 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Extractive Abstractive Summarization for Multilingual Sentiment Analysis
Jun 07, 2025We propose a hybrid approach for multilingual sentiment analysis that combines extractive and abstractive summarization to address the limitations of standalone methods. The model integrates TF-IDF-based extraction with a fine-tuned XLM-R abstractive module, enhanced by dynamic thresholding and cultural adaptation. Experiments across 10 languages show significant improvements over baselines, achieving 0.90 accuracy for English and 0.84 for low-resource languages. The approach also demonstrates 22% greater computational efficiency than traditional methods. Practical applications include real-time brand monitoring and cross-cultural discourse analysis. Future work will focus on optimization for low-resource languages via 8-bit quantization.
Multilingual Sentiment Analysis of Summarized Texts: A Cross-Language Study of Text Shortening Effects
Mar 31, 2025Summarization significantly impacts sentiment analysis across languages with diverse morphologies. This study examines extractive and abstractive summarization effects on sentiment classification in English, German, French, Spanish, Italian, Finnish, Hungarian, and Arabic. We assess sentiment shifts post-summarization using multilingual transformers (mBERT, XLM-RoBERTa, T5, and BART) and language-specific models (FinBERT, AraBERT). Results show extractive summarization better preserves sentiment, especially in morphologically complex languages, while abstractive summarization improves readability but introduces sentiment distortion, affecting sentiment accuracy. Languages with rich inflectional morphology, such as Finnish, Hungarian, and Arabic, experience greater accuracy drops than English or German. Findings emphasize the need for language-specific adaptations in sentiment analysis and propose a hybrid summarization approach balancing readability and sentiment preservation. These insights benefit multilingual sentiment applications, including social media monitoring, market analysis, and cross-lingual opinion mining.
Advancing Sentiment Analysis in Tamil-English Code-Mixed Texts: Challenges and Transformer-Based Solutions
Mar 30, 2025
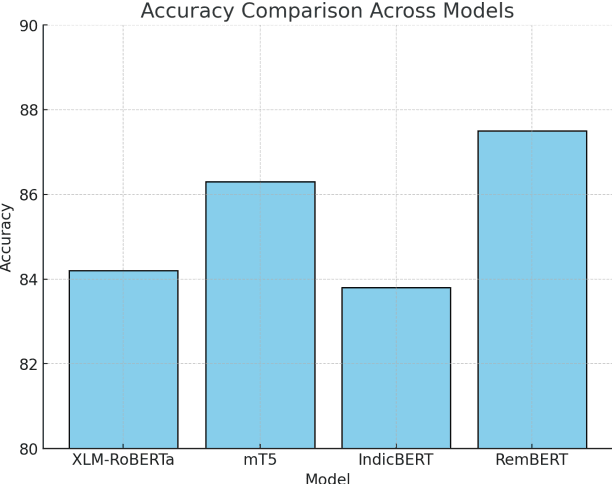


The sentiment analysis task in Tamil-English code-mixed texts has been explored using advanced transformer-based models. Challenges from grammatical inconsistencies, orthographic variations, and phonetic ambiguities have been addressed. The limitations of existing datasets and annotation gaps have been examined, emphasizing the need for larger and more diverse corpora. Transformer architectures, including XLM-RoBERTa, mT5, IndicBERT, and RemBERT, have been evaluated in low-resource, code-mixed environments. Performance metrics have been analyzed, highlighting the effectiveness of specific models in handling multilingual sentiment classification. The findings suggest that further advancements in data augmentation, phonetic normalization, and hybrid modeling approaches are required to enhance accuracy. Future research directions for improving sentiment analysis in code-mixed texts have been proposed.