 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping DNN Embedding Manifolds for Network Generalization Prediction
Feb 03, 2022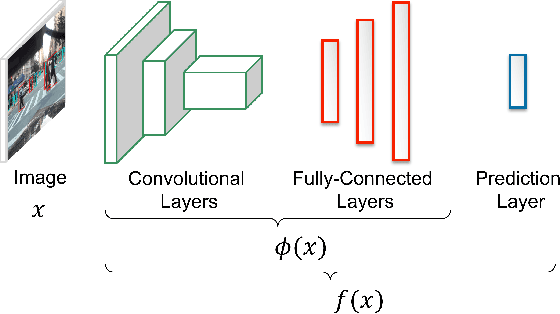

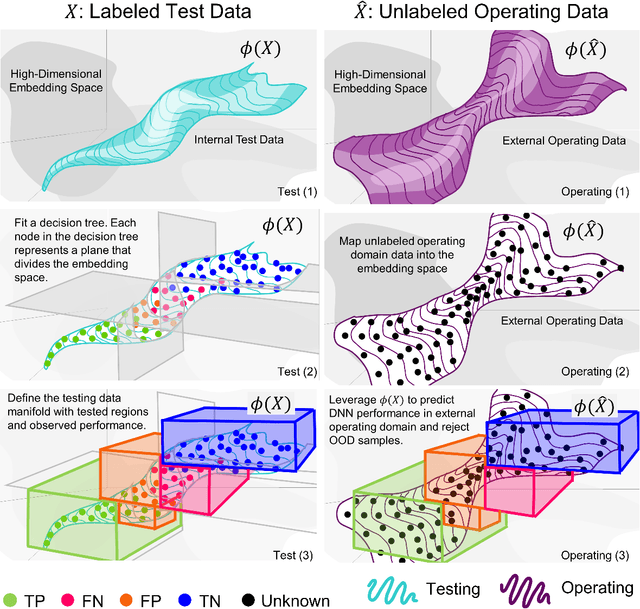

Understanding Deep Neural Network (DNN) performance in changing conditions is essential for deploying DNNs in safety critical applications with unconstrained environments, e.g., perception for self-driving vehicles or medical image analysis. Recently, the task of Network Generalization Prediction (NGP) has been proposed to predict how a DNN will generalize in a new operating domain. Previous NGP approaches have relied on labeled metadata and known distributions for the new operating domains. In this study, we propose the first NGP approach that predicts DNN performance based solely on how unlabeled images from an external operating domain map in the DNN embedding space. We demonstrate this technique for pedestrian, melanoma, and animal classification tasks and show state of the art NGP in 13 of 15 NGP tasks without requiring domain knowledge. Additionally, we show that our NGP embedding maps can be used to identify misclassified images when the DNN performance is poor.
Network Generalization Prediction for Safety Critical Tasks in Novel Operating Domains
Aug 17, 2021


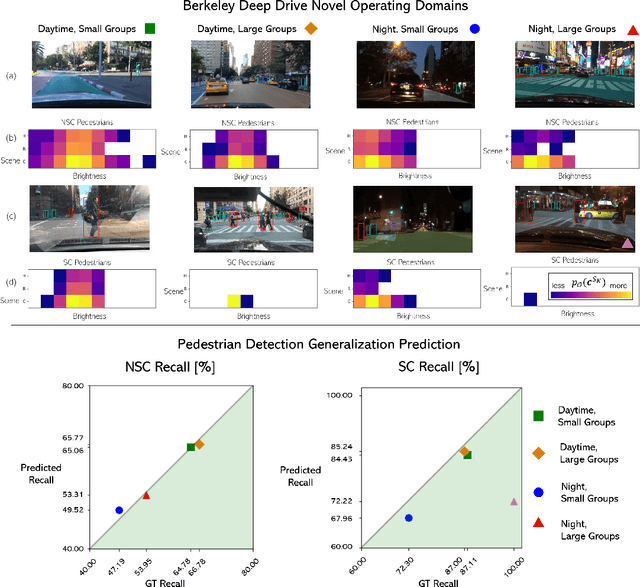
It is well known that Neural Network (network) performance often degrades when a network is used in novel operating domains that differ from its training and testing domains. This is a major limitation, as networks are being integrated into safety critical, cyber-physical systems that must work in unconstrained environments, e.g., perception for autonomous vehicles. Training networks that generalize to novel operating domains and that extract robust features is an active area of research, but previous work fails to predict what the network performance will be in novel operating domains. We propose the task Network Generalization Prediction: predicting the expected network performance in novel operating domains. We describe the network performance in terms of an interpretable Context Subspace, and we propose a methodology for selecting the features of the Context Subspace that provide the most information about the network performance. We identify the Context Subspace for a pretrained Faster RCNN network performing pedestrian detection on the Berkeley Deep Drive (BDD) Dataset, and demonstrate Network Generalization Prediction accuracy within 5% or less of observed performance. We also demonstrate that the Context Subspace from the BDD Dataset is informative for completely unseen datasets, JAAD and Cityscapes, where predictions have a bias of 10% or less.
