 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFRM3D: A Radiomics-enhanced Fused Residual Multiparametric 3D Network with Multi-Scale Feature Fusion for Glioma Characterization
Dec 27, 2025Gliomas are among the most aggressive cancers, characterized by high mortality rates and complex diagnostic processes. Existing studies on glioma diagnosis and classification often describe issues such as high variability in imaging data, inadequate optimization of computational resources, and inefficient segmentation and classification of gliomas. To address these challenges, we propose novel techniques utilizing multi-parametric MRI data to enhance tumor segmentation and classification efficiency. Our work introduces the first-ever radiomics-enhanced fused residual multiparametric 3D network (ReFRM3D) for brain tumor characterization, which is based on a 3D U-Net architecture and features multi-scale feature fusion, hybrid upsampling, and an extended residual skip mechanism. Additionally, we propose a multi-feature tumor marker-based classifier that leverages radiomic features extracted from the segmented regions. Experimental results demonstrate significant improvements in segmentation performance across the BraTS2019, BraTS2020, and BraTS2021 datasets, achieving high Dice Similarity Coefficients (DSC) of 94.04%, 92.68%, and 93.64% for whole tumor (WT), enhancing tumor (ET), and tumor core (TC) respectively in BraTS2019; 94.09%, 92.91%, and 93.84% in BraTS2020; and 93.70%, 90.36%, and 92.13% in BraTS2021.
Improving ICD coding using Chapter based Named Entities and Attentional Models
Jul 24, 2024Recent advancements in natural language processing (NLP) have led to automation in various domains. However, clinical NLP often relies on benchmark datasets that may not reflect real-world scenarios accurately. Automatic ICD coding, a vital NLP task, typically uses outdated and imbalanced datasets like MIMIC-III, with existing methods yielding micro-averaged F1 scores between 0.4 and 0.7 due to many false positives. Our research introduces an enhanced approach to ICD coding that improves F1 scores by using chapter-based named entities and attentional models. This method categorizes discharge summaries into ICD-9 Chapters and develops attentional models with chapter-specific data, eliminating the need to consider external data for code identification. For categorization, we use Chapter-IV to de-bias and influence key entities and weights without neural networks, creating accurate thresholds and providing interpretability for human validation. Post-validation, we develop attentional models for three frequent and three non-frequent codes from Chapter-IV using Bidirectional-Gated Recurrent Units (GRUs) with Attention and Transformer with Multi-head Attention architectures. The average Micro-F1 scores of 0.79 and 0.81 from these models demonstrate significant performance improvements in ICD coding.
Methods to Measure the Broncho-Arterial Ratio and Wall Thickness in the Right Lower Lobe for Defining Radiographic Reversibility of Bronchiectasis
Jul 18, 2024


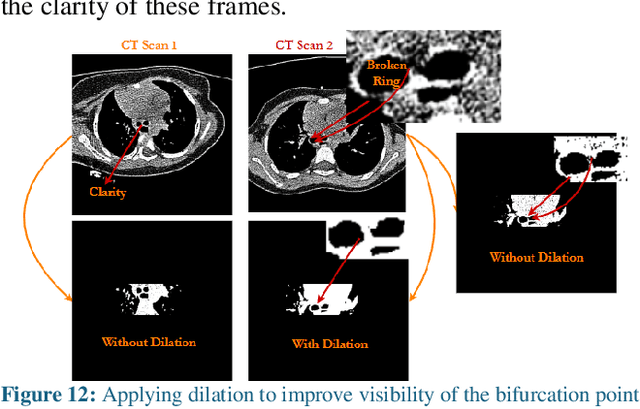
The diagnosis of bronchiectasis requires measuring abnormal bronchial dilation. It is confirmed using a chest CT scan, where the key feature is an increased broncho-arterial ratio (BAR) (>0.8 in children), often with bronchial wall thickening. Image processing methods facilitate quicker interpretation and detailed evaluations by lobes and segments. Challenges like inclined nature, oblique orientation, and partial volume effect make it difficult to obtain accurate measurements in the upper and middle lobes using the same algorithms. Therefore, accurate detection and measurement of airway and artery regions for BAR and wall thickness in each lobe require different image processing/machine learning methods. We propose methods for: 1. Separating the right lower lobe (RLL) region from full-length CT scans using the tracheal bifurcation (Carina) point as a central marker; 2. Locating the inner diameter of airways and outer diameter of arteries for BAR measurement; and 3. Measuring airway wall thickness (WT) by identifying the outer and inner diameters of airway boundaries. Analysis of 13 HRCT scans with varying thicknesses (0.67mm, 1mm, 2mm) shows the tracheal bifurcation frame can be detected accurately, with a deviation of +/- 2 frames in some cases. A Windows app was developed for measuring inner airway diameter, artery diameter, BAR, and wall thickness, allowing users to draw boundaries around visible BA pairs in the RLL region. Measurements of 10 BA pairs revealed accurate results comparable to those of a human reader, with deviations of +/- 0.10-0.15mm. Additional studies and validation are needed to consolidate inter- and intra-rater variability and enhance the methods.
Feature Extraction Using Deep Generative Models for Bangla Text Classification on a New Comprehensive Dataset
Aug 21, 2023



The selection of features for text classification is a fundamental task in text mining and information retrieval. Despite being the sixth most widely spoken language in the world, Bangla has received little attention due to the scarcity of text datasets. In this research, we collected, annotated, and prepared a comprehensive dataset of 212,184 Bangla documents in seven different categories and made it publicly accessible. We implemented three deep learning generative models: LSTM variational autoencoder (LSTM VAE), auxiliary classifier generative adversarial network (AC-GAN), and adversarial autoencoder (AAE) to extract text features, although their applications are initially found in the field of computer vision. We utilized our dataset to train these three models and used the feature space obtained in the document classification task. We evaluated the performance of the classifiers and found that the adversarial autoencoder model produced the best feature space.