 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Temperature and Rainfall in Bangladesh using Long Short Term Memory Recurrent Neural Networks
Oct 22, 2020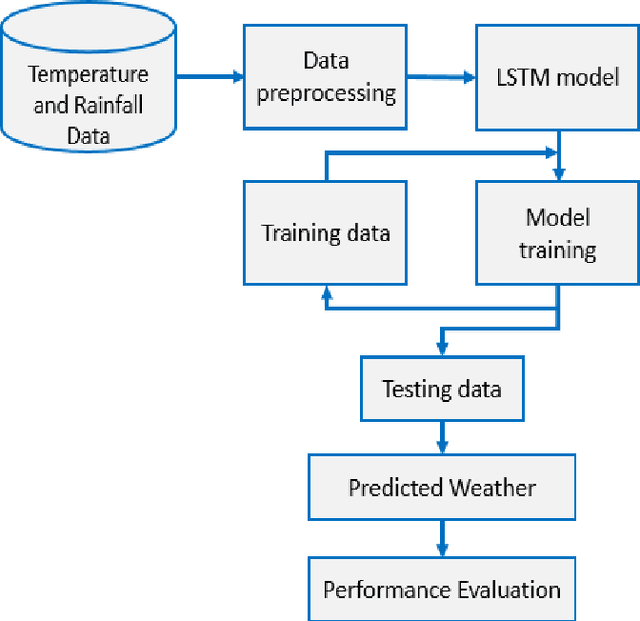
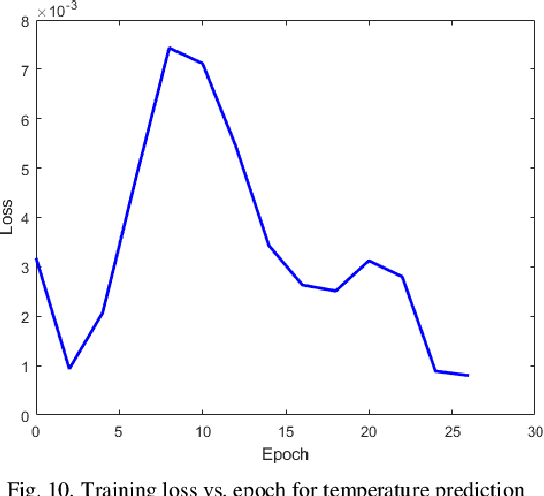
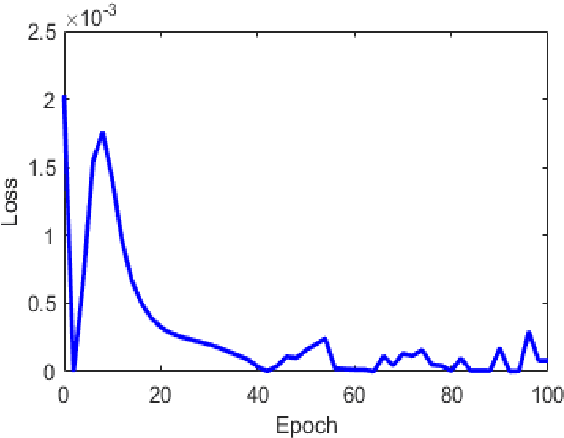
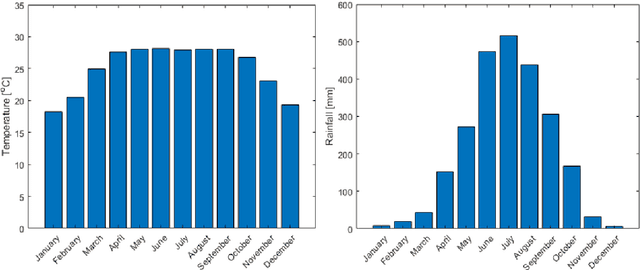
Temperature and rainfall have a significant impact on economic growth as well as the outbreak of seasonal diseases in a region. In spite of that inadequate studies have been carried out for analyzing the weather pattern of Bangladesh implementing the artificial neural network. Therefore, in this study, we are implementing a Long Short-term Memory (LSTM) model to forecast the month-wise temperature and rainfall by analyzing 115 years (1901-2015) of weather data of Bangladesh. The LSTM model has shown a mean error of -0.38oC in case of predicting the month-wise temperature for 2 years and -17.64mm in case of predicting the rainfall. This prediction model can help to understand the weather pattern changes as well as studying seasonal diseases of Bangladesh whose outbreaks are dependent on regional temperature and/or rainfall.
