 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPA-Net: Meteorology-Aware Multi-Scale Attention and Dynamic Loss for Extreme Convective Radar Nowcasting
Apr 27, 2026Short-range prediction of convective precipitation from weather radar observations is essential for severe weather warnings. However, deep learning models trained with pixel-wise error metrics tend to produce overly smooth forecasts that suppress intense echoes critical for hazard detection. This issue is exacerbated by insufficient multi-scale feature interaction and suboptimal fusion of heterogeneous geophysical inputs. We propose IMPA-Net (Integrated Multi-scale Predictive Attention Network), a deterministic 0-2 hour nowcasting framework that addresses these limitations through meteorologically-informed designs at the input, architecture, and loss function levels. A parameter-free Spatial Mixer reorganizes heterogeneous input channels at the mesoscale-$γ$ neighborhood (~2 km) via deterministic channel permutation, providing a structured cross-field prior. An integrated multi-scale predictive attention module serves as the spatiotemporal translator, capturing dynamics from mesoscale-$β$ to mesoscale-$γ$ scales. A Meteorologically-Aware Dynamic Loss employs three-level asymmetric weighting -- adapting across training epochs, storm intensity, and forecast lead time -- to counteract regression-to-the-mean. Evaluated against seven baselines on a multi-source radar dataset over eastern China, IMPA-Net raises the Heidke Skill Score at $\geq$45 dBZ from 0.049 (SimVP baseline) to 0.143 under matched settings. Relative to pySTEPS, it provides a better trade-off between severe-event detection and false-alarm control. Spectral analysis confirms preserved energy across mesoscale bands where competing methods show progressive smoothing. These improvements are shown within a single domain and convective regime; generalizability to other orographic and climatic regions remains to be tested.
MMCoVaR: Multimodal COVID-19 Vaccine Focused Data Repository for Fake News Detection and a Baseline Architecture for Classification
Sep 23, 2021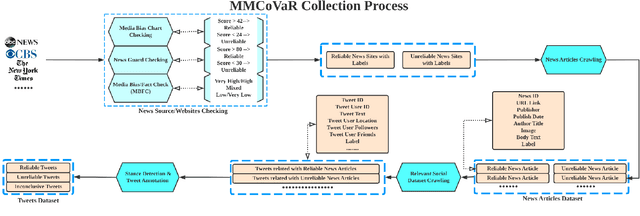
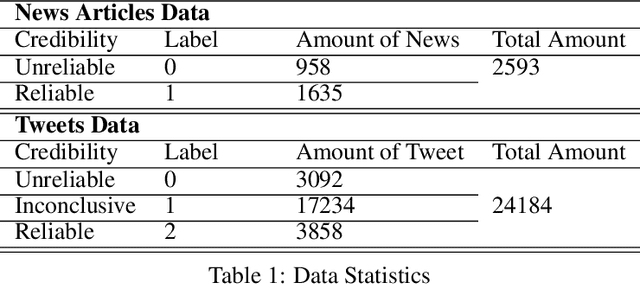
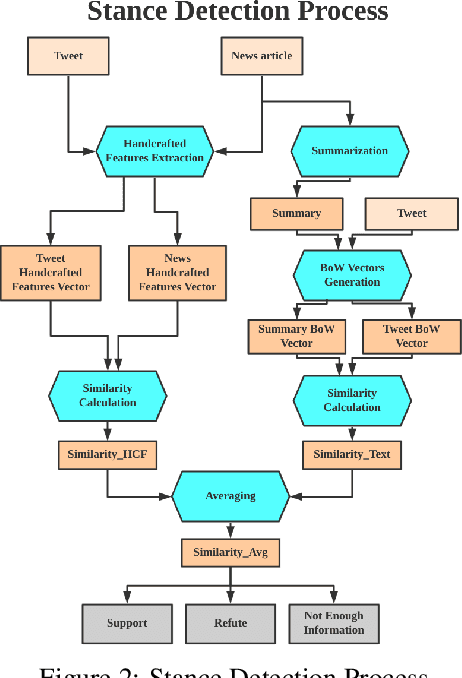

