 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Federated Learning via Optimal Client Sampling
Paper and Code
Jul 30, 2020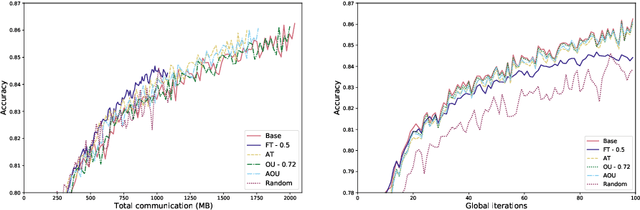
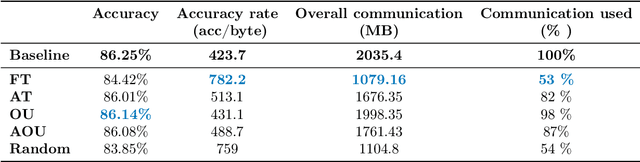
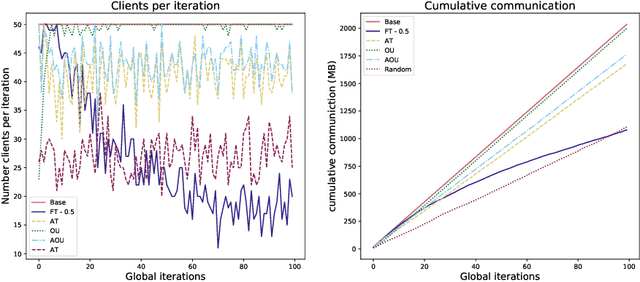
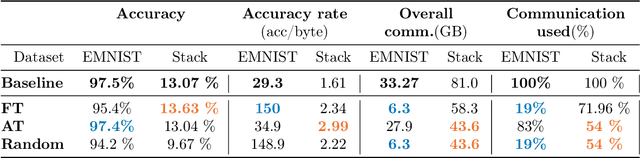
Federated learning is a private and efficient framework for learning models in settings where data is distributed across many clients. Due to interactive nature of the training process, frequent communication of large amounts of information is required between the clients and the central server which aggregates local models. We propose a novel, simple and efficient way of updating the central model in communication-constrained settings by determining the optimal client sampling policy. In particular, modeling the progression of clients' weights by an Ornstein-Uhlenbeck process allows us to derive the optimal sampling strategy for selecting a subset of clients with significant weight updates. The central server then collects local models from only the selected clients and subsequently aggregates them. We propose four client sampling strategies and test them on two federated learning benchmark tests, namely, a classification task on EMNIST and a realistic language modeling task using the Stackoverflow dataset. The results show that the proposed framework provides significant reduction in communication while maintaining competitive or achieving superior performance compared to baseline. Our methods introduce a new line of communication strategies orthogonal to the existing user-local methods such as quantization or sparsification, thus complementing rather than aiming to replace them.