 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Impact of COVID-19 on Education by Social Network Mining
Mar 13, 2022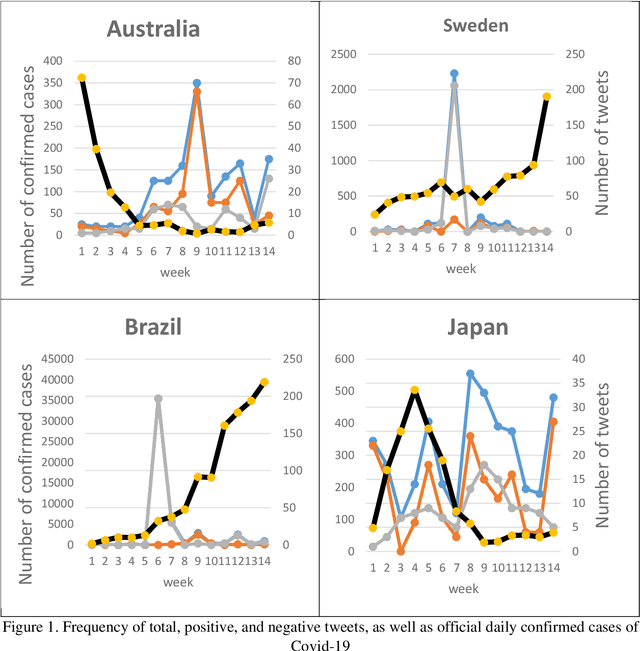
The Covid-19 virus has been one of the most discussed topics on social networks in 2020 and 2021 and has affected the classic educational paradigm, worldwide. In this research, many tweets related to the Covid-19 virus and education are considered and geo-tagged with the help of the GeoNames geographic database, which contains a large number of place names. To detect the feeling of users, sentiment analysis is performed using the RoBERTa language-based model. Finally, we obtain the trends of frequency of total, positive, and negative tweets for countries with a high number of Covid-19 confirmed cases. Investigating the results reveals a correlation between the trends of tweet frequency and the official statistic of confirmed cases for several countries.
Extracting Feelings of People Regarding COVID-19 by Social Network Mining
Oct 12, 2021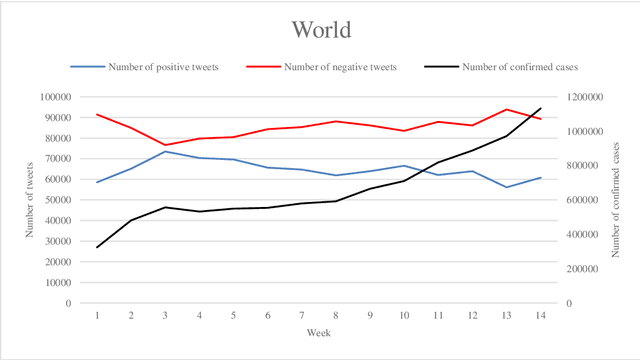
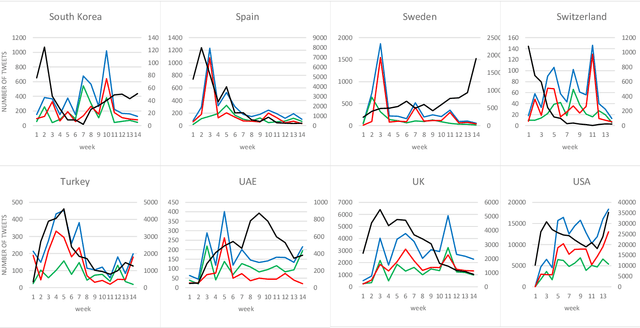
In 2020, COVID-19 became the chief concern of the world and is still reflected widely in all social networks. Each day, users post millions of tweets and comments on this subject, which contain significant implicit information about the public opinion. In this regard, a dataset of COVID-related tweets in English language is collected, which consists of more than two million tweets from March 23 to June 23 of 2020 to extract the feelings of the people in various countries in the early stages of this outbreak. To this end, first, we use a lexicon-based approach in conjunction with the GeoNames geographic database to label the tweets with their locations. Next, a method based on the recently introduced and widely cited RoBERTa model is proposed to analyze their sentimental content. After that, the trend graphs of the frequency of tweets as well as sentiments are produced for the world and the nations that were more engaged with COVID-19. Graph analysis shows that the frequency graphs of the tweets for the majority of nations are significantly correlated with the official statistics of the daily afflicted in them. Moreover, several implicit knowledge is extracted and discussed.