The outbreak of COVID-19 has resulted in an "infodemic" that has encouraged the propagation of misinformation about COVID-19 and cure methods which, in turn, could negatively affect the adoption of recommended public health measures in the larger population. In this paper, we provide a new multimodal (consisting of images, text and temporal information) labeled dataset containing news articles and tweets on the COVID-19 vaccine. We collected 2,593 news articles from 80 publishers for one year between Feb 16th 2020 to May 8th 2021 and 24184 Twitter posts (collected between April 17th 2021 to May 8th 2021). We combine ratings from two news media ranking sites: Medias Bias Chart and Media Bias/Fact Check (MBFC) to classify the news dataset into two levels of credibility: reliable and unreliable. The combination of two filters allows for higher precision of labeling. We also propose a stance detection mechanism to annotate tweets into three levels of credibility: reliable, unreliable and inconclusive. We provide several statistics as well as other analytics like, publisher distribution, publication date distribution, topic analysis, etc. We also provide a novel architecture that classifies the news data into misinformation or truth to provide a baseline performance for this dataset. We find that the proposed architecture has an F-Score of 0.919 and accuracy of 0.882 for fake news detection. Furthermore, we provide benchmark performance for misinformation detection on tweet dataset. This new multimodal dataset can be used in research on COVID-19 vaccine, including misinformation detection, influence of fake COVID-19 vaccine information, etc.
Explainable Rumor Detection using Inter and Intra-feature Attention Networks
Jul 21, 2020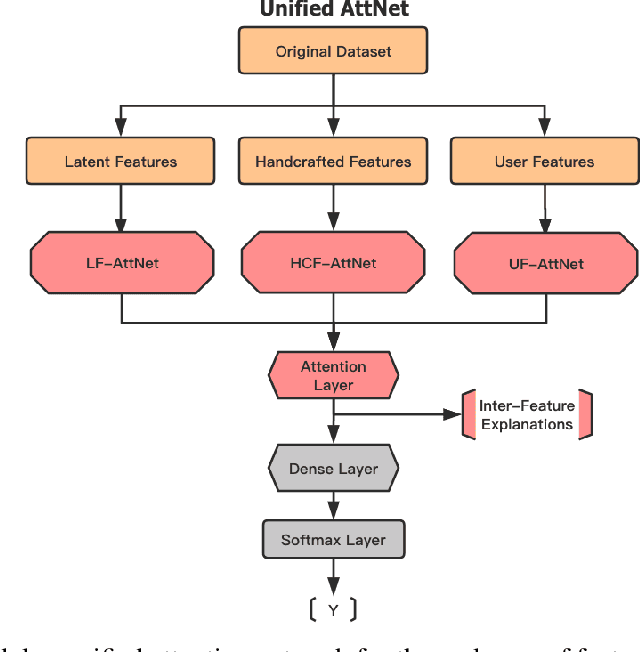

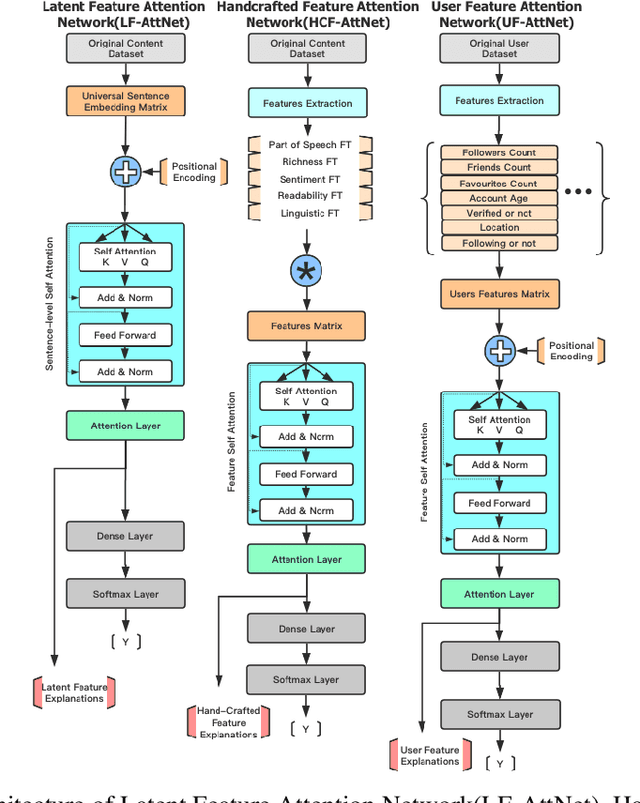
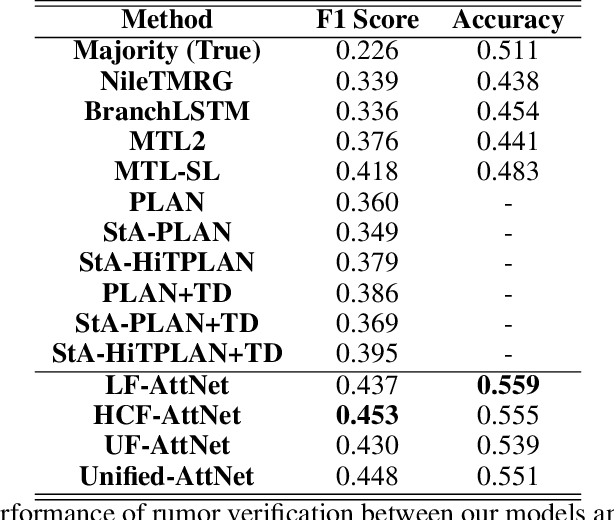
With social media becoming ubiquitous, information consumption from this media has also increased. However, one of the serious problems that have emerged with this increase, is the propagation of rumors. Therefore, rumor identification is a very critical task with significant implications to economy, democracy as well as public health and safety. We tackle the problem of automated detection of rumors in social media in this paper by designing a modular explainable