 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Features for Phishing URL Detection Be Trusted Across Diverse Datasets? A Case Study with Explainable AI
Nov 14, 2024



Phishing has been a prevalent cyber threat that manipulates users into revealing sensitive private information through deceptive tactics, designed to masquerade as trustworthy entities. Over the years, proactively detection of phishing URLs (or websites) has been established as an widely-accepted defense approach. In literature, we often find supervised Machine Learning (ML) models with highly competitive performance for detecting phishing websites based on the extracted features from both phishing and benign (i.e., legitimate) websites. However, it is still unclear if these features or indicators are dependent on a particular dataset or they are generalized for overall phishing detection. In this paper, we delve deeper into this issue by analyzing two publicly available phishing URL datasets, where each dataset has its own set of unique and overlapping features related to URL string and website contents. We want to investigate if overlapping features are similar in nature across datasets and how does the model perform when trained on one dataset and tested on the other. We conduct practical experiments and leverage explainable AI (XAI) methods such as SHAP plots to provide insights into different features' contributions in case of phishing detection to answer our primary question, ``Can features for phishing URL detection be trusted across diverse dataset?''. Our case study experiment results show that features for phishing URL detection can often be dataset-dependent and thus may not be trusted across different datasets even though they share same set of feature behaviors.
Visually Analyze SHAP Plots to Diagnose Misclassifications in ML-based Intrusion Detection
Nov 04, 2024



Intrusion detection has been a commonly adopted detective security measures to safeguard systems and networks from various threats. A robust intrusion detection system (IDS) can essentially mitigate threats by providing alerts. In networks based IDS, typically we deal with cyber threats like distributed denial of service (DDoS), spoofing, reconnaissance, brute-force, botnets, and so on. In order to detect these threats various machine learning (ML) and deep learning (DL) models have been proposed. However, one of the key challenges with these predictive approaches is the presence of false positive (FP) and false negative (FN) instances. This FPs and FNs within any black-box intrusion detection system (IDS) make the decision-making task of an analyst further complicated. In this paper, we propose an explainable artificial intelligence (XAI) based visual analysis approach using overlapping SHAP plots that presents the feature explanation to identify potential false positive and false negatives in IDS. Our approach can further provide guidance to security analysts for effective decision-making. We present case study with multiple publicly available network traffic datasets to showcase the efficacy of our approach for identifying false positive and false negative instances. Our use-case scenarios provide clear guidance for analysts on how to use the visual analysis approach for reliable course-of-actions against such threats.
AbuseGPT: Abuse of Generative AI ChatBots to Create Smishing Campaigns
Feb 15, 2024



SMS phishing, also known as "smishing", is a growing threat that tricks users into disclosing private information or clicking into URLs with malicious content through fraudulent mobile text messages. In recent past, we have also observed a rapid advancement of conversational generative AI chatbot services (e.g., OpenAI's ChatGPT, Google's BARD), which are powered by pre-trained large language models (LLMs). These AI chatbots certainly have a lot of utilities but it is not systematically understood how they can play a role in creating threats and attacks. In this paper, we propose AbuseGPT method to show how the existing generative AI-based chatbot services can be exploited by attackers in real world to create smishing texts and eventually lead to craftier smishing campaigns. To the best of our knowledge, there is no pre-existing work that evidently shows the impacts of these generative text-based models on creating SMS phishing. Thus, we believe this study is the first of its kind to shed light on this emerging cybersecurity threat. We have found strong empirical evidences to show that attackers can exploit ethical standards in the existing generative AI-based chatbot services by crafting prompt injection attacks to create newer smishing campaigns. We also discuss some future research directions and guidelines to protect the abuse of generative AI-based services and safeguard users from smishing attacks.
Case Study on Detecting COVID-19 Health-Related Misinformation in Social Media
Jun 12, 2021


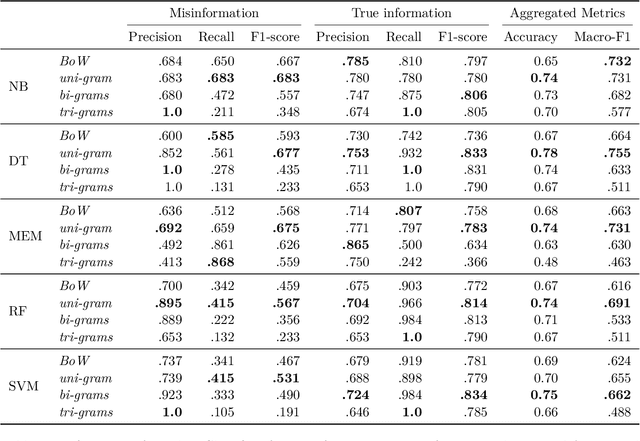
COVID-19 pandemic has generated what public health officials called an infodemic of misinformation. As social distancing and stay-at-home orders came into effect, many turned to social media for socializing. This increase in social media usage has made it a prime vehicle for the spreading of misinformation. This paper presents a mechanism to detect COVID-19 health-related misinformation in social media following an interdisciplinary approach. Leveraging social psychology as a foundation and existing misinformation frameworks, we defined misinformation themes and associated keywords incorporated into the misinformation detection mechanism using applied machine learning techniques. Next, using the Twitter dataset, we explored the performance of the proposed methodology using multiple state-of-the-art machine learning classifiers. Our method shows promising results with at most 78% accuracy in classifying health-related misinformation versus true information using uni-gram-based NLP feature generations from tweets and the Decision Tree classifier. We also provide suggestions on alternatives for countering misinformation and ethical consideration for the study.