 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere2Start: Leveraging initial States for Robust and Sample-Efficient Reinforcement Learning
Nov 25, 2023The reinforcement learning algorithms that focus on how to compute the gradient and choose next actions, are effectively improved the performance of the agents. However, these algorithms are environment-agnostic. This means that the algorithms did not use the knowledge that has been captured by trajectory. This poses that the algorithms should sample many trajectories to train the model. By considering the essence of environment and how much the agent learn from each scenario in that environment, the strategy of the learning procedure can be changed. The strategy retrieves more informative trajectories, so the agent can learn with fewer trajectory sample. We propose Where2Start algorithm that selects the initial state so that the agent has more instability in vicinity of that state. We show that this kind of selection decreases number of trajectories that should be sampled that the agent reach to acceptable reward. Our experiments shows that Where2Start can improve sample efficiency up to 8 times. Also Where2Start can combined with most of state-of-the-art algorithms and improve that robustness and sample efficiency significantly.
Adaptive Low-Rank Regularization with Damping Sequences to Restrict Lazy Weights in Deep Networks
Jun 17, 2021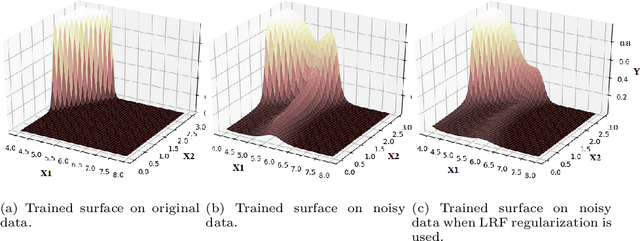
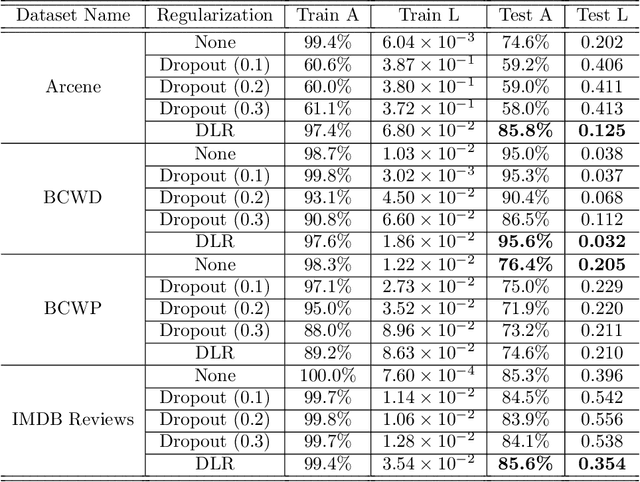
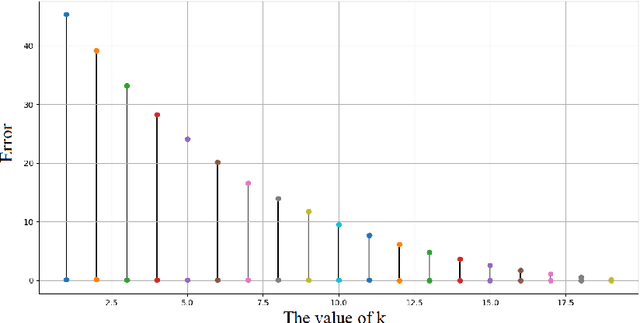
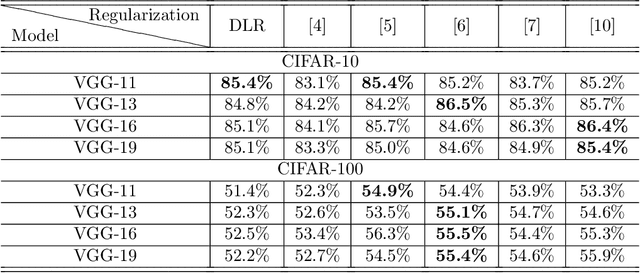
Overfitting is one of the critical problems in deep neural networks. Many regularization schemes try to prevent overfitting blindly. However, they decrease the convergence speed of training algorithms. Adaptive regularization schemes can solve overfitting more intelligently. They usually do not affect the entire network weights. This paper detects a subset of the weighting layers that cause overfitting. The overfitting recognizes by matrix and tensor condition numbers. An adaptive regularization scheme entitled Adaptive Low-Rank (ALR) is proposed that converges a subset of the weighting layers to their Low-Rank Factorization (LRF). It happens by minimizing a new Tikhonov-based loss function. ALR also encourages lazy weights to contribute to the regularization when epochs grow up. It uses a damping sequence to increment layer selection likelihood in the last generations. Thus before falling the training accuracy, ALR reduces the lazy weights and regularizes the network substantially. The experimental results show that ALR regularizes the deep networks well with high training speed and low resource usage.