Deep Convolutional Neural Networks Model-based Brain Tumor Detection in Brain MRI Images
Oct 03, 2020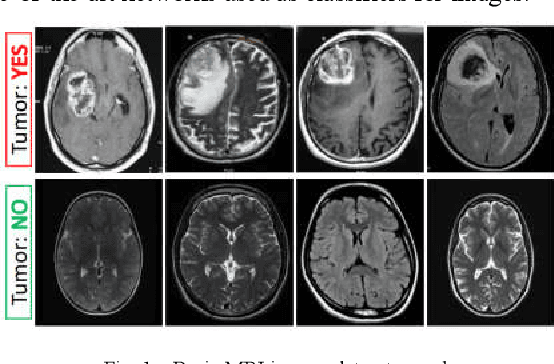
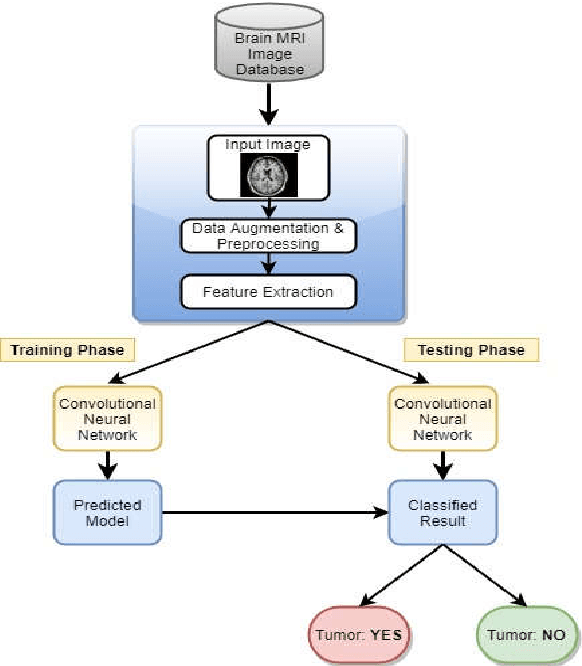
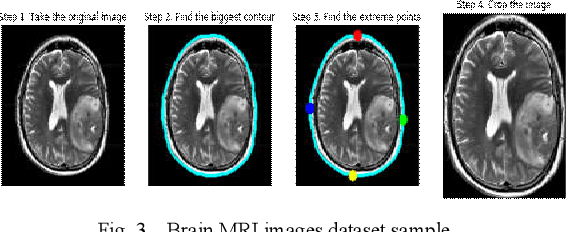
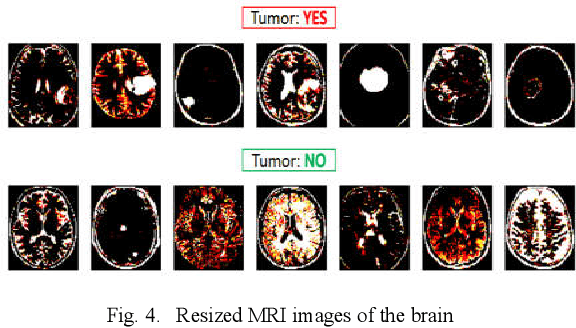
Diagnosing Brain Tumor with the aid of Magnetic Resonance Imaging (MRI) has gained enormous prominence over the years, primarily in the field of medical science. Detection and/or partitioning of brain tumors solely with the aid of MR imaging is achieved at the cost of immense time and effort and demands a lot of expertise from engaged personnel. This substantiates the necessity of fabricating an autonomous model brain tumor diagnosis. Our work involves implementing a deep convolutional neural network (DCNN) for diagnosing brain tumors from MR images. The dataset used in this paper consists of 253 brain MR images where 155 images are reported to have tumors. Our model can single out the MR images with tumors with an overall accuracy of 96%. The model outperformed the existing conventional methods for the diagnosis of brain tumor in the test dataset (Precision = 0.93, Sensitivity = 1.00, and F1-score = 0.97). Moreover, the proposed model's average precision-recall score is 0.93, Cohen's Kappa 0.91, and AUC 0.95. Therefore, the proposed model can help clinical experts verify whether the patient has a brain tumor and, consequently, accelerate the treatment procedure.
