 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANTouch: An Attack-Resilient Framework for Touch-based Continuous Authentication System
Oct 02, 2022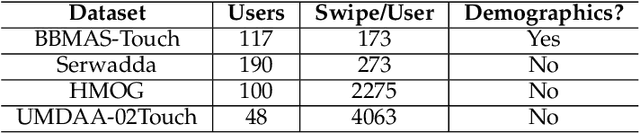
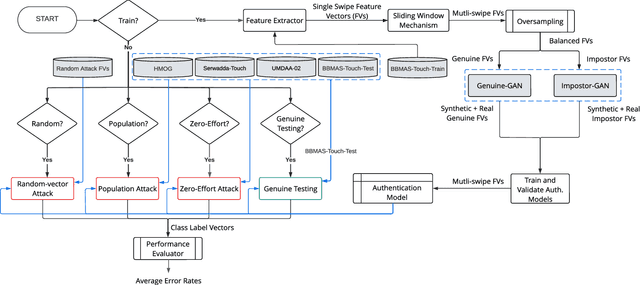
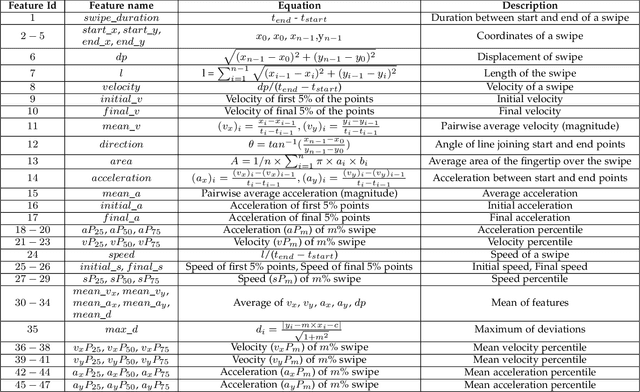
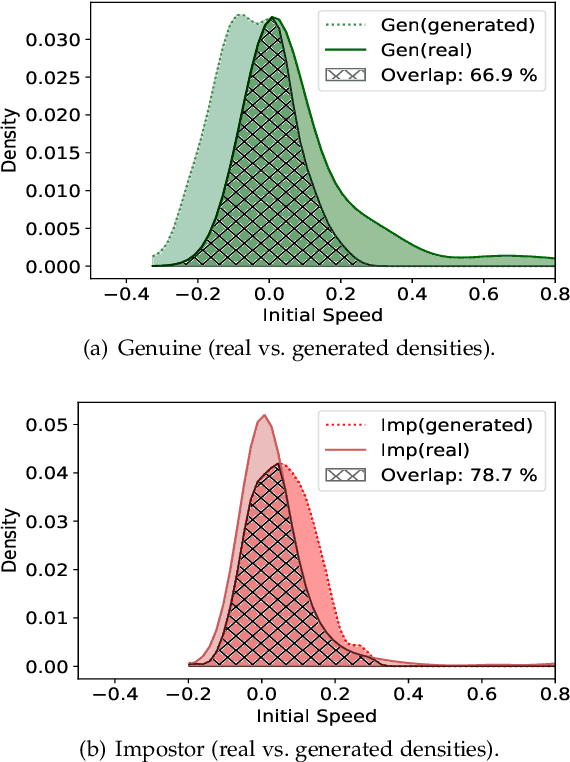
Previous studies have shown that commonly studied (vanilla) implementations of touch-based continuous authentication systems (V-TCAS) are susceptible to active adversarial attempts. This study presents a novel Generative Adversarial Network assisted TCAS (G-TCAS) framework and compares it to the V-TCAS under three active adversarial environments viz. Zero-effort, Population, and Random-vector. The Zero-effort environment was implemented in two variations viz. Zero-effort (same-dataset) and Zero-effort (cross-dataset). The first involved a Zero-effort attack from the same dataset, while the second used three different datasets. G-TCAS showed more resilience than V-TCAS under the Population and Random-vector, the more damaging adversarial scenarios than the Zero-effort. On average, the increase in the false accept rates (FARs) for V-TCAS was much higher (27.5% and 21.5%) than for G-TCAS (14% and 12.5%) for Population and Random-vector attacks, respectively. Moreover, we performed a fairness analysis of TCAS for different genders and found TCAS to be fair across genders. The findings suggest that we should evaluate TCAS under active adversarial environments and affirm the usefulness of GANs in the TCAS pipeline.
