 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs your algorithm unlearning or untraining?
Apr 09, 2026As models are getting larger and are trained on increasing amounts of data, there has been an explosion of interest into how we can ``delete'' specific data points or behaviours from a trained model, after the fact. This goal has been referred to as ``machine unlearning''. In this note, we argue that the term ``unlearning'' has been overloaded, with different research efforts spanning two distinct problem formulations, but without that distinction having been observed or acknowledged in the literature. This causes various issues, including ambiguity around when an algorithm is expected to work, use of inappropriate metrics and baselines when comparing different algorithms to one another, difficulty in interpreting results, as well as missed opportunities for pursuing critical research directions. In this note, we address this issue by establishing a fundamental distinction between two notions that we identify as \unlearning and \untraining, illustrated in Figure 1. In short, \untraining aims to reverse the effect of having trained on a given forget set, i.e. to remove the influence that that specific forget set examples had on the model during training. On the other hand, the goal of \unlearning is not just to remove the influence of those given examples, but to use those examples for the purpose of more broadly removing the entire underlying distribution from which those examples were sampled (e.g. the concept or behaviour that those examples represent). We discuss technical definitions of these problems and map problem settings studied in the literature to each. We hope to initiate discussions on disambiguating technical definitions and identify a set of overlooked research questions, as we believe that this a key missing step for accelerating progress in the field of ``unlearning''.
Federated Learning Under Intermittent Client Availability and Time-Varying Communication Constraints
May 13, 2022
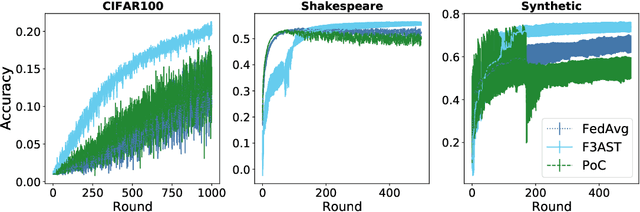
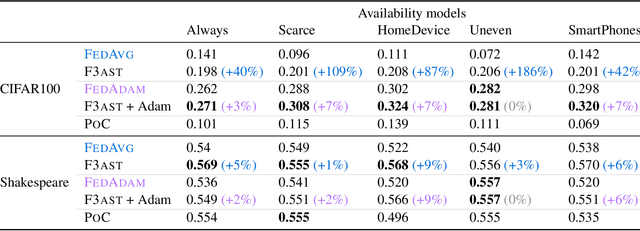
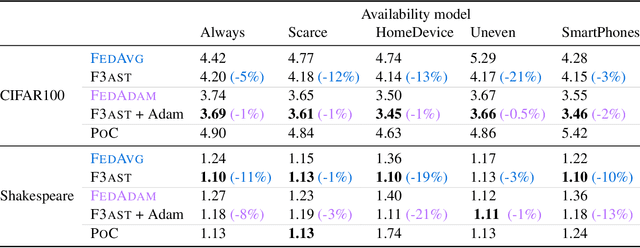
Federated learning systems facilitate training of global models in settings where potentially heterogeneous data is distributed across a large number of clients. Such systems operate in settings with intermittent client availability and/or time-varying communication constraints. As a result, the global models trained by federated learning systems may be biased towards clients with higher availability. We propose F3AST, an unbiased algorithm that dynamically learns an availability-dependent client selection strategy which asymptotically minimizes the impact of client-sampling variance on the global model convergence, enhancing performance of federated learning. The proposed algorithm is tested in a variety of settings for intermittently available clients under communication constraints, and its efficacy demonstrated on synthetic data and realistically federated benchmarking experiments using CIFAR100 and Shakespeare datasets. We show up to 186% and 8% accuracy improvements over FedAvg, and 8% and 7% over FedAdam on CIFAR100 and Shakespeare, respectively.
Communication-Efficient Federated Learning via Optimal Client Sampling
Jul 30, 2020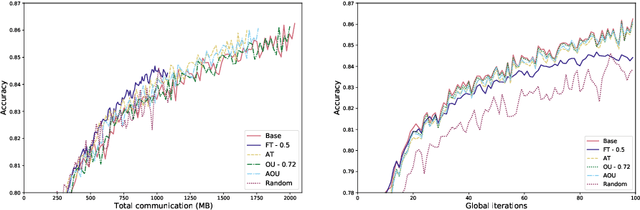
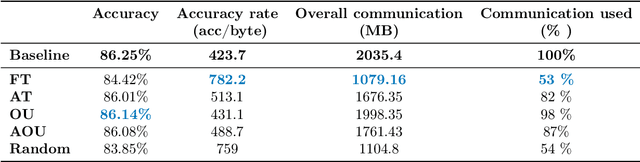
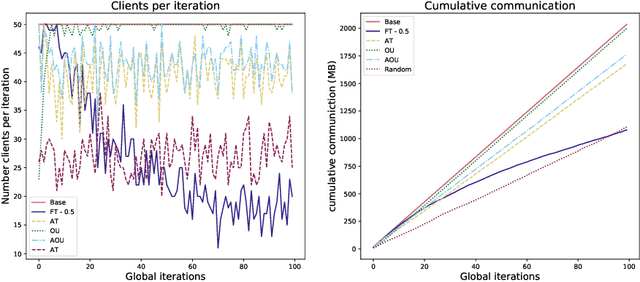
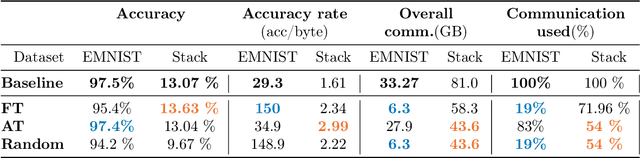
Federated learning is a private and efficient framework for learning models in settings where data is distributed across many clients. Due to interactive nature of the training process, frequent communication of large amounts of information is required between the clients and the central server which aggregates local models. We propose a novel, simple and efficient way of updating the central model in communication-constrained settings by determining the optimal client sampling policy. In particular, modeling the progression of clients' weights by an Ornstein-Uhlenbeck process allows us to derive the optimal sampling strategy for selecting a subset of clients with significant weight updates. The central server then collects local models from only the selected clients and subsequently aggregates them. We propose four client sampling strategies and test them on two federated learning benchmark tests, namely, a classification task on EMNIST and a realistic language modeling task using the Stackoverflow dataset. The results show that the proposed framework provides significant reduction in communication while maintaining competitive or achieving superior performance compared to baseline. Our methods introduce a new line of communication strategies orthogonal to the existing user-local methods such as quantization or sparsification, thus complementing rather than aiming to replace them.