 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Signatures of Image Phenotypes to Track Treatment Response in Liver Disease
Jul 16, 2025



Quantifiable image patterns associated with disease progression and treatment response are critical tools for guiding individual treatment, and for developing novel therapies. Here, we show that unsupervised machine learning can identify a pattern vocabulary of liver tissue in magnetic resonance images that quantifies treatment response in diffuse liver disease. Deep clustering networks simultaneously encode and cluster patches of medical images into a low-dimensional latent space to establish a tissue vocabulary. The resulting tissue types capture differential tissue change and its location in the liver associated with treatment response. We demonstrate the utility of the vocabulary on a randomized controlled trial cohort of non-alcoholic steatohepatitis patients. First, we use the vocabulary to compare longitudinal liver change in a placebo and a treatment cohort. Results show that the method identifies specific liver tissue change pathways associated with treatment, and enables a better separation between treatment groups than established non-imaging measures. Moreover, we show that the vocabulary can predict biopsy derived features from non-invasive imaging data. We validate the method on a separate replication cohort to demonstrate the applicability of the proposed method.
Pseudo-domains in imaging data improve prediction of future disease status in multi-center studies
Nov 15, 2021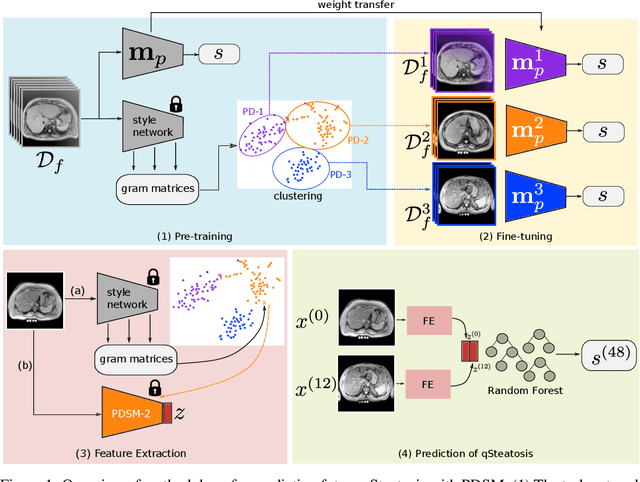
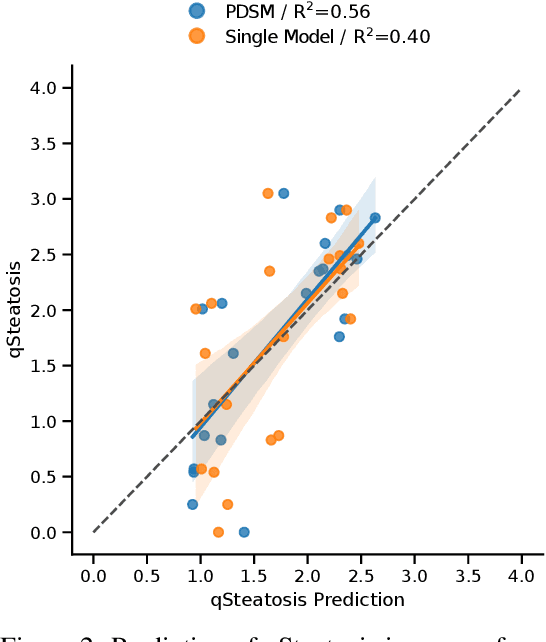
In multi-center randomized clinical trials imaging data can be diverse due to acquisition technology or scanning protocols. Models predicting future outcome of patients are impaired by this data heterogeneity. Here, we propose a prediction method that can cope with a high number of different scanning sites and a low number of samples per site. We cluster sites into pseudo-domains based on visual appearance of scans, and train pseudo-domain specific models. Results show that they improve the prediction accuracy for steatosis after 48 weeks from imaging data acquired at an initial visit and 12-weeks follow-up in liver disease