 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Simple Regret Minimization
Feb 25, 2022
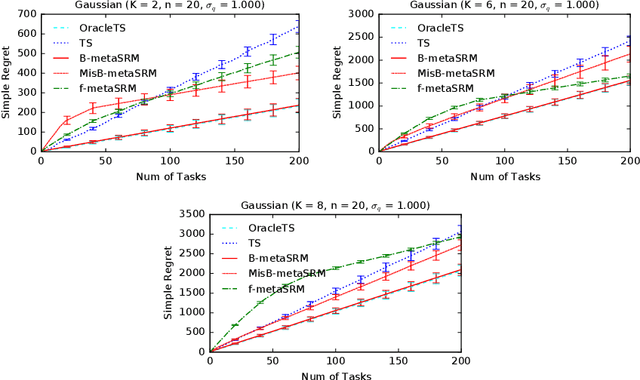
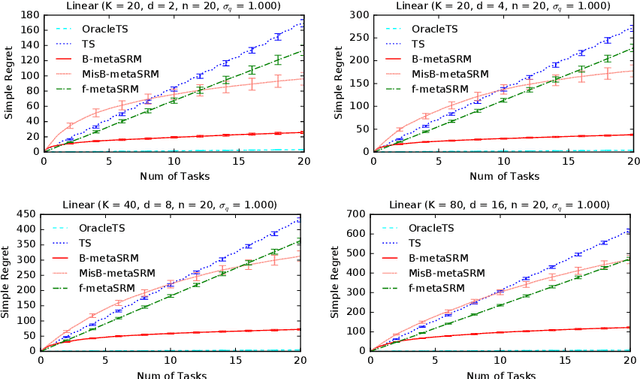
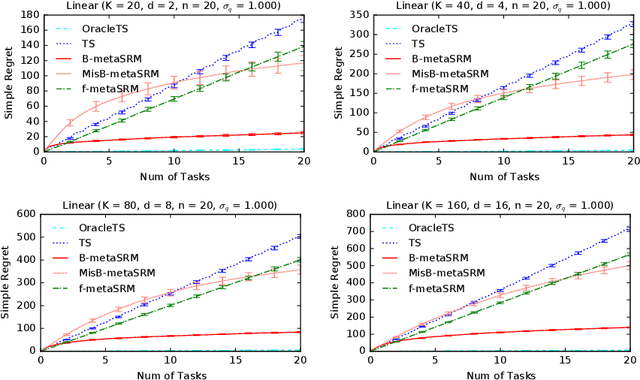
We develop a meta-learning framework for simple regret minimization in bandits. In this framework, a learning agent interacts with a sequence of bandit tasks, which are sampled i.i.d.\ from an unknown prior distribution, and learns its meta-parameters to perform better on future tasks. We propose the first Bayesian and frequentist algorithms for this meta-learning problem. The Bayesian algorithm has access to a prior distribution over the meta-parameters and its meta simple regret over $m$ bandit tasks with horizon $n$ is mere $\tilde{O}(m / \sqrt{n})$. This is while we show that the meta simple regret of the frequentist algorithm is $\tilde{O}(\sqrt{m} n + m/ \sqrt{n})$, and thus, worse. However, the algorithm is more general, because it does not need a prior distribution over the meta-parameters, and is easier to implement for various distributions. We instantiate our algorithms for several classes of bandit problems. Our algorithms are general and we complement our theory by evaluating them empirically in several environments.