 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroFabric: Identifying Ideal Topologies for Training A Priori Sparse Networks
Feb 19, 2020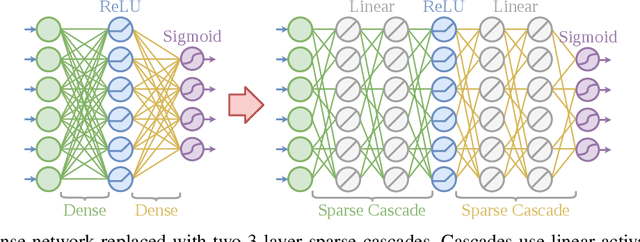
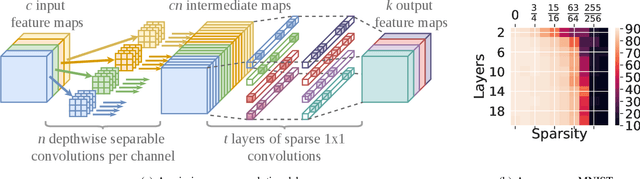

Long training times of deep neural networks are a bottleneck in machine learning research. The major impediment to fast training is the quadratic growth of both memory and compute requirements of dense and convolutional layers with respect to their information bandwidth. Recently, training `a priori' sparse networks has been proposed as a method for allowing layers to retain high information bandwidth, while keeping memory and compute low. However, the choice of which sparse topology should be used in these networks is unclear. In this work, we provide a theoretical foundation for the choice of intra-layer topology. First, we derive a new sparse neural network initialization scheme that allows us to explore the space of very deep sparse networks. Next, we evaluate several topologies and show that seemingly similar topologies can often have a large difference in attainable accuracy. To explain these differences, we develop a data-free heuristic that can evaluate a topology independently from the dataset the network will be trained on. We then derive a set of requirements that make a good topology, and arrive at a single topology that satisfies all of them.
Survey of Attacks and Defenses on Edge-Deployed Neural Networks
Nov 27, 2019
Deep Neural Network (DNN) workloads are quickly moving from datacenters onto edge devices, for latency, privacy, or energy reasons. While datacenter networks can be protected using conventional cybersecurity measures, edge neural networks bring a host of new security challenges. Unlike classic IoT applications, edge neural networks are typically very compute and memory intensive, their execution is data-independent, and they are robust to noise and faults. Neural network models may be very expensive to develop, and can potentially reveal information about the private data they were trained on, requiring special care in distribution. The hidden states and outputs of the network can also be used in reconstructing user inputs, potentially violating users' privacy. Furthermore, neural networks are vulnerable to adversarial attacks, which may cause misclassifications and violate the integrity of the output. These properties add challenges when securing edge-deployed DNNs, requiring new considerations, threat models, priorities, and approaches in securely and privately deploying DNNs to the edge. In this work, we cover the landscape of attacks on, and defenses, of neural networks deployed in edge devices and provide a taxonomy of attacks and defenses targeting edge DNNs.
ClosNets: a Priori Sparse Topologies for Faster DNN Training
Feb 12, 2018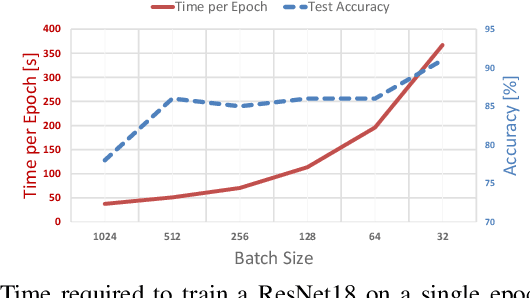

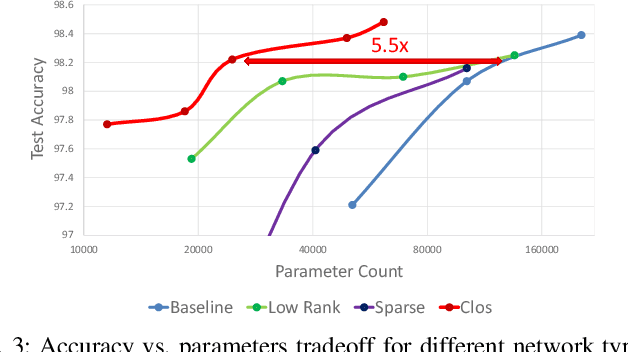
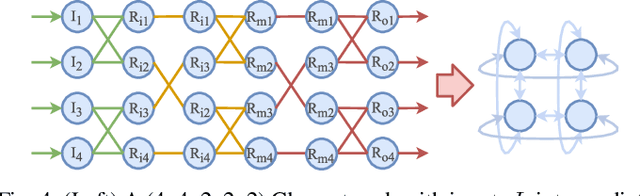
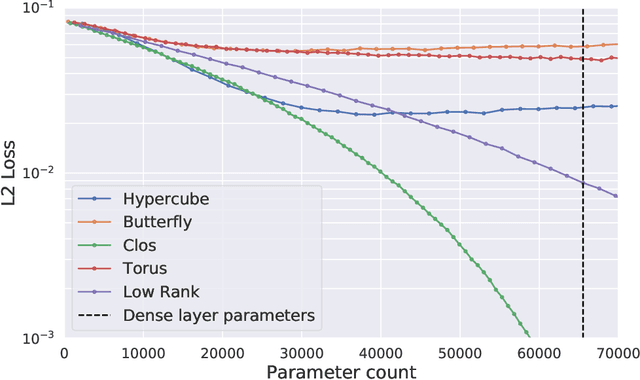
Fully-connected layers in deep neural networks (DNN) are often the throughput and power bottleneck during training. This is due to their large size and low data reuse. Pruning dense layers can significantly reduce the size of these networks, but this approach can only be applied after training. In this work we propose a novel fully-connected layer that reduces the memory requirements of DNNs without sacrificing accuracy. We replace a dense matrix with products of sparse matrices whose topologies we pick in advance. This allows us to: (1) train significantly smaller networks without a loss in accuracy, and (2) store the network weights without having to store connection indices. We therefore achieve significant training speedups due to the smaller network size, and a reduced amount of computation per epoch. We tested several sparse layer topologies and found that Clos networks perform well due to their high path diversity, shallowness, and high model accuracy. With the ClosNets, we are able to reduce dense layer sizes by as much as an order of magnitude without hurting model accuracy.