 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Low-Rank Factorization to regularize shallow and deep neural networks
Paper and Code
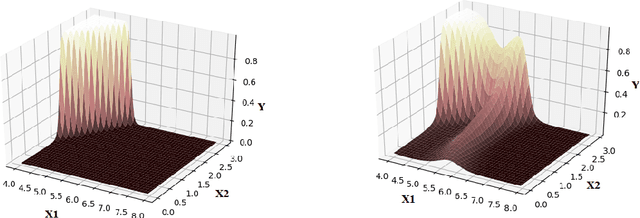
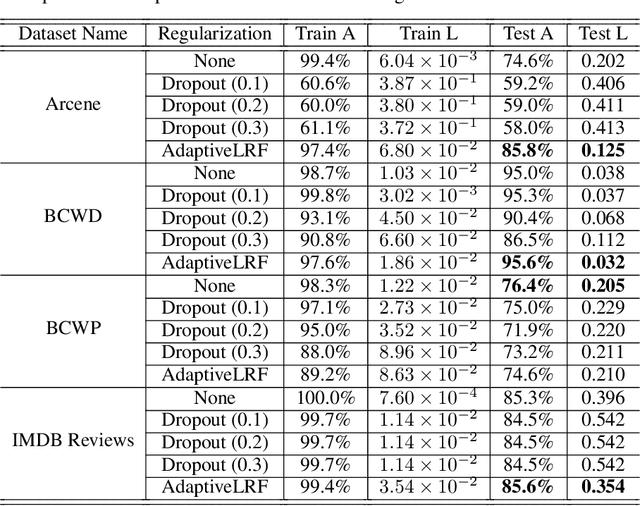
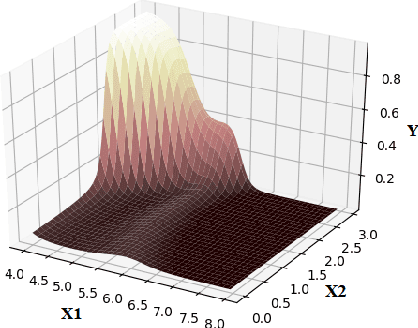
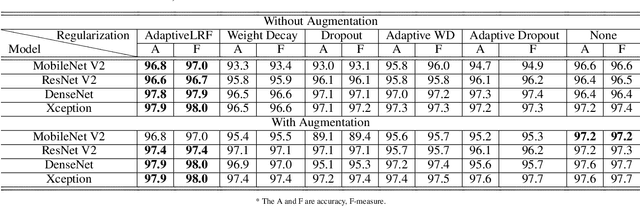
The overfitting is one of the cursing subjects in the deep learning field. To solve this challenge, many approaches were proposed to regularize the learning models. They add some hyper-parameters to the model to extend the generalization; however, it is a hard task to determine these hyper-parameters and a bad setting diverges the training process. In addition, most of the regularization schemes decrease the learning speed. Recently, Tai et al. [1] proposed low-rank tensor decomposition as a constrained filter for removing the redundancy in the convolution kernels of CNN. With a different viewpoint, we use Low-Rank matrix Factorization (LRF) to drop out some parameters of the learning model along the training process. However, this scheme similar to [1] probably decreases the training accuracy when it tries to decrease the number of operations. Instead, we use this regularization scheme adaptively when the complexity of a layer is high. The complexity of any layer can be evaluated by the nonlinear condition numbers of its learning system. The resulted method entitled "AdaptiveLRF" neither decreases the training speed nor vanishes the accuracy of the layer. The behavior of AdaptiveLRF is visualized on a noisy dataset. Then, the improvements are presented on some small-size and large-scale datasets. The preference of AdaptiveLRF on famous dropout regularizers on shallow networks is demonstrated. Also, AdaptiveLRF competes with dropout and adaptive dropout on the various deep networks including MobileNet V2, ResNet V2, DenseNet, and Xception. The best results of AdaptiveLRF on SVHN and CIFAR-10 datasets are 98%, 94.1% F-measure, and 97.9%, 94% accuracy. Finally, we state the usage of the LRF-based loss function to improve the quality of the learning model.