, solving practical problems in remote sensing with current hardware.
Towards Large-Scale Rendering of Simulated Crops for Synthetic Ground Truth Generation on Modular Supercomputers
Oct 28, 2021
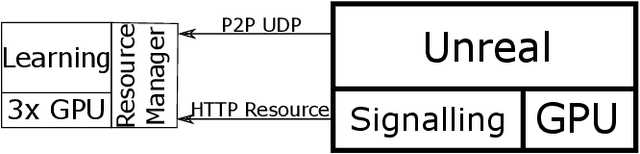
Computer Vision problems deal with the semantic extraction of information from camera images. Especially for field crop images, the underlying problems are hard to label and even harder to learn, and the availability of high-quality training data is low. Deep neural networks do a good job of extracting the necessary models from training examples. However, they rely on an abundance of training data that is not feasible to generate or label by expert annotation. To address this challenge, we make use of the Unreal Engine to render large and complex virtual scenes. We rely on the performance of individual nodes by distributing plant simulations across nodes and both generate scenes as well as train neural networks on GPUs, restricting node communication to parallel learning.