Robotic Surgery With Lean Reinforcement Learning
May 03, 2021
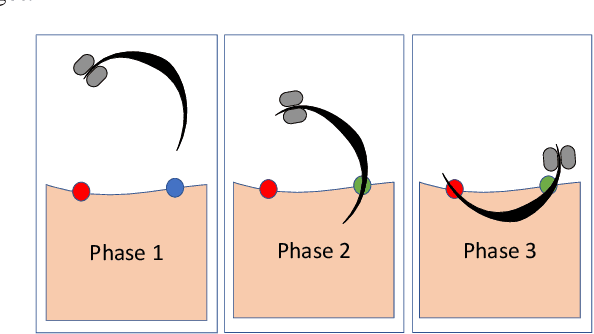
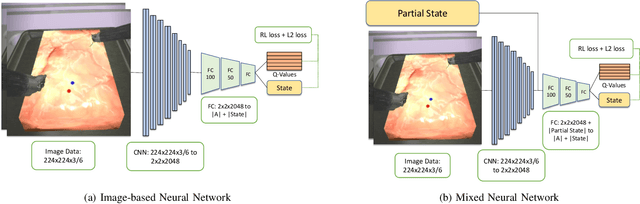
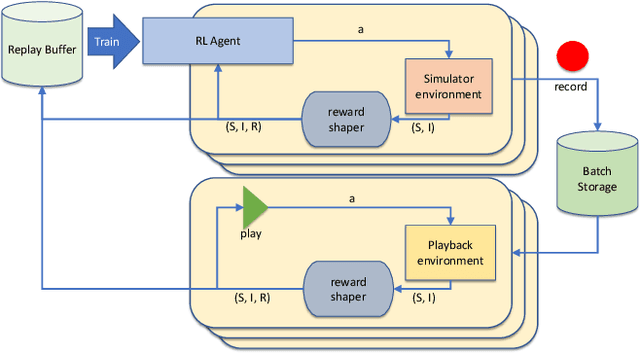
As surgical robots become more common, automating away some of the burden of complex direct human operation becomes ever more feasible. Model-free reinforcement learning (RL) is a promising direction toward generalizable automated surgical performance, but progress has been slowed by the lack of efficient and realistic learning environments. In this paper, we describe adding reinforcement learning support to the da Vinci Skill Simulator, a training simulation used around the world to allow surgeons to learn and rehearse technical skills. We successfully teach an RL-based agent to perform sub-tasks in the simulator environment, using either image or state data. As far as we know, this is the first time an RL-based agent is taught from visual data in a surgical robotics environment. Additionally, we tackle the sample inefficiency of RL using a simple-to-implement system which we term hybrid-batch learning (HBL), effectively adding a second, long-term replay buffer to the Q-learning process. Additionally, this allows us to bootstrap learning from images from the data collected using the easier task of learning from state. We show that HBL decreases our learning times significantly.