Adaptive Low-Rank Factorization to regularize shallow and deep neural networks
May 05, 2020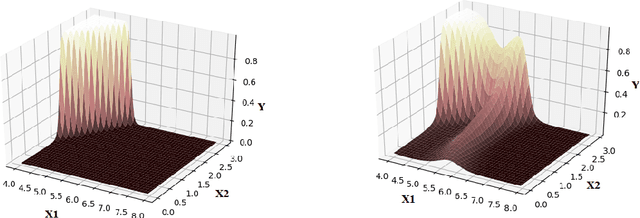
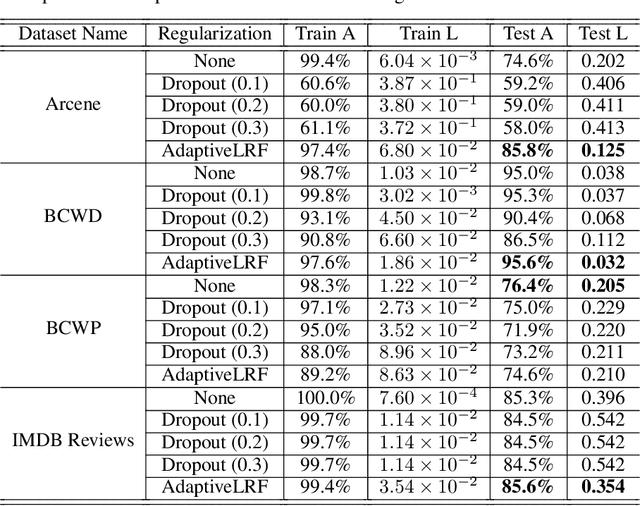
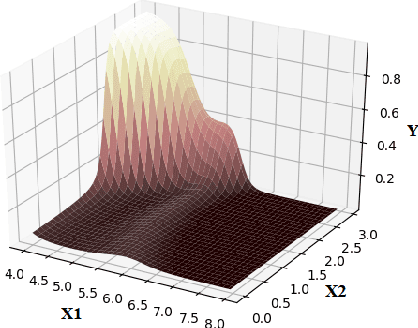
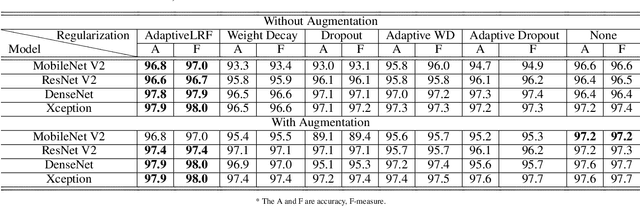
The overfitting is one of the cursing subjects in the deep learning field. To solve this challenge, many approaches were proposed to regularize the learning models. They add some hyper-parameters to the model to extend the generalization; however, it is a hard task to determine these hyper-parameters and a bad setting diverges the training process. In addition, most of the regularization schemes decrease the learning speed. Recently, Tai et al. [1] proposed low-rank tensor decomposition as a constrained filter for removing the redundancy in the convolution kernels of CNN. With a different viewpoint, we use Low-Rank matrix Factorization (LRF) to drop out some parameters of the learning model along the training process. However, this scheme similar to [1] probably decreases the training accuracy when it tries to decrease the number of operations. Instead, we use this regularization scheme adaptively when the complexity of a layer is high. The complexity of any layer can be evaluated by the nonlinear condition numbers of its learning system. The resulted method entitled "AdaptiveLRF" neither decreases the training speed nor vanishes the accuracy of the layer. The behavior of AdaptiveLRF is visualized on a noisy dataset. Then, the improvements are presented on some small-size and large-scale datasets. The preference of AdaptiveLRF on famous dropout regularizers on shallow networks is demonstrated. Also, AdaptiveLRF competes with dropout and adaptive dropout on the various deep networks including MobileNet V2, ResNet V2, DenseNet, and Xception. The best results of AdaptiveLRF on SVHN and CIFAR-10 datasets are 98%, 94.1% F-measure, and 97.9%, 94% accuracy. Finally, we state the usage of the LRF-based loss function to improve the quality of the learning model.
