 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi Monte Carlo methods enable extremely low-dimensional deep generative models
Jan 26, 2026This paper introduces quasi-Monte Carlo latent variable models (QLVMs): a class of deep generative models that are specialized for finding extremely low-dimensional and interpretable embeddings of high-dimensional datasets. Unlike standard approaches, which rely on a learned encoder and variational lower bounds, QLVMs directly approximate the marginal likelihood by randomized quasi-Monte Carlo integration. While this brute force approach has drawbacks in higher-dimensional spaces, we find that it excels in fitting one, two, and three dimensional deep latent variable models. Empirical results on a range of datasets show that QLVMs consistently outperform conventional variational autoencoders (VAEs) and importance weighted autoencoders (IWAEs) with matched latent dimensionality. The resulting embeddings enable transparent visualization and post hoc analyses such as nonparametric density estimation, clustering, and geodesic path computation, which are nontrivial to validate in higher-dimensional spaces. While our approach is compute-intensive and struggles to generate fine-scale details in complex datasets, it offers a compelling solution for applications prioritizing interpretability and latent space analysis.
Reproducible, incremental representation learning with Rosetta VAE
Jan 13, 2022

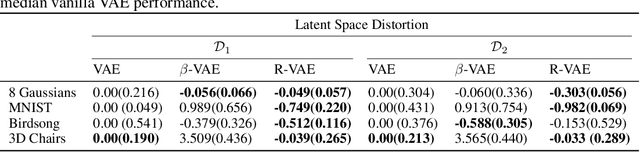
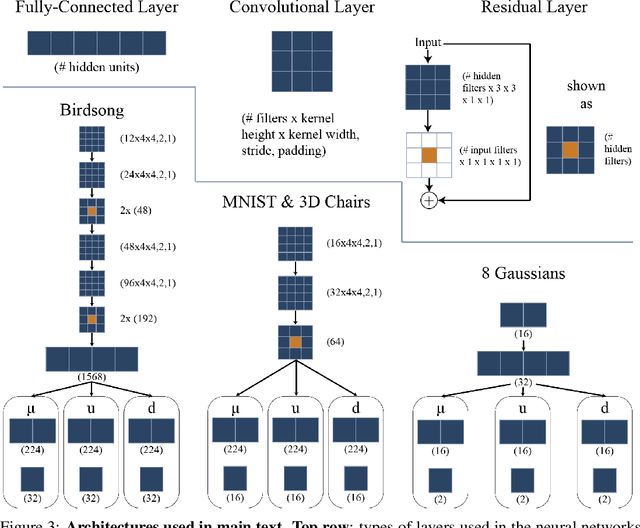
Variational autoencoders are among the most popular methods for distilling low-dimensional structure from high-dimensional data, making them increasingly valuable as tools for data exploration and scientific discovery. However, unlike typical machine learning problems in which a single model is trained once on a single large dataset, scientific workflows privilege learned features that are reproducible, portable across labs, and capable of incrementally adding new data. Ideally, methods used by different research groups should produce comparable results, even without sharing fully trained models or entire data sets. Here, we address this challenge by introducing the Rosetta VAE (R-VAE), a method of distilling previously learned representations and retraining new models to reproduce and build on prior results. The R-VAE uses post hoc clustering over the latent space of a fully-trained model to identify a small number of Rosetta Points (input, latent pairs) to serve as anchors for training future models. An adjustable hyperparameter, $\rho$, balances fidelity to the previously learned latent space against accommodation of new data. We demonstrate that the R-VAE reconstructs data as well as the VAE and $\beta$-VAE, outperforms both methods in recovery of a target latent space in a sequential training setting, and dramatically increases consistency of the learned representation across training runs.