Dependable Neural Networks for Safety Critical Tasks
Dec 20, 2019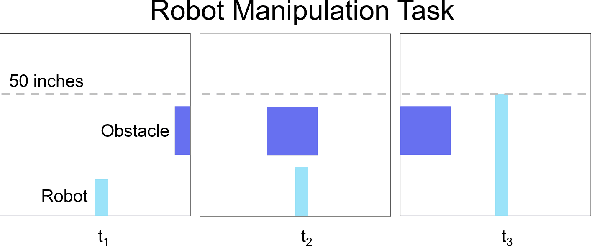
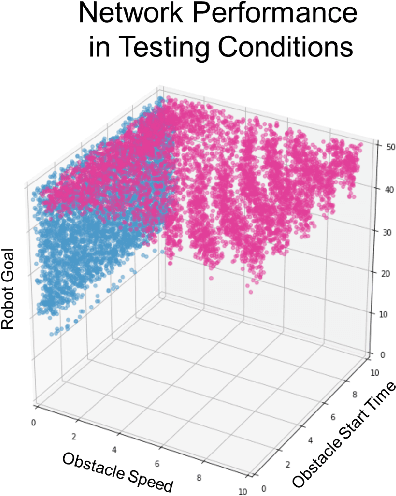
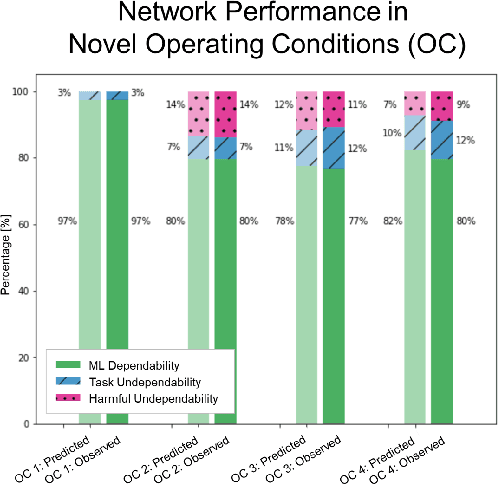
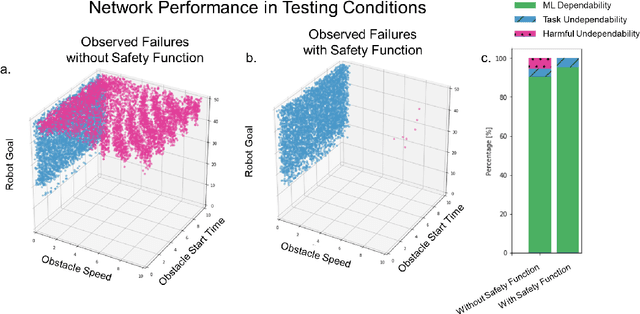
Neural Networks are being integrated into safety critical systems, e.g., perception systems for autonomous vehicles, which require trained networks to perform safely in novel scenarios. It is challenging to verify neural networks because their decisions are not explainable, they cannot be exhaustively tested, and finite test samples cannot capture the variation across all operating conditions. Existing work seeks to train models robust to new scenarios via domain adaptation, style transfer, or few-shot learning. But these techniques fail to predict how a trained model will perform when the operating conditions differ from the testing conditions. We propose a metric, Machine Learning (ML) Dependability, that measures the network's probability of success in specified operating conditions which need not be the testing conditions. In addition, we propose the metrics Task Undependability and Harmful Undependability to distinguish network failures by their consequences. We evaluate the performance of a Neural Network agent trained using Reinforcement Learning in a simulated robot manipulation task. Our results demonstrate that we can accurately predict the ML Dependability, Task Undependability, and Harmful Undependability for operating conditions that are significantly different from the testing conditions. Finally, we design a Safety Function, using harmful failures identified during testing, that reduces harmful failures, in one example, by a factor of 700 while maintaining a high probability of success.