 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Wrote This? Zero-Shot Statistical Tests for LLM-Generated Text Detection using Finite Sample Concentration Inequalities
Jan 04, 2025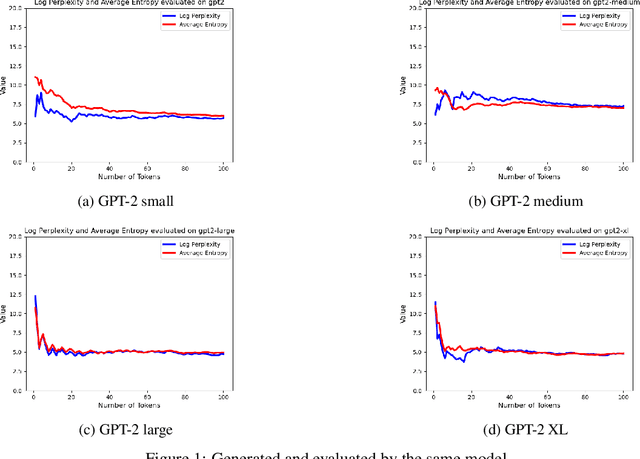
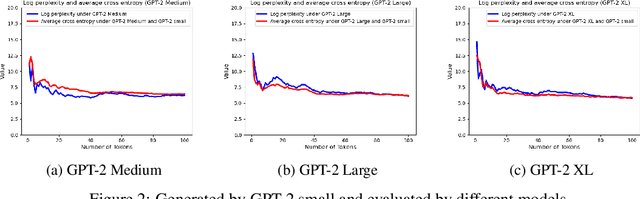
Verifying the provenance of content is crucial to the function of many organizations, e.g., educational institutions, social media platforms, firms, etc. This problem is becoming increasingly difficult as text generated by Large Language Models (LLMs) becomes almost indistinguishable from human-generated content. In addition, many institutions utilize in-house LLMs and want to ensure that external, non-sanctioned LLMs do not produce content within the institution. In this paper, we answer the following question: Given a piece of text, can we identify whether it was produced by LLM $A$ or $B$ (where $B$ can be a human)? We model LLM-generated text as a sequential stochastic process with complete dependence on history and design zero-shot statistical tests to distinguish between (i) the text generated by two different sets of LLMs $A$ (in-house) and $B$ (non-sanctioned) and also (ii) LLM-generated and human-generated texts. We prove that the type I and type II errors for our tests decrease exponentially in the text length. In designing our tests, we derive concentration inequalities on the difference between log-perplexity and the average entropy of the string under $A$. Specifically, for a given string, we demonstrate that if the string is generated by $A$, the log-perplexity of the string under $A$ converges to the average entropy of the string under $A$, except with an exponentially small probability in string length. We also show that if $B$ generates the text, except with an exponentially small probability in string length, the log-perplexity of the string under $A$ converges to the average cross-entropy of $B$ and $A$. Lastly, we present preliminary experimental results to support our theoretical results. By enabling guaranteed (with high probability) finding of the origin of harmful LLM-generated text with arbitrary size, we can help fight misinformation.
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Apr 10, 2024In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLM. We explore the methodological aspects of biasing LLMs towards specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Our approach, distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, employs Parameter-Efficient Fine-Tuning (PEFT) techniques. These techniques allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for dataset selection, annotation, and instruction tuning, and we assess its effectiveness through both quantitative and qualitative evaluations. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.