Non-Intrusive Electrical Appliances Monitoring and Classification using K-Nearest Neighbors
Nov 22, 2019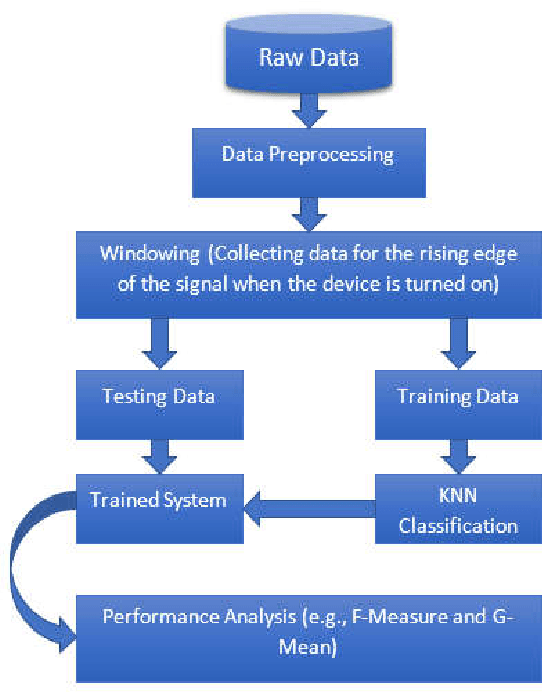
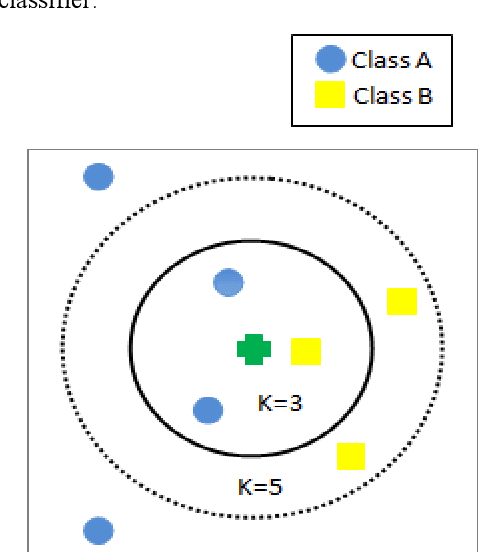
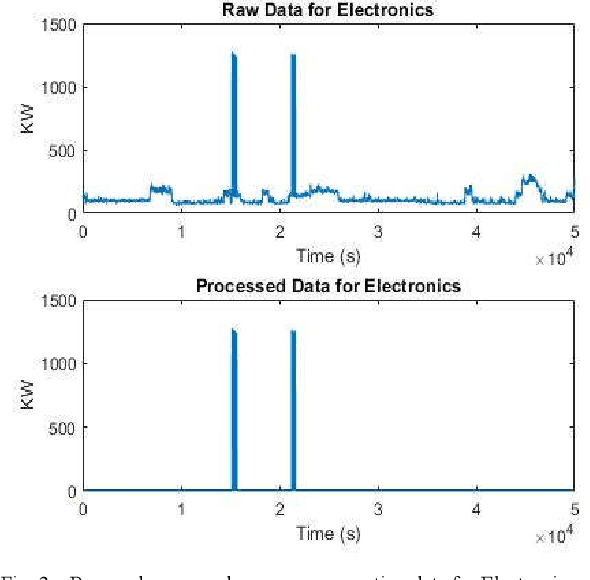
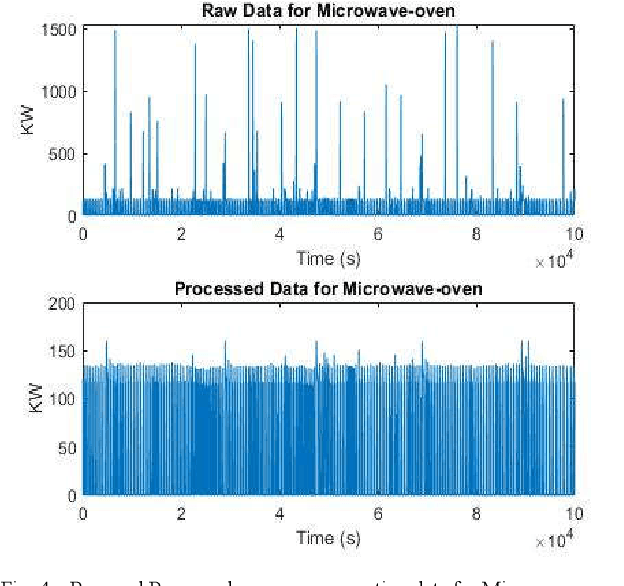
Non-Intrusive Load Monitoring (NILM) is the method of detecting an individual device's energy signal from an aggregated energy consumption signature [1]. As existing energy meters provide very little to no information regarding the energy consumption of individual appliances apart from the aggregated power rating, the spotting of individual appliances' energy usages by NILM will not only provide consumers the feedback of appliance-specific energy usage but also lead to the changes of their consumption behavior which facilitate energy conservation. B Neenan et al. [2] have demonstrated that direct individual appliance-specific energy usage signals lead to consumers' behavioral changes which improves energy efficiency by as much as 15%. Upon disaggregation of an energy signal, the signal needs to be classified according to the appropriate appliance. Hence, the goal of this paper is to disaggregate total energy consumption data to individual appliance signature and then classify appliance-specific energy loads using a prominent supervised classification method known as K-Nearest Neighbors (KNN). To perform this operation we have used a publicly accessible dataset of power signals from several houses known as the REDD dataset. Before applying KNN, data is preprocessed for each device. Then KNN is applied to check whether their energy consumption signature is separable or not. KNN is applied with K=5.
