 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Recurrent Neural Networks and Deep Learning Frameworks on Real-time Lightweight Time Series Anomaly Detection
Jul 26, 2024


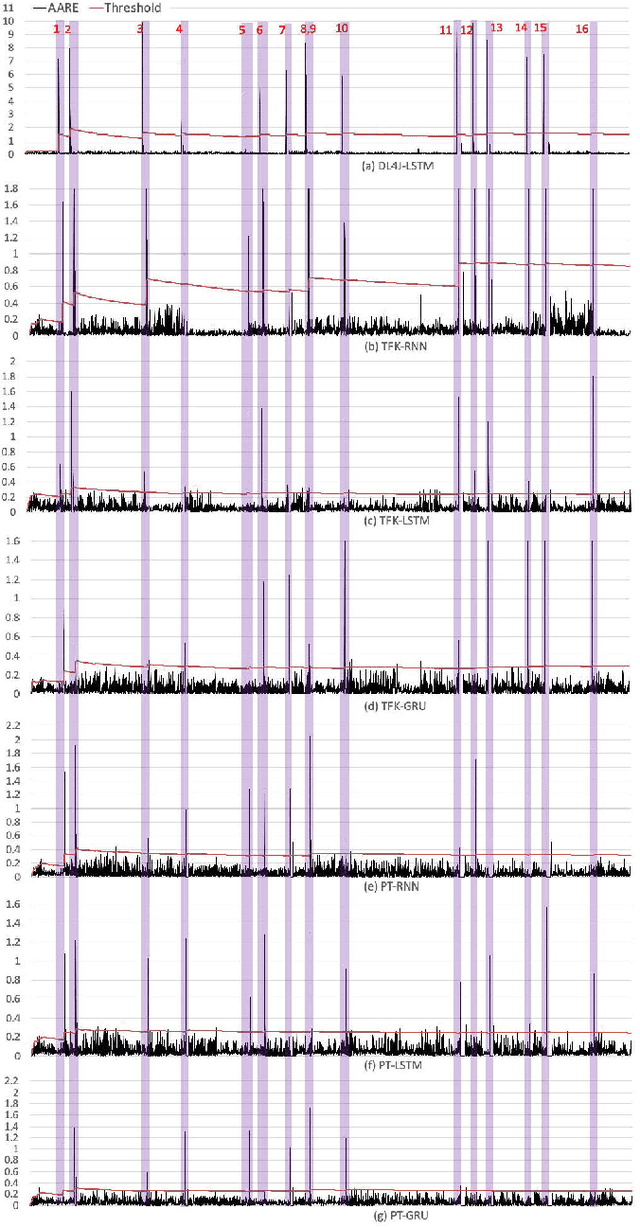
Real-time lightweight time series anomaly detection has become increasingly crucial in cybersecurity and many other domains. Its ability to adapt to unforeseen pattern changes and swiftly identify anomalies enables prompt responses and critical decision-making. While several such anomaly detection approaches have been introduced in recent years, they primarily utilize a single type of recurrent neural networks (RNNs) and have been implemented in only one deep learning framework. It is unclear how the use of different types of RNNs available in various deep learning frameworks affects the performance of these anomaly detection approaches due to the absence of comprehensive evaluations. Arbitrarily choosing a RNN variant and a deep learning framework to implement an anomaly detection approach may not reflect its true performance and could potentially mislead users into favoring one approach over another. In this paper, we aim to study the influence of various types of RNNs available in popular deep learning frameworks on real-time lightweight time series anomaly detection. We reviewed several state-of-the-art approaches and implemented a representative anomaly detection approach using well-known RNN variants supported by three widely recognized deep learning frameworks. A comprehensive evaluation is then conducted to analyze the performance of each implementation across real-world, open-source time series datasets. The evaluation results provide valuable guidance for selecting the appropriate RNN variant and deep learning framework for real-time, lightweight time series anomaly detection.
