 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Viewer Attention During Online Ads
Apr 08, 2025Nowadays, video ads spread through numerous online platforms, and are being watched by millions of viewers worldwide. Big brands gauge the liking and purchase intent of their new ads, by analyzing the facial responses of viewers recruited online to watch the ads from home or work. Although this approach captures naturalistic responses, it is susceptible to distractions inherent in the participants' environments, such as a movie playing on TV, a colleague speaking, or mobile notifications. Inattentive participants should get flagged and eliminated to avoid skewing the ad-testing process. In this paper we introduce an architecture for monitoring viewer attention during online ads. Leveraging two behavior analysis toolkits; AFFDEX 2.0 and SmartEye SDK, we extract low-level facial features encompassing facial expressions, head pose, and gaze direction. These features are then combined to extract high-level features that include estimated gaze on the screen plane, yawning, speaking, etc -- this enables the identification of four primary distractors; off-screen gaze, drowsiness, speaking, and unattended screen. Our architecture tailors the gaze settings according to the device type (desktop or mobile). We validate our architecture first on datasets annotated for specific distractors, and then on a real-world ad testing dataset with various distractors. The proposed architecture shows promising results in detecting distraction across both desktop and mobile devices.
PainNet: Statistical Relation Network with Episode-Based Training for Pain Estimation
Apr 08, 2025



Despite the span in estimating pain from facial expressions, limited works have focused on estimating the sequence-level pain, which is reported by patients and used commonly in clinics. In this paper, we introduce a novel Statistical Relation Network, referred to as PainNet, designed for the estimation of the sequence-level pain. PainNet employs two key modules, the embedding and the relation modules, for comparing pairs of pain videos, and producing relation scores indicating if each pair belongs to the same pain category or not. At the core of the embedding module is a statistical layer mounted on the top of a RNN for extracting compact video-level features. The statistical layer is implemented as part of the deep architecture. Doing so, allows combining multiple training stages used in previous research, into a single end-to-end training stage. PainNet is trained using the episode-based training scheme, which involves comparing a query video with a set of videos representing the different pain categories. Experimental results show the benefit of using the statistical layer and the episode-based training in the proposed model. Furthermore, PainNet outperforms the state-of-the-art results on self-reported pain estimation.
Automatic Detection of Sentimentality from Facial Expressions
Sep 11, 2022


Emotion recognition has received considerable attention from the Computer Vision community in the last 20 years. However, most of the research focused on analyzing the six basic emotions (e.g. joy, anger, surprise), with a limited work directed to other affective states. In this paper, we tackle sentimentality (strong feeling of heartwarming or nostalgia), a new emotional state that has few works in the literature, and no guideline defining its facial markers. To this end, we first collect a dataset of 4.9K videos of participants watching some sentimental and non-sentimental ads, and then we label the moments evoking sentimentality in the ads. Second, we use the ad-level labels and the facial Action Units (AUs) activation across different frames for defining some weak frame-level sentimentality labels. Third, we train a Multilayer Perceptron (MLP) using the AUs activation for sentimentality detection. Finally, we define two new ad-level metrics for evaluating our model performance. Quantitative and qualitative results show promising results for sentimentality detection. To the best of our knowledge this is the first work to address the problem of sentimentality detection.
AFFDEX 2.0: A Real-Time Facial Expression Analysis Toolkit
Feb 24, 2022