architecture that uses both latent and handcrafted features and can be expanded to as many new classes of features as desired. This approach will allow the end user to not only determine whether the piece of information on the social media is real of a rumor, but also give explanations on why the algorithm arrived at its conclusion. Using attention mechanisms, we are able to interpret the relative importance of each of these features as well as the relative importance of the feature classes themselves. The advantage of this approach is that the architecture is expandable to more handcrafted features as they become available and also to conduct extensive testing to determine the relative influences of these features in the final decision. Extensive experimentation on popular datasets and benchmarking against eleven contemporary algorithms, show that our approach performs significantly better in terms of F-score and accuracy while also being interpretable.
Explainable CNN-attention Networks (C-Attention Network) for Automated Detection of Alzheimer's Disease
Jun 25, 2020In this work, we propose three explainable deep learning architectures to automatically detect patients with Alzheimer`s disease based on their language abilities. The architectures use: (1) only the part-of-speech features; (2) only language embedding features and (3) both of these feature classes via a unified architecture. We use self-attention mechanisms and interpretable 1-dimensional ConvolutionalNeural Network (CNN) to generate two types of explanations of the model`s action: intra-class explanation and inter-class explanation. The inter-class explanation captures the relative importance of each of the different features in that class, while the inter-class explanation captures the relative importance between the classes. Note that although we have considered two classes of features in this paper, the architecture is easily expandable to more classes because of its modularity. Extensive experimentation and comparison with several recent models show that our method outperforms these methods with an accuracy of 92.2% and F1 score of 0.952on the DementiaBank dataset while being able to generate explanations. We show by examples, how to generate these explanations using attention values.