Investigating the Privacy Risk of Using Robot Vacuum Cleaners in Smart Environments
Jul 26, 2024Robot vacuum cleaners have become increasingly popular and are widely used in various smart environments. To improve user convenience, manufacturers also introduced smartphone applications that enable users to customize cleaning settings or access information about their robot vacuum cleaners. While this integration enhances the interaction between users and their robot vacuum cleaners, it results in potential privacy concerns because users' personal information may be exposed. To address these concerns, end-to-end encryption is implemented between the application, cloud service, and robot vacuum cleaners to secure the exchanged information. Nevertheless, network header metadata remains unencrypted and it is still vulnerable to network eavesdropping. In this paper, we investigate the potential risk of private information exposure through such metadata. A popular robot vacuum cleaner was deployed in a real smart environment where passive network eavesdropping was conducted during several selected cleaning events. Our extensive analysis, based on Association Rule Learning, demonstrates that it is feasible to identify certain events using only the captured Internet traffic metadata, thereby potentially exposing private user information and raising privacy concerns.
GAD: A Real-time Gait Anomaly Detection System with Online Adaptive Learning
May 04, 2024



Gait anomaly detection is a task that involves detecting deviations from a person's normal gait pattern. These deviations can indicate health issues and medical conditions in the healthcare domain, or fraudulent impersonation and unauthorized identity access in the security domain. A number of gait anomaly detection approaches have been introduced, but many of them require offline data preprocessing, offline model learning, setting parameters, and so on, which might restrict their effectiveness and applicability in real-world scenarios. To address these issues, this paper introduces GAD, a real-time gait anomaly detection system. GAD focuses on detecting anomalies within an individual's three-dimensional accelerometer readings based on dimensionality reduction and Long Short-Term Memory (LSTM). Upon being launched, GAD begins collecting a gait segment from the user and training an anomaly detector to learn the user's walking pattern on the fly. If the subsequent model verification is successful, which involves validating the trained detector using the user's subsequent steps, the detector is employed to identify abnormalities in the user's subsequent gait readings at the user's request. The anomaly detector will be retained online to adapt to minor pattern changes and will undergo retraining as long as it cannot provide adequate prediction. We explored two methods for capturing users' gait segments: a personalized method tailored to each individual's step length, and a uniform method utilizing a fixed step length. Experimental results using an open-source gait dataset show that GAD achieves a higher detection accuracy ratio when combined with the personalized method.
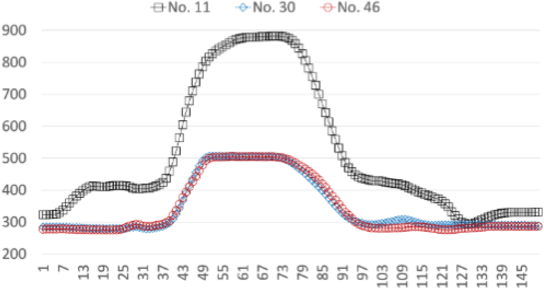
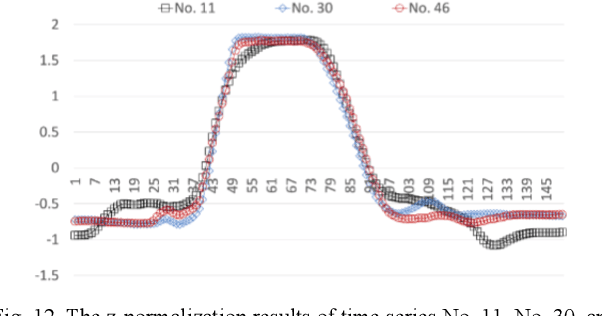
Evaluation of k-means time series clustering based on z-normalization and NP-Free
Jan 28, 2024Despite the widespread use of k-means time series clustering in various domains, there exists a gap in the literature regarding its comprehensive evaluation with different time series normalization approaches. This paper seeks to fill this gap by conducting a thorough performance evaluation of k-means time series clustering on real-world open-source time series datasets. The evaluation focuses on two distinct normalization techniques: z-normalization and NP-Free. The former is one of the most commonly used normalization approach for time series. The latter is a real-time time series representation approach, which can serve as a time series normalization approach. The primary objective of this paper is to assess the impact of these two normalization techniques on k-means time series clustering in terms of its clustering quality. The experiments employ the silhouette score, a well-established metric for evaluating the quality of clusters in a dataset. By systematically investigating the performance of k-means time series clustering with these two normalization techniques, this paper addresses the current gap in k-means time series clustering evaluation and contributes valuable insights to the development of time series clustering.
