 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInflationary Flows: Calibrated Bayesian Inference with Diffusion-Based Models
Jul 11, 2024Beyond estimating parameters of interest from data, one of the key goals of statistical inference is to properly quantify uncertainty in these estimates. In Bayesian inference, this uncertainty is provided by the posterior distribution, the computation of which typically involves an intractable high-dimensional integral. Among available approximation methods, sampling-based approaches come with strong theoretical guarantees but scale poorly to large problems, while variational approaches scale well but offer few theoretical guarantees. In particular, variational methods are known to produce overconfident estimates of posterior uncertainty and are typically non-identifiable, with many latent variable configurations generating equivalent predictions. Here, we address these challenges by showing how diffusion-based models (DBMs), which have recently produced state-of-the-art performance in generative modeling tasks, can be repurposed for performing calibrated, identifiable Bayesian inference. By exploiting a previously established connection between the stochastic and probability flow ordinary differential equations (pfODEs) underlying DBMs, we derive a class of models, inflationary flows, that uniquely and deterministically map high-dimensional data to a lower-dimensional Gaussian distribution via ODE integration. This map is both invertible and neighborhood-preserving, with controllable numerical error, with the result that uncertainties in the data are correctly propagated to the latent space. We demonstrate how such maps can be learned via standard DBM training using a novel noise schedule and are effective at both preserving and reducing intrinsic data dimensionality. The result is a class of highly expressive generative models, uniquely defined on a low-dimensional latent space, that afford principled Bayesian inference.
Reproducible, incremental representation learning with Rosetta VAE
Jan 13, 2022

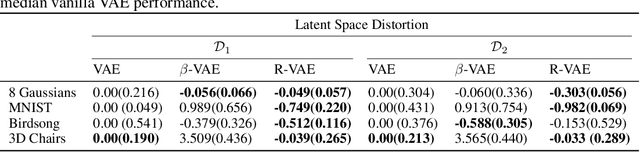
Variational autoencoders are among the most popular methods for distilling low-dimensional structure from high-dimensional data, making them increasingly valuable as tools for data exploration and scientific discovery. However, unlike typical machine learning problems in which a single model is trained once on a single large dataset, scientific workflows privilege learned features that are reproducible, portable across labs, and capable of incrementally adding new data. Ideally, methods used by different research groups should produce comparable results, even without sharing fully trained models or entire data sets. Here, we address this challenge by introducing the Rosetta VAE (R-VAE), a method of distilling previously learned representations and retraining new models to reproduce and build on prior results. The R-VAE uses post hoc clustering over the latent space of a fully-trained model to identify a small number of Rosetta Points (input, latent pairs) to serve as anchors for training future models. An adjustable hyperparameter, $\rho$, balances fidelity to the previously learned latent space against accommodation of new data. We demonstrate that the R-VAE reconstructs data as well as the VAE and $\beta$-VAE, outperforms both methods in recovery of a target latent space in a sequential training setting, and dramatically increases consistency of the learned representation across training runs.
Bubblewrap: Online tiling and real-time flow prediction on neural manifolds
Aug 31, 2021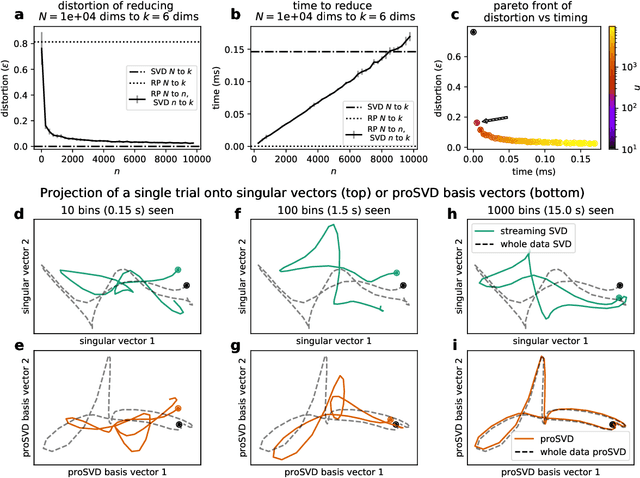
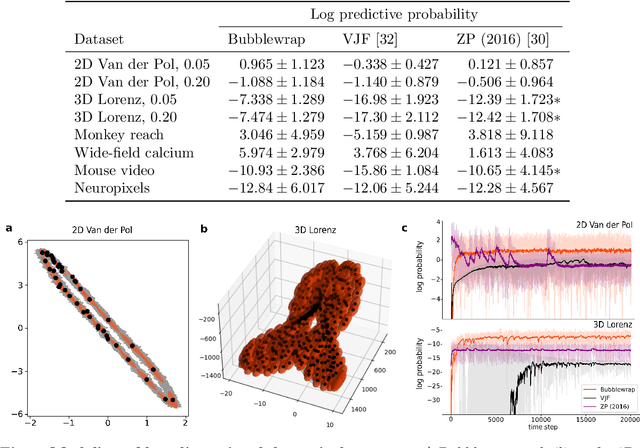
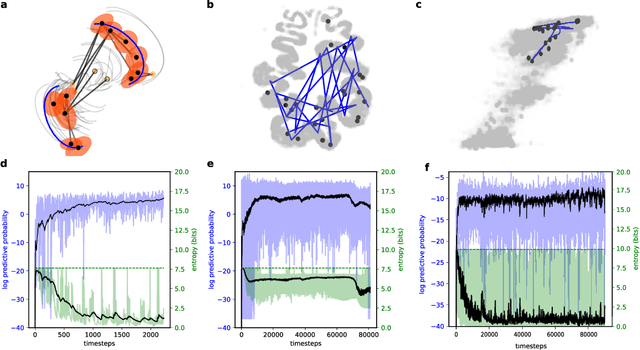
While most classic studies of function in experimental neuroscience have focused on the coding properties of individual neurons, recent developments in recording technologies have resulted in an increasing emphasis on the dynamics of neural populations. This has given rise to a wide variety of models for analyzing population activity in relation to experimental variables, but direct testing of many neural population hypotheses requires intervening in the system based on current neural state, necessitating models capable of inferring neural state online. Existing approaches, primarily based on dynamical systems, require strong parametric assumptions that are easily violated in the noise-dominated regime and do not scale well to the thousands of data channels in modern experiments. To address this problem, we propose a method that combines fast, stable dimensionality reduction with a soft tiling of the resulting neural manifold, allowing dynamics to be approximated as a probability flow between tiles. This method can be fit efficiently using online expectation maximization, scales to tens of thousands of tiles, and outperforms existing methods when dynamics are noise-dominated or feature multi-modal transition probabilities. The resulting model can be trained at kiloHertz data rates, produces accurate approximations of neural dynamics within minutes, and generates predictions on submillisecond time scales. It retains predictive performance throughout many time steps into the future and is fast enough to serve as a component of closed-loop causal experiments.
