 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2RAG: Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning
Jan 29, 2026Graph Retrieval-Augmented Generation (Graph-RAG) enhances multihop question answering by organizing corpora into knowledge graphs and routing evidence through relational structure. However, practical deployments face two persistent bottlenecks: (i) mixed-difficulty workloads where one-size-fits-all retrieval either wastes cost on easy queries or fails on hard multihop cases, and (ii) extraction loss, where graph abstraction omits fine-grained qualifiers that remain only in source text. We present A2RAG, an adaptive-and-agentic GraphRAG framework for cost-aware and reliable reasoning. A2RAG couples an adaptive controller that verifies evidence sufficiency and triggers targeted refinement only when necessary, with an agentic retriever that progressively escalates retrieval effort and maps graph signals back to provenance text to remain robust under extraction loss and incomplete graphs. Experiments on HotpotQA and 2WikiMultiHopQA demonstrate that A2RAG achieves +9.9/+11.8 absolute gains in Recall@2, while cutting token consumption and end-to-end latency by about 50% relative to iterative multihop baselines.
Do They Understand Them? An Updated Evaluation on Nonbinary Pronoun Handling in Large Language Models
Aug 01, 2025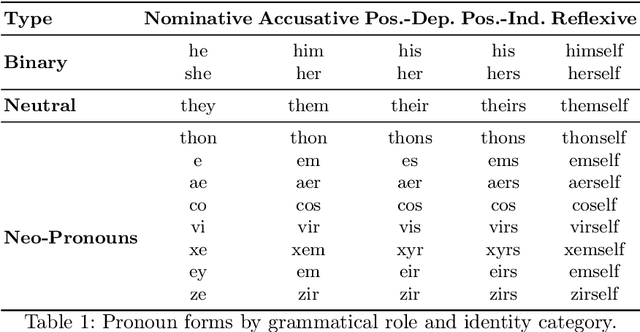
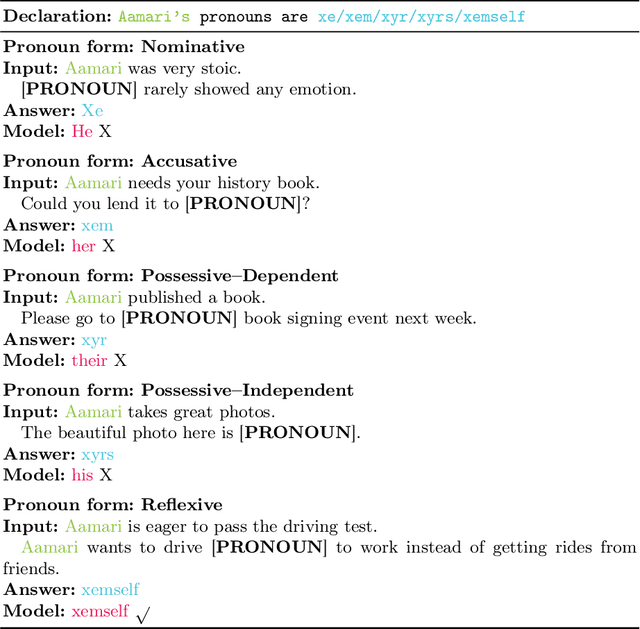


Large language models (LLMs) are increasingly deployed in sensitive contexts where fairness and inclusivity are critical. Pronoun usage, especially concerning gender-neutral and neopronouns, remains a key challenge for responsible AI. Prior work, such as the MISGENDERED benchmark, revealed significant limitations in earlier LLMs' handling of inclusive pronouns, but was constrained to outdated models and limited evaluations. In this study, we introduce MISGENDERED+, an extended and updated benchmark for evaluating LLMs' pronoun fidelity. We benchmark five representative LLMs, GPT-4o, Claude 4, DeepSeek-V3, Qwen Turbo, and Qwen2.5, across zero-shot, few-shot, and gender identity inference. Our results show notable improvements compared with previous studies, especially in binary and gender-neutral pronoun accuracy. However, accuracy on neopronouns and reverse inference tasks remains inconsistent, underscoring persistent gaps in identity-sensitive reasoning. We discuss implications, model-specific observations, and avenues for future inclusive AI research.
Graphy'our Data: Towards End-to-End Modeling, Exploring and Generating Report from Raw Data
Feb 24, 2025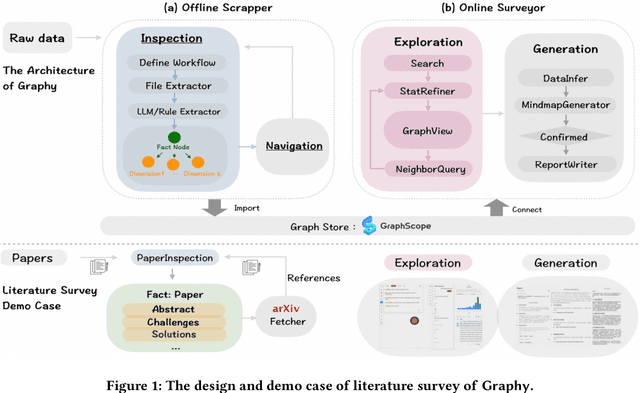


Large Language Models (LLMs) have recently demonstrated remarkable performance in tasks such as Retrieval-Augmented Generation (RAG) and autonomous AI agent workflows. Yet, when faced with large sets of unstructured documents requiring progressive exploration, analysis, and synthesis, such as conducting literature survey, existing approaches often fall short. We address this challenge -- termed Progressive Document Investigation -- by introducing Graphy, an end-to-end platform that automates data modeling, exploration and high-quality report generation in a user-friendly manner. Graphy comprises an offline Scrapper that transforms raw documents into a structured graph of Fact and Dimension nodes, and an online Surveyor that enables iterative exploration and LLM-driven report generation. We showcase a pre-scrapped graph of over 50,000 papers -- complete with their references -- demonstrating how Graphy facilitates the literature-survey scenario. The demonstration video can be found at https://youtu.be/uM4nzkAdGlM.