RoLA: A Real-Time Online Lightweight Anomaly Detection System for Multivariate Time Series
May 25, 2023



A multivariate time series refers to observations of two or more variables taken from a device or a system simultaneously over time. There is an increasing need to monitor multivariate time series and detect anomalies in real time to ensure proper system operation and good service quality. It is also highly desirable to have a lightweight anomaly detection system that considers correlations between different variables, adapts to changes in the pattern of the multivariate time series, offers immediate responses, and provides supportive information regarding detection results based on unsupervised learning and online model training. In the past decade, many multivariate time series anomaly detection approaches have been introduced. However, they are unable to offer all the above-mentioned features. In this paper, we propose RoLA, a real-time online lightweight anomaly detection system for multivariate time series based on a divide-and-conquer strategy, parallel processing, and the majority rule. RoLA employs multiple lightweight anomaly detectors to monitor multivariate time series in parallel, determine the correlations between variables dynamically on the fly, and then jointly detect anomalies based on the majority rule in real time. To demonstrate the performance of RoLA, we conducted an experiment based on a public dataset provided by the FerryBox of the One Ocean Expedition. The results show that RoLA provides satisfactory detection accuracy and lightweight performance.
Impact of Deep Learning Libraries on Online Adaptive Lightweight Time Series Anomaly Detection
May 10, 2023Providing online adaptive lightweight time series anomaly detection without human intervention and domain knowledge is highly valuable. Several such anomaly detection approaches have been introduced in the past years, but all of them were only implemented in one deep learning library. With the development of deep learning libraries, it is unclear how different deep learning libraries impact these anomaly detection approaches since there is no such evaluation available. Randomly choosing a deep learning library to implement an anomaly detection approach might not be able to show the true performance of the approach. It might also mislead users in believing one approach is better than another. Therefore, in this paper, we investigate the impact of deep learning libraries on online adaptive lightweight time series anomaly detection by implementing two state-of-the-art anomaly detection approaches in three well-known deep learning libraries and evaluating how these two approaches are individually affected by the three deep learning libraries. A series of experiments based on four real-world open-source time series datasets were conducted. The results provide a good reference to select an appropriate deep learning library for online adaptive lightweight anomaly detection.
NP-Free: A Real-Time Normalization-free and Parameter-tuning-free Representation Approach for Open-ended Time Series
Apr 12, 2023
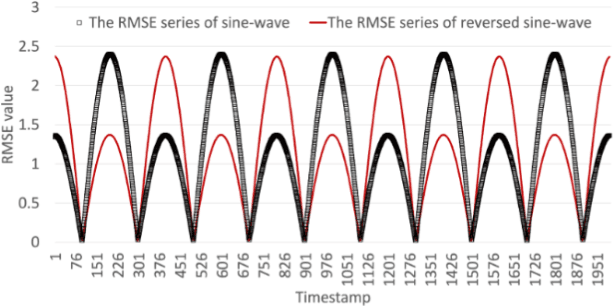
As more connected devices are implemented in a cyber-physical world and data is expected to be collected and processed in real time, the ability to handle time series data has become increasingly significant. To help analyze time series in data mining applications, many time series representation approaches have been proposed to convert a raw time series into another series for representing the original time series. However, existing approaches are not designed for open-ended time series (which is a sequence of data points being continuously collected at a fixed interval without any length limit) because these approaches need to know the total length of the target time series in advance and pre-process the entire time series using normalization methods. Furthermore, many representation approaches require users to configure and tune some parameters beforehand in order to achieve satisfactory representation results. In this paper, we propose NP-Free, a real-time Normalization-free and Parameter-tuning-free representation approach for open-ended time series. Without needing to use any normalization method or tune any parameter, NP-Free can generate a representation for a raw time series on the fly by converting each data point of the time series into a root-mean-square error (RMSE) value based on Long Short-Term Memory (LSTM) and a Look-Back and Predict-Forward strategy. To demonstrate the capability of NP-Free in representing time series, we conducted several experiments based on real-world open-source time series datasets. We also evaluated the time consumption of NP-Free in generating representations.