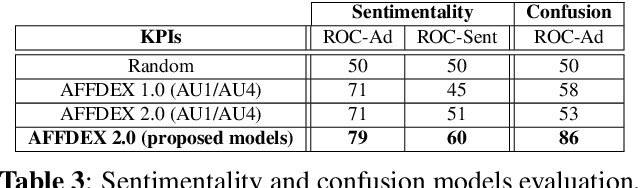

In this paper we introduce AFFDEX 2.0 - a toolkit for analyzing facial expressions in the wild, that is, it is intended for users aiming to; a) estimate the 3D head pose, b) detect facial Action Units (AUs), c) recognize basic emotions and 2 new emotional states (sentimentality and confusion), and d) detect high-level expressive metrics like blink and attention. AFFDEX 2.0 models are mainly based on Deep Learning, and are trained using a large-scale naturalistic dataset consisting of thousands of participants from different demographic groups. AFFDEX 2.0 is an enhanced version of our previous toolkit [1], that is capable of tracking efficiently faces at more challenging conditions, detecting more accurately facial expressions, and recognizing new emotional states (sentimentality and confusion). AFFDEX 2.0 can process multiple faces in real time, and is working across the Windows and Linux platforms.
Choose Settings Carefully: Comparing Action Unit detection at Different Settings Using a Large-Scale Dataset
Nov 16, 2021
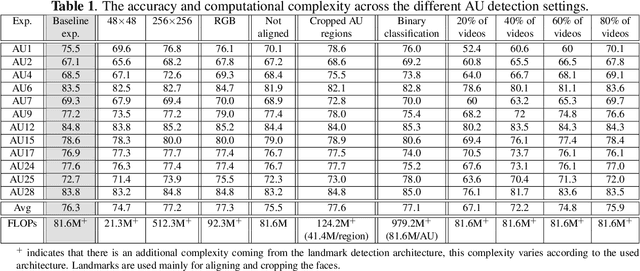
In this paper, we investigate the impact of some of the commonly used settings for (a) preprocessing face images, and (b) classification and training, on Action Unit (AU) detection performance and complexity. We use in our investigation a large-scale dataset, consisting of ~55K videos collected in the wild for participants watching commercial ads. The preprocessing settings include scaling the face to a fixed resolution, changing the color information (RGB to gray-scale), aligning the face, and cropping AU regions, while the classification and training settings include the kind of classifier (multi-label vs. binary) and the amount of data used for training models. To the best of our knowledge, no work had investigated the effect of those settings on AU detection. In our analysis we use CNNs as our baseline classification model.
Which CNNs and Training Settings to Choose for Action Unit Detection? A Study Based on a Large-Scale Dataset
Nov 16, 2021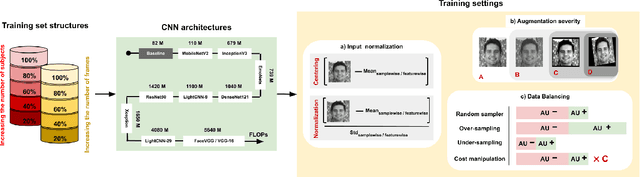
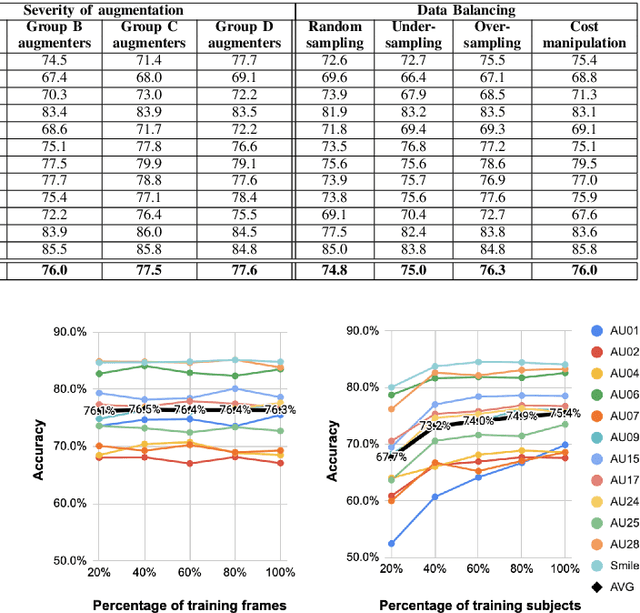
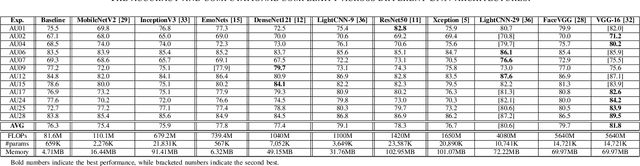
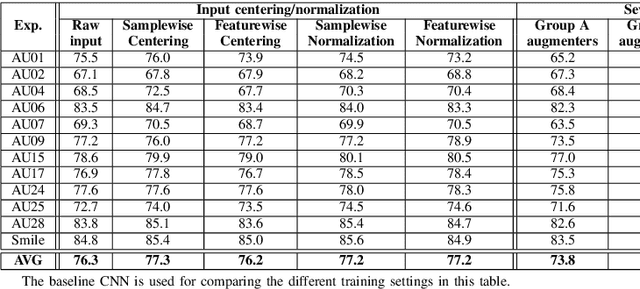
In this paper we explore the influence of some frequently used Convolutional Neural Networks (CNNs), training settings, and training set structures, on Action Unit (AU) detection. Specifically, we first compare 10 different shallow and deep CNNs in AU detection. Second, we investigate how the different training settings (i.e. centering/normalizing the inputs, using different augmentation severities, and balancing the data) impact the performance in AU detection. Third, we explore the effect of increasing the number of labelled subjects and frames in the training set on the AU detection performance. These comparisons provide the research community with useful tips about the choice of different CNNs and training settings in AU detection. In our analysis, we use a large-scale naturalistic dataset, consisting of ~55K videos captured in the wild. To the best of our knowledge, there is no work that had investigated the impact of such settings on a large-scale AU dataset.