Study and Observation of the Variation of Accuracies of KNN, SVM, LMNN, ENN Algorithms on Eleven Different Datasets from UCI Machine Learning Repository
Sep 22, 2018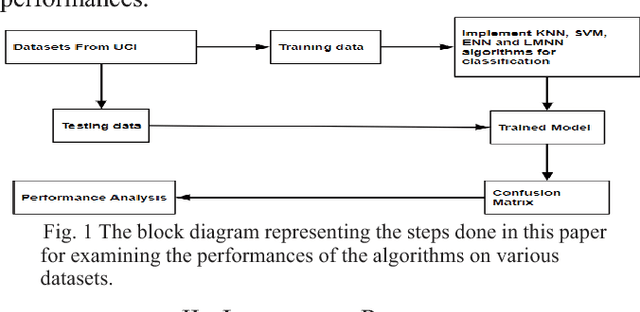

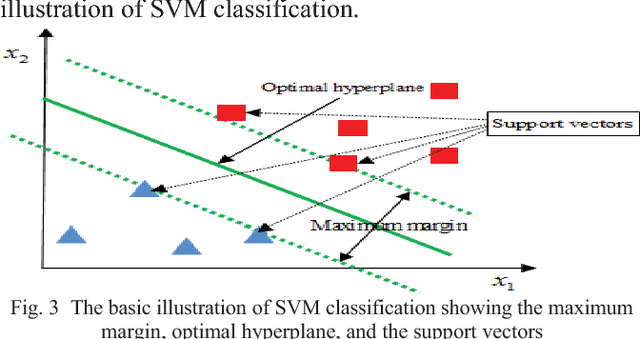
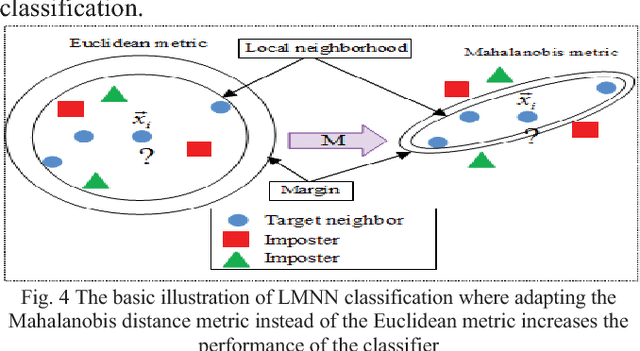
Machine learning qualifies computers to assimilate with data, without being solely programmed [1, 2]. Machine learning can be classified as supervised and unsupervised learning. In supervised learning, computers learn an objective that portrays an input to an output hinged on training input-output pairs [3]. Most efficient and widely used supervised learning algorithms are K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Large Margin Nearest Neighbor (LMNN), and Extended Nearest Neighbor (ENN). The main contribution of this paper is to implement these elegant learning algorithms on eleven different datasets from the UCI machine learning repository to observe the variation of accuracies for each of the algorithms on all datasets. Analyzing the accuracy of the algorithms will give us a brief idea about the relationship of the machine learning algorithms and the data dimensionality. All the algorithms are developed in Matlab. Upon such accuracy observation, the comparison can be built among KNN, SVM, LMNN, and ENN regarding their performances on each dataset.