RePAD2: Real-Time, Lightweight, and Adaptive Anomaly Detection for Open-Ended Time Series
Mar 02, 2023



An open-ended time series refers to a series of data points indexed in time order without an end. Such a time series can be found everywhere due to the prevalence of Internet of Things. Providing lightweight and real-time anomaly detection for open-ended time series is highly desirable to industry and organizations since it allows immediate response and avoids potential financial loss. In the last few years, several real-time time series anomaly detection approaches have been introduced. However, they might exhaust system resources when they are applied to open-ended time series for a long time. To address this issue, in this paper we propose RePAD2, a lightweight real-time anomaly detection approach for open-ended time series by improving its predecessor RePAD, which is one of the state-of-the-art anomaly detection approaches. We conducted a series of experiments to compare RePAD2 with RePAD and another similar detection approach based on real-world time series datasets, and demonstrated that RePAD2 can address the mentioned resource exhaustion issue while offering comparable detection accuracy and slightly less time consumption.
DistTune: Distributed Fine-Grained Adaptive Traffic Speed Prediction for Growing Transportation Networks
May 19, 2021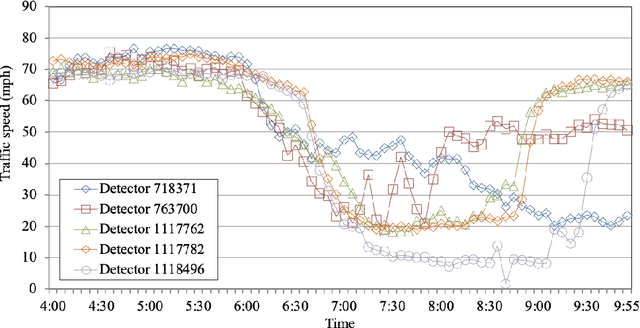
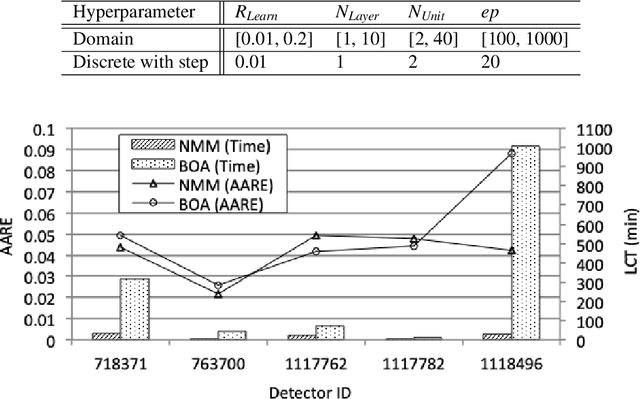
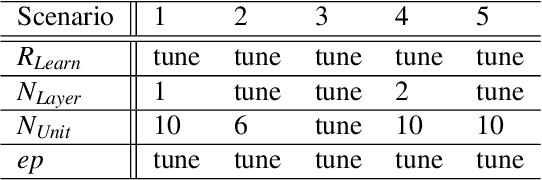

Over the past decade, many approaches have been introduced for traffic speed prediction. However, providing fine-grained, accurate, time-efficient, and adaptive traffic speed prediction for a growing transportation network where the size of the network keeps increasing and new traffic detectors are constantly deployed has not been well studied. To address this issue, this paper presents DistTune based on Long Short-Term Memory (LSTM) and the Nelder-Mead method. Whenever encountering an unprocessed detector, DistTune decides if it should customize an LSTM model for this detector by comparing the detector with other processed detectors in terms of the normalized traffic speed patterns they have observed. If similarity is found, DistTune directly shares an existing LSTM model with this detector to achieve time-efficient processing. Otherwise, DistTune customizes an LSTM model for the detector to achieve fine-grained prediction. To make DistTune even more time-efficient, DistTune performs on a cluster of computing nodes in parallel. To achieve adaptive traffic speed prediction, DistTune also provides LSTM re-customization for detectors that suffer from unsatisfactory prediction accuracy due to for instance traffic speed pattern change. Extensive experiments based on traffic data collected from freeway I5-N in California are conducted to evaluate the performance of DistTune. The results demonstrate that DistTune provides fine-grained, accurate, time-efficient, and adaptive traffic speed prediction for a growing transportation network.