A Goal-Based Movement Model for Continuous Multi-Agent Tasks
Oct 31, 2017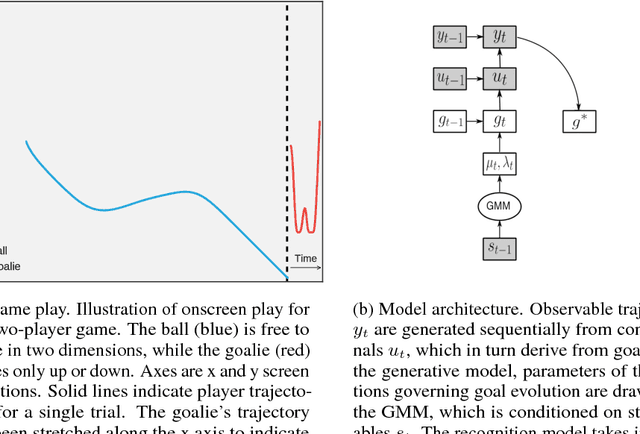
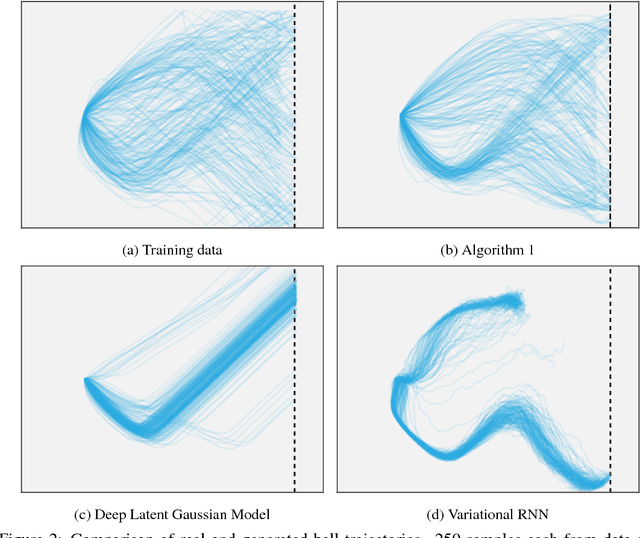
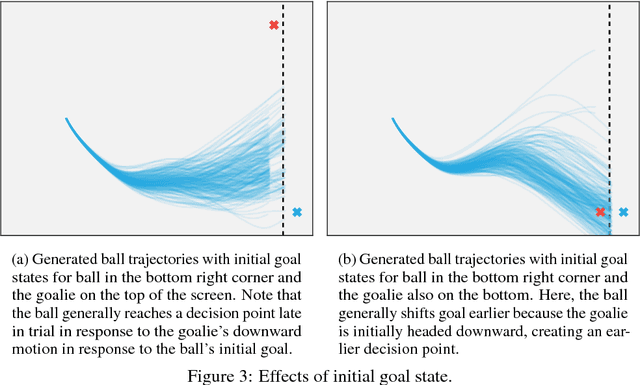
Despite increasing attention paid to the need for fast, scalable methods to analyze next-generation neuroscience data, comparatively little attention has been paid to the development of similar methods for behavioral analysis. Just as the volume and complexity of brain data have grown, behavioral paradigms in systems neuroscience have likewise become more naturalistic and less constrained, necessitating an increase in the flexibility and scalability of the models used to study them. In particular, key assumptions made in the analysis of typical decision paradigms --- optimality; analytic tractability; discrete, low-dimensional action spaces --- may be untenable in richer tasks. Here, using the case of a two-player, real-time, continuous strategic game as an example, we show how the use of modern machine learning methods allows us to relax each of these assumptions. Following an inverse reinforcement learning approach, we are able to succinctly characterize the joint distribution over players' actions via a generative model that allows us to simulate realistic game play. We compare simulated play from a number of generative time series models and show that ours successfully resists mode collapse while generating trajectories with the rich variability of real behavior. Together, these methods offer a rich class of models for the analysis of continuous action tasks at the single-trial level.