Study and Observation of the Variations of Accuracies for Handwritten Digits Recognition with Various Hidden Layers and Epochs using Convolutional Neural Network
Sep 22, 2018
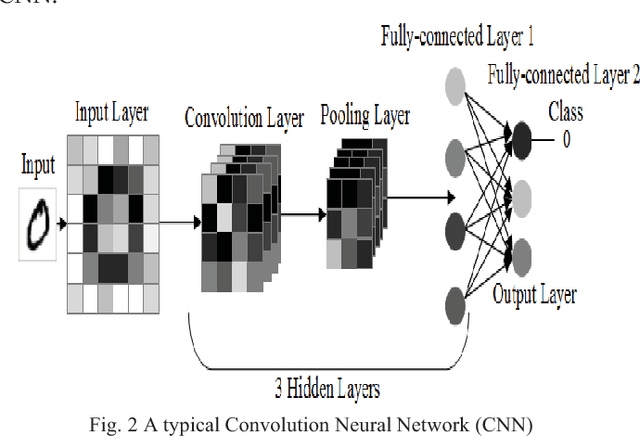
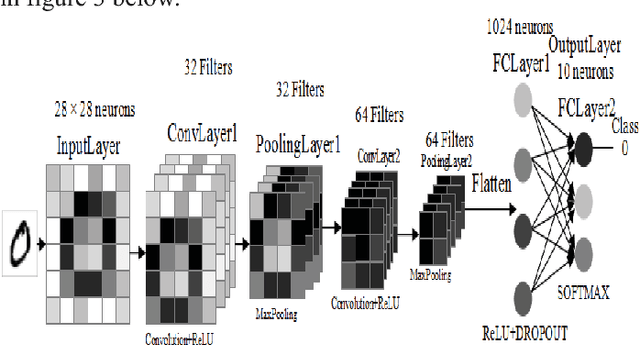
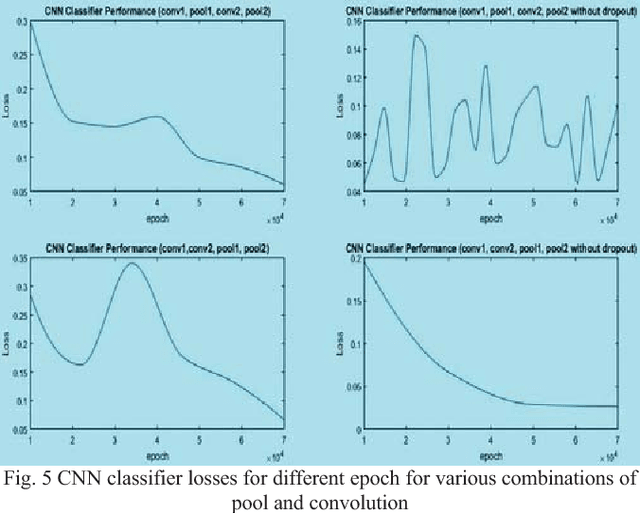
Nowadays, deep learning can be employed to a wide ranges of fields including medicine, engineering, etc. In deep learning, Convolutional Neural Network (CNN) is extensively used in the pattern and sequence recognition, video analysis, natural language processing, spam detection, topic categorization, regression analysis, speech recognition, image classification, object detection, segmentation, face recognition, robotics, and control. The benefits associated with its near human level accuracies in large applications lead to the growing acceptance of CNN in recent years. The primary contribution of this paper is to analyze the impact of the pattern of the hidden layers of a CNN over the overall performance of the network. To demonstrate this influence, we applied neural network with different layers on the Modified National Institute of Standards and Technology (MNIST) dataset. Also, is to observe the variations of accuracies of the network for various numbers of hidden layers and epochs and to make comparison and contrast among them. The system is trained utilizing stochastic gradient and backpropagation algorithm and tested with feedforward algorithm.
