 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Continuous Docking Control of Autonomous Underwater Vehicles: A Benchmarking Study
Aug 05, 2021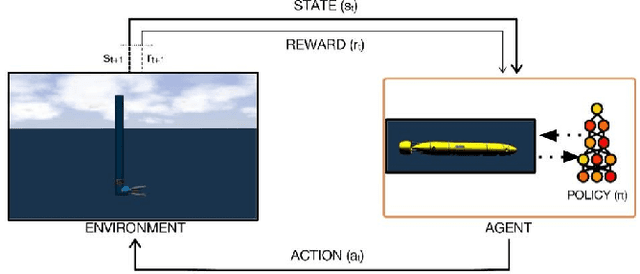
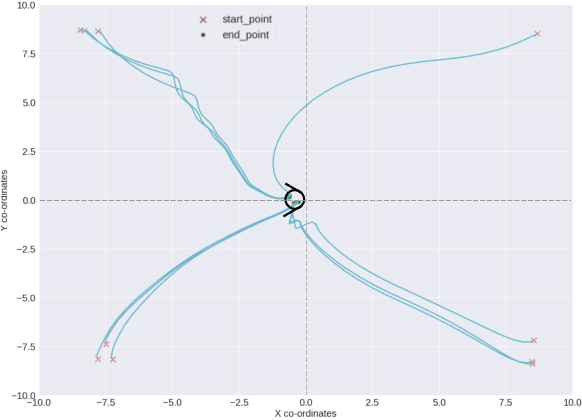
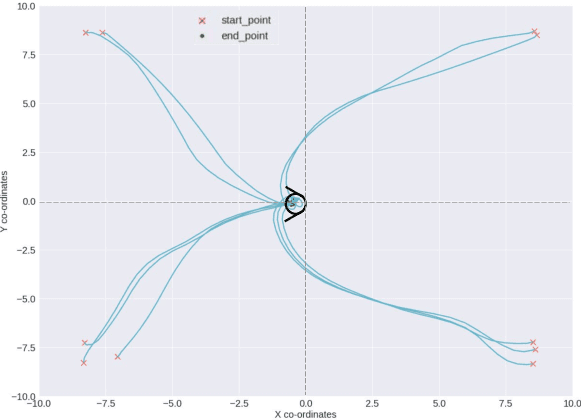
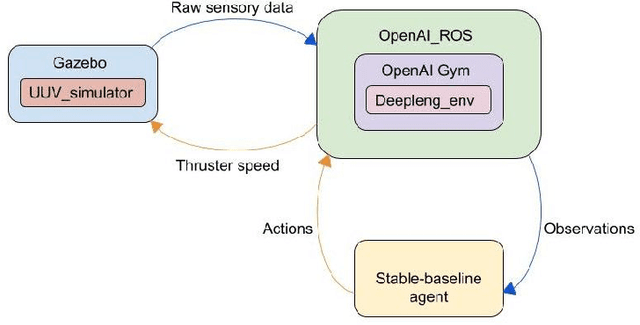
Docking control of an autonomous underwater vehicle (AUV) is a task that is integral to achieving persistent long term autonomy. This work explores the application of state-of-the-art model-free deep reinforcement learning (DRL) approaches to the task of AUV docking in the continuous domain. We provide a detailed formulation of the reward function, utilized to successfully dock the AUV onto a fixed docking platform. A major contribution that distinguishes our work from the previous approaches is the usage of a physics simulator to define and simulate the underwater environment as well as the DeepLeng AUV. We propose a new reward function formulation for the docking task, incorporating several components, that outperforms previous reward formulations. We evaluate proximal policy optimization (PPO), twin delayed deep deterministic policy gradients (TD3) and soft actor-critic (SAC) in combination with our reward function. Our evaluation yielded results that conclusively show the TD3 agent to be most efficient and consistent in terms of docking the AUV, over multiple evaluation runs it achieved a 100% success rate and episode return of 10667.1 +- 688.8. We also show how our reward function formulation improves over the state of the art.