Regularized Deep Networks in Intelligent Transportation Systems: A Taxonomy and a Case Study
Nov 08, 2019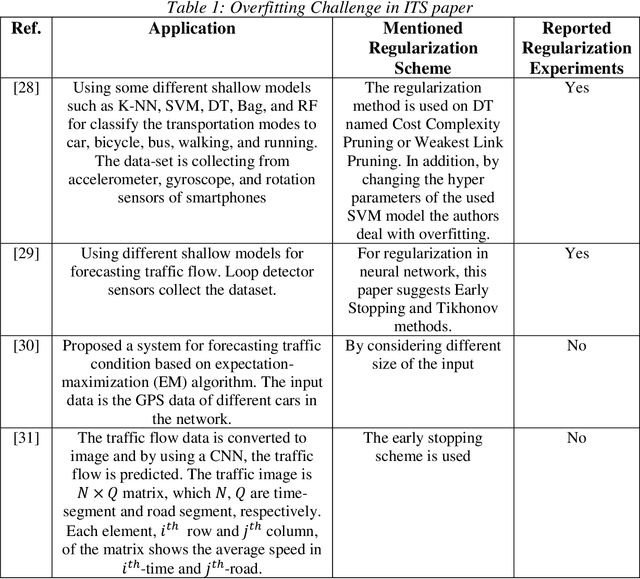
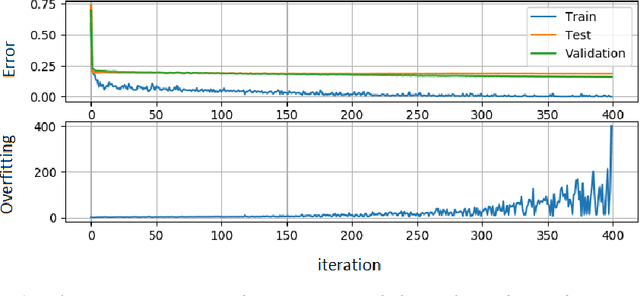
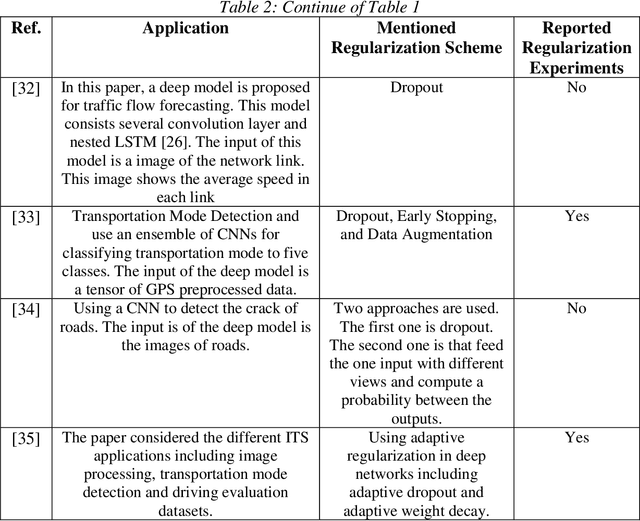
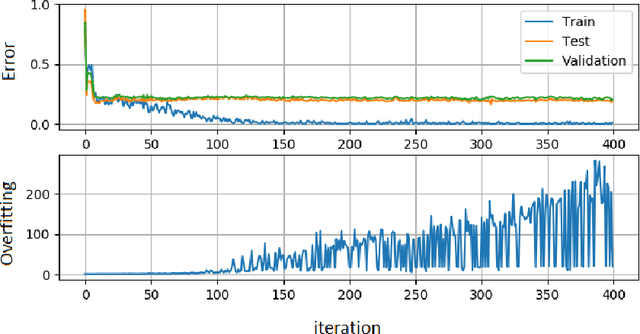
Intelligent Transportation Systems (ITS) are much correlated with data science mechanisms. Among the different correlation branches, this paper focuses on the neural network learning models. Some of the considered models are shallow and they get some user-defined features and learn the relationship, while deep models extract the necessary features before learning by themselves. Both of these paradigms are utilized in the recent intelligent transportation systems (ITS) to support decision-making by the aid of different operations such as frequent patterns mining, regression, clustering, and classification. When these learners cannot generalize the results and just memorize the training samples, they fail to support the necessities. In these cases, the testing error is bigger than the training error. This phenomenon is addressed as overfitting in the literature. Because, this issue decreases the reliability of learning systems, in ITS applications, we cannot use such over-fitted machine learning models for different tasks such as traffic prediction, the signal controlling, safety applications, emergency responses, mode detection, driving evaluation, etc. Besides, deep learning models use a great number of hyper-parameters, the overfitting in deep models is more attention. To solve this problem, the regularized learning models can be followed. The aim of this paper is to review the approaches presented to regularize the overfitting in different categories of ITS studies. Then, we give a case study on driving safety that uses a regularized version of the convolutional neural network (CNN).