Study and Observation of the Variations of Accuracies for Handwritten Digits Recognition with Various Hidden Layers and Epochs using Neural Network Algorithm
Sep 22, 2018
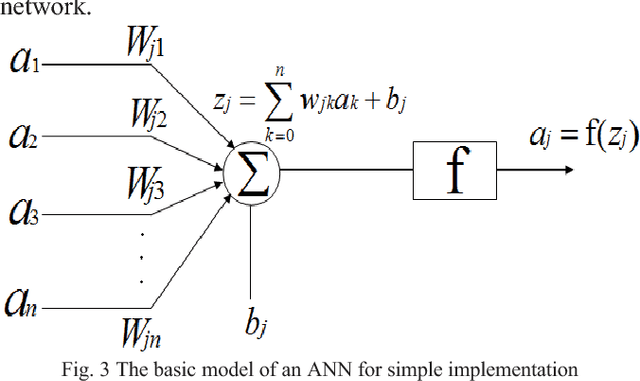
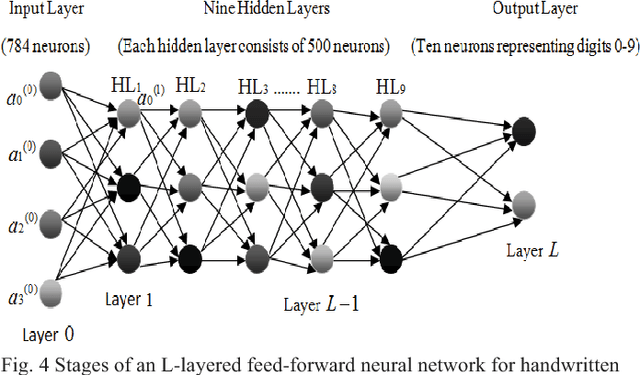
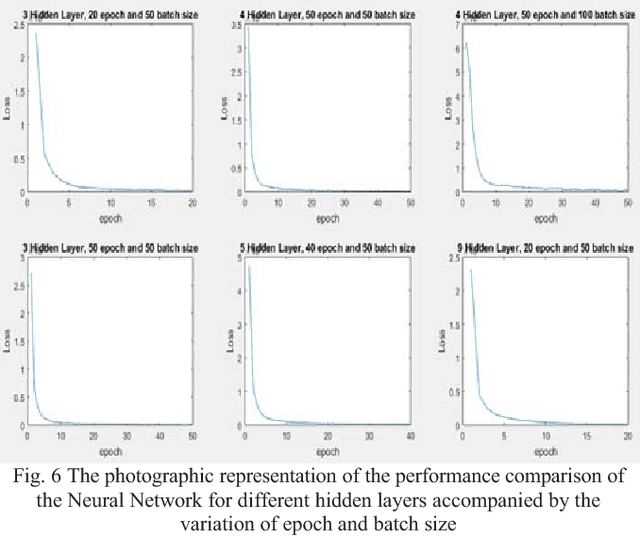
In recent days, Artificial Neural Network (ANN) can be applied to a vast majority of fields including business, medicine, engineering, etc. The most popular areas where ANN is employed nowadays are pattern and sequence recognition, novelty detection, character recognition, regression analysis, speech recognition, image compression, stock market prediction, Electronic nose, security, loan applications, data processing, robotics, and control. The benefits associated with its broad applications leads to increasing popularity of ANN in the era of 21st Century. ANN confers many benefits such as organic learning, nonlinear data processing, fault tolerance, and self-repairing compared to other conventional approaches. The primary objective of this paper is to analyze the influence of the hidden layers of a neural network over the overall performance of the network. To demonstrate this influence, we applied neural network with different layers on the MNIST dataset. Also, another goal is to observe the variations of accuracies of ANN for different numbers of hidden layers and epochs and to compare and contrast among them.