Defending Touch-based Continuous Authentication Systems from Active Adversaries Using Generative Adversarial Networks
Jun 15, 2021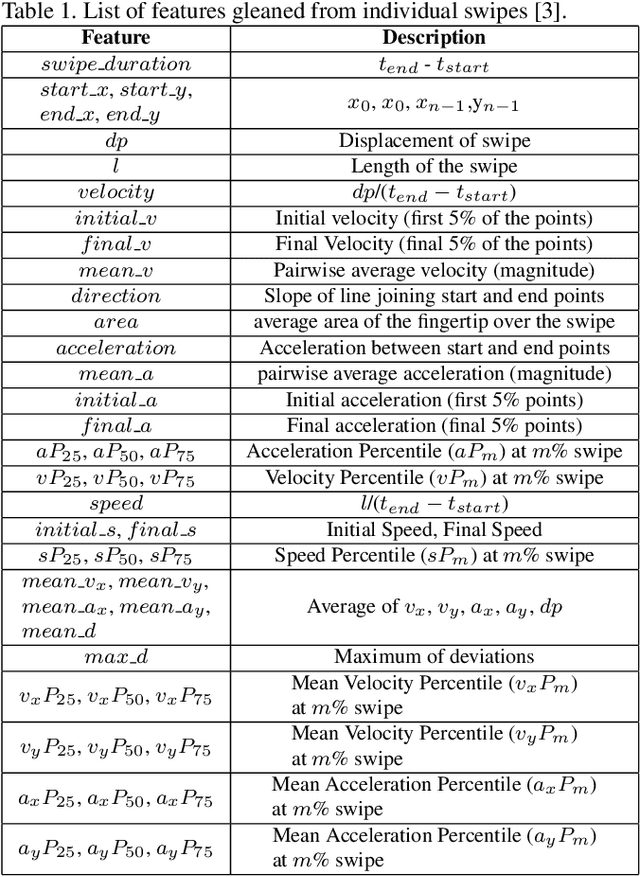
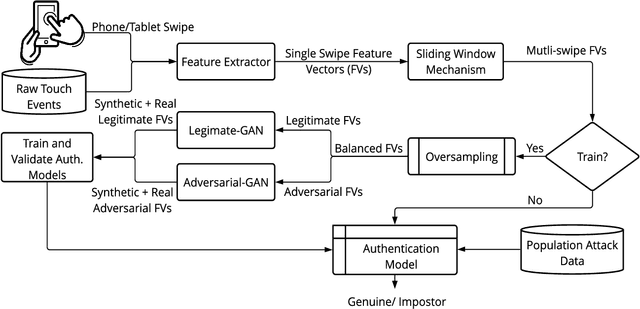
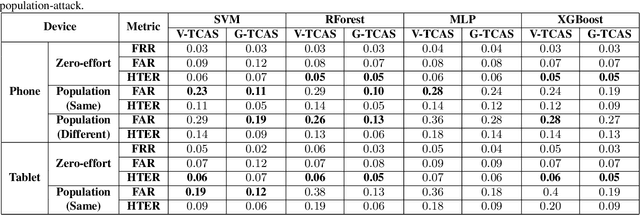

Previous studies have demonstrated that commonly studied (vanilla) touch-based continuous authentication systems (V-TCAS) are susceptible to population attack. This paper proposes a novel Generative Adversarial Network assisted TCAS (G-TCAS) framework, which showed more resilience to the population attack. G-TCAS framework was tested on a dataset of 117 users who interacted with a smartphone and tablet pair. On average, the increase in the false accept rates (FARs) for V-TCAS was much higher (22%) than G-TCAS (13%) for the smartphone. Likewise, the increase in the FARs for V-TCAS was 25% compared to G-TCAS (6%) for the tablet.
On the Inference of Soft Biometrics from Typing Patterns Collected in a Multi-device Environment
Jun 16, 2020
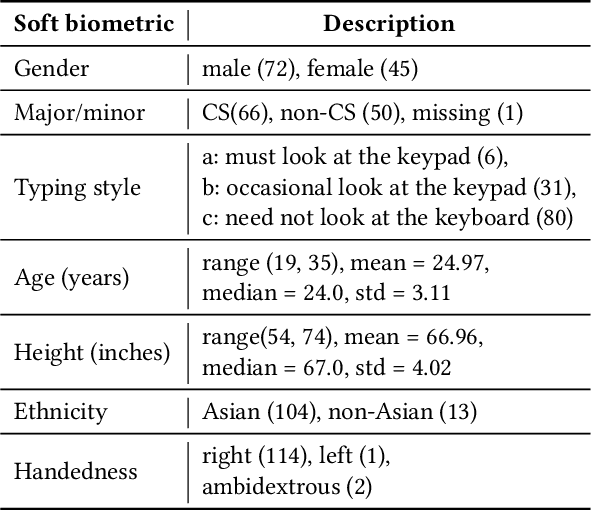
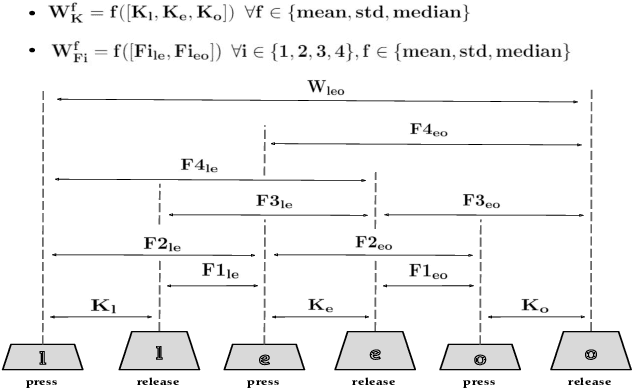
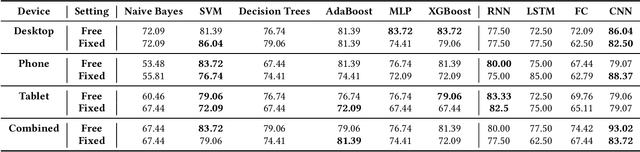
In this paper, we study the inference of gender, major/minor (computer science, non-computer science), typing style, age, and height from the typing patterns collected from 117 individuals in a multi-device environment. The inference of the first three identifiers was considered as classification tasks, while the rest as regression tasks. For classification tasks, we benchmark the performance of six classical machine learning (ML) and four deep learning (DL) classifiers. On the other hand, for regression tasks, we evaluated three ML and four DL-based regressors. The overall experiment consisted of two text-entry (free and fixed) and four device (Desktop, Tablet, Phone, and Combined) configurations. The best arrangements achieved accuracies of 96.15%, 93.02%, and 87.80% for typing style, gender, and major/minor, respectively, and mean absolute errors of 1.77 years and 2.65 inches for age and height, respectively. The results are promising considering the variety of application scenarios that we have listed in this work.