 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCoVaR: Multimodal COVID-19 Vaccine Focused Data Repository for Fake News Detection and a Baseline Architecture for Classification
Paper and Code
Sep 23, 2021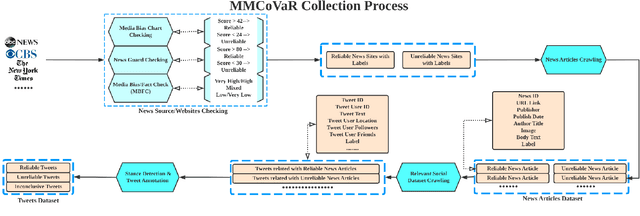
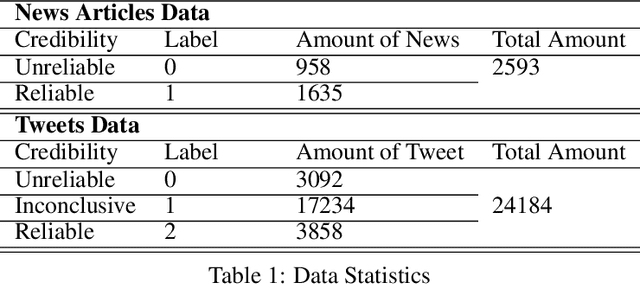
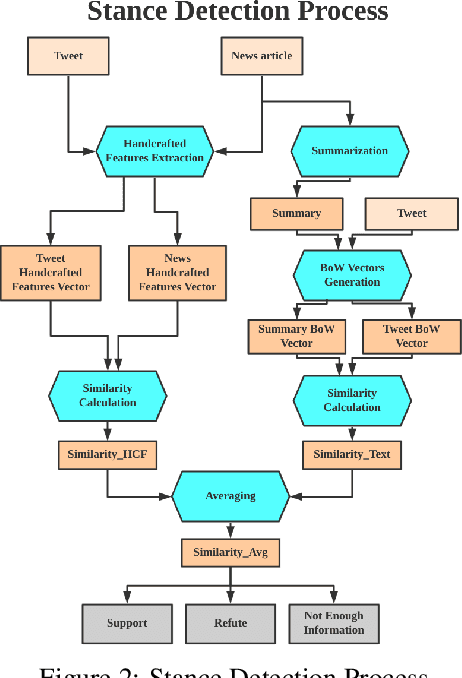

The outbreak of COVID-19 has resulted in an "infodemic" that has encouraged the propagation of misinformation about COVID-19 and cure methods which, in turn, could negatively affect the adoption of recommended public health measures in the larger population. In this paper, we provide a new multimodal (consisting of images, text and temporal information) labeled dataset containing news articles and tweets on the COVID-19 vaccine. We collected 2,593 news articles from 80 publishers for one year between Feb 16th 2020 to May 8th 2021 and 24184 Twitter posts (collected between April 17th 2021 to May 8th 2021). We combine ratings from two news media ranking sites: Medias Bias Chart and Media Bias/Fact Check (MBFC) to classify the news dataset into two levels of credibility: reliable and unreliable. The combination of two filters allows for higher precision of labeling. We also propose a stance detection mechanism to annotate tweets into three levels of credibility: reliable, unreliable and inconclusive. We provide several statistics as well as other analytics like, publisher distribution, publication date distribution, topic analysis, etc. We also provide a novel architecture that classifies the news data into misinformation or truth to provide a baseline performance for this dataset. We find that the proposed architecture has an F-Score of 0.919 and accuracy of 0.882 for fake news detection. Furthermore, we provide benchmark performance for misinformation detection on tweet dataset. This new multimodal dataset can be used in research on COVID-19 vaccine, including misinformation detection, influence of fake COVID-19 vaccine information, etc.