* 16 pages,21 figures, 4 tables
SALAD: Self-Adaptive Lightweight Anomaly Detection for Real-time Recurrent Time Series
May 04, 2021
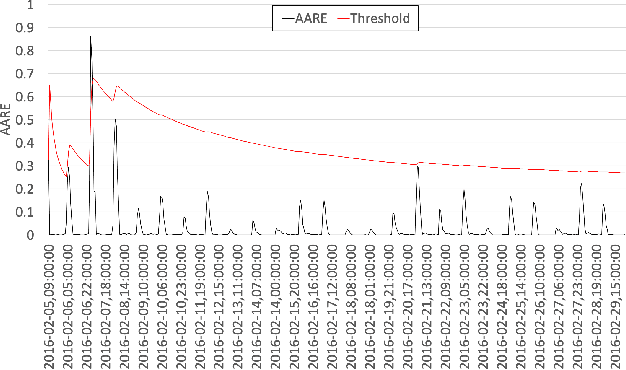

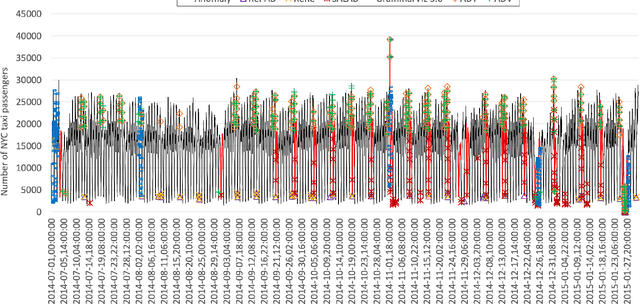
Real-world time series data often present recurrent or repetitive patterns and it is often generated in real time, such as transportation passenger volume, network traffic, system resource consumption, energy usage, and human gait. Detecting anomalous events based on machine learning approaches in such time series data has been an active research topic in many different areas. However, most machine learning approaches require labeled datasets, offline training, and may suffer from high computation complexity, consequently hindering their applicability. Providing a lightweight self-adaptive approach that does not need offline training in advance and meanwhile is able to detect anomalies in real time could be highly beneficial. Such an approach could be immediately applied and deployed on any commodity machine to provide timely anomaly alerts. To facilitate such an approach, this paper introduces SALAD, which is a Self-Adaptive Lightweight Anomaly Detection approach based on a special type of recurrent neural networks called Long Short-Term Memory (LSTM). Instead of using offline training, SALAD converts a target time series into a series of average absolute relative error (AARE) values on the fly and predicts an AARE value for every upcoming data point based on short-term historical AARE values. If the difference between a calculated AARE value and its corresponding forecast AARE value is higher than a self-adaptive detection threshold, the corresponding data point is considered anomalous. Otherwise, the data point is considered normal. Experiments based on two real-world open-source time series datasets demonstrate that SALAD outperforms five other state-of-the-art anomaly detection approaches in terms of detection accuracy. In addition, the results also show that SALAD is lightweight and can be deployed on a commodity machine.