 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Study on the Software Engineering Practices in Open Source ML Package Repositories
Dec 08, 2020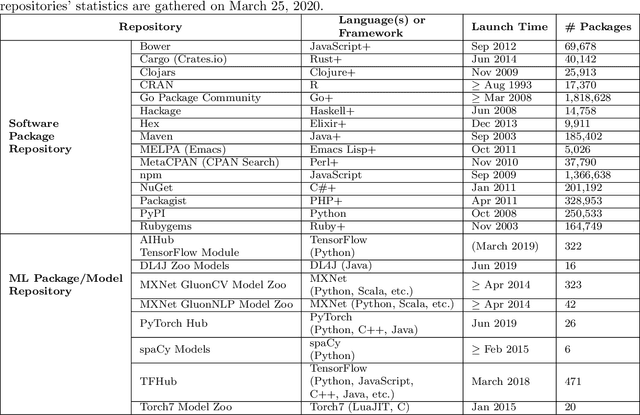
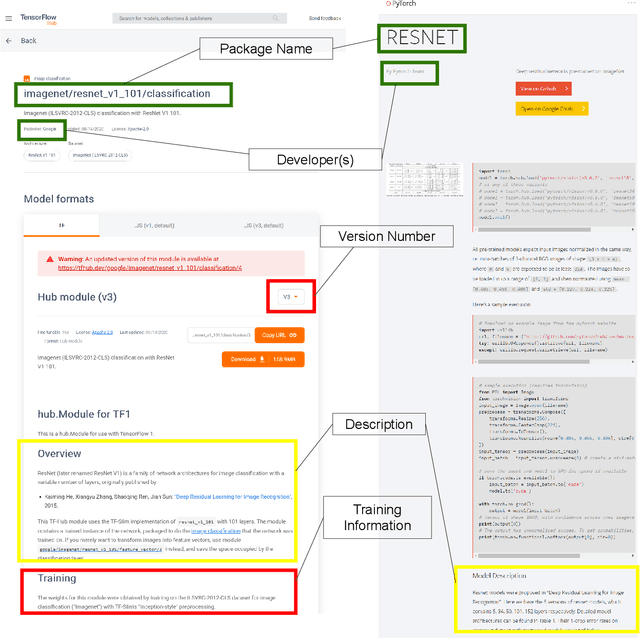
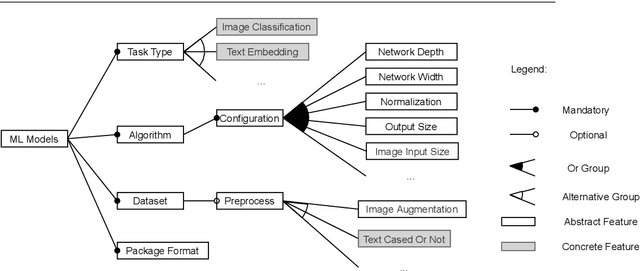
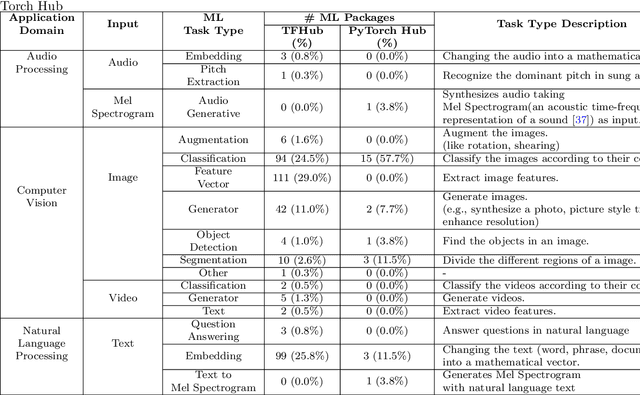
Recent advances in Artificial Intelligence (AI), especially in Machine Learning (ML), have introduced various practical applications (e.g., virtual personal assistants and autonomous cars) that enhance the experience of everyday users. However, modern ML technologies like Deep Learning require considerable technical expertise and resources to develop, train and deploy such models, making effective reuse of the ML models a necessity. Such discovery and reuse by practitioners and researchers are being addressed by public ML package repositories, which bundle up pre-trained models into packages for publication. Since such repositories are a recent phenomenon, there is no empirical data on their current state and challenges. Hence, this paper conducts an exploratory study that analyzes the structure and contents of two popular ML package repositories, TFHub and PyTorch Hub, comparing their information elements (features and policies), package organization, package manager functionalities and usage contexts against popular software package repositories (npm, PyPI, and CRAN). Through these studies, we have identified unique SE practices and challenges for sharing ML packages. These findings and implications would be useful for data scientists, researchers and software developers who intend to use these shared ML packages.