ADBSCAN: Adaptive Density-Based Spatial Clustering of Applications with Noise for Identifying Clusters with Varying Densities
Sep 22, 2018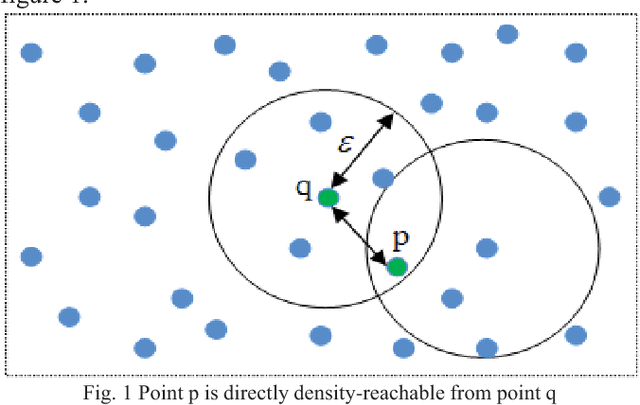
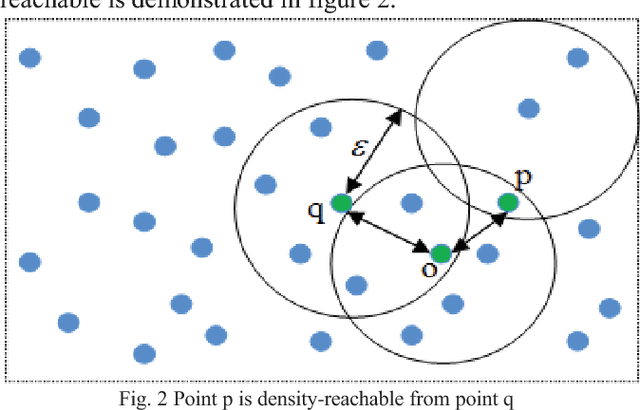
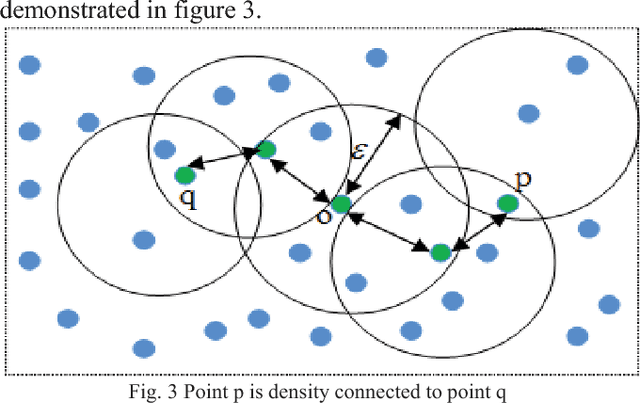
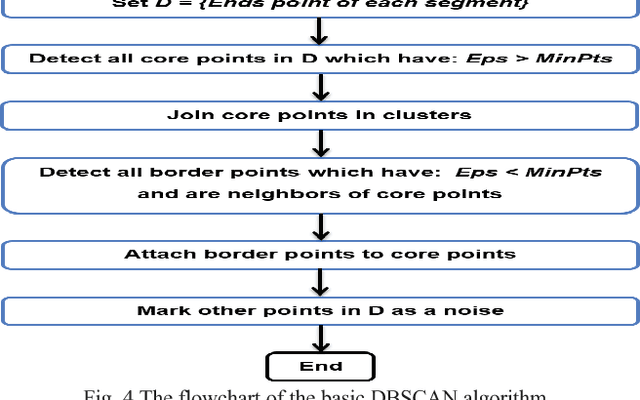
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm which has the high-performance rate for dataset where clusters have the constant density of data points. One of the significant attributes of this algorithm is noise cancellation. However, DBSCAN demonstrates reduced performances for clusters with different densities. Therefore, in this paper, an adaptive DBSCAN is proposed which can work significantly well for identifying clusters with varying densities.
Implementation of Fuzzy C-Means and Possibilistic C-Means Clustering Algorithms, Cluster Tendency Analysis and Cluster Validation
Sep 22, 2018
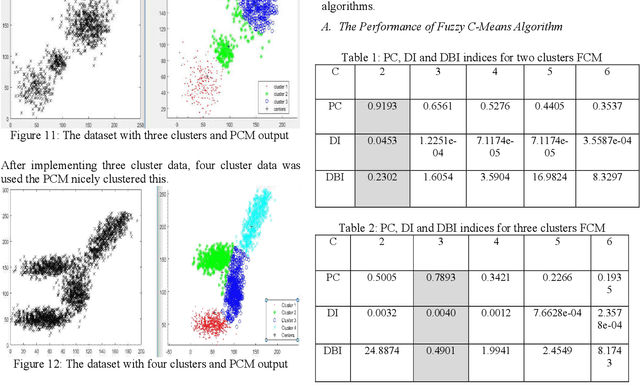


In this paper, several two-dimensional clustering scenarios are given. In those scenarios, soft partitioning clustering algorithms (Fuzzy C-means (FCM) and Possibilistic c-means (PCM)) are applied. Afterward, VAT is used to investigate the clustering tendency visually, and then in order of checking cluster validation, three types of indices (e.g., PC, DI, and DBI) were used. After observing the clustering algorithms, it was evident that each of them has its limitations; however, PCM is more robust to noise than FCM as in case of FCM a noise point has to be considered as a member of any of the cluster.