 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-IDS: Generative Adversarial Networks Assisted Intrusion Detection System
Jun 01, 2020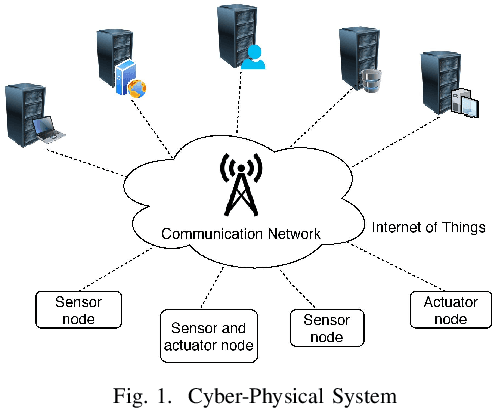
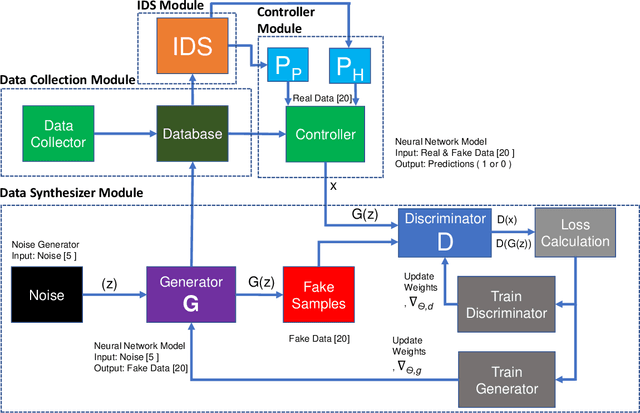
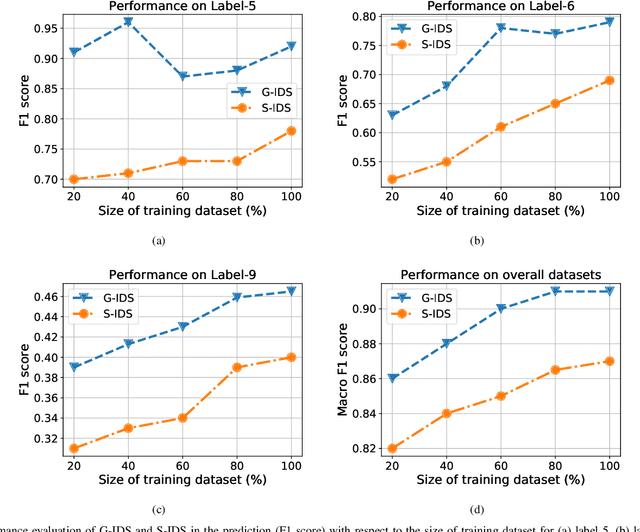
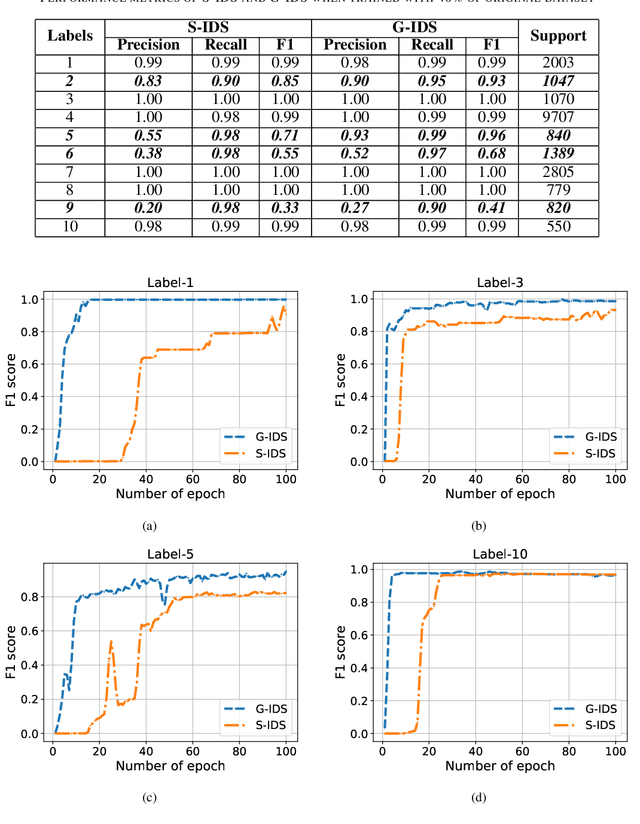
The boundaries of cyber-physical systems (CPS) and the Internet of Things (IoT) are converging together day by day to introduce a common platform on hybrid systems. Moreover, the combination of artificial intelligence (AI) with CPS creates a new dimension of technological advancement. All these connectivity and dependability are creating massive space for the attackers to launch cyber attacks. To defend against these attacks, intrusion detection system (IDS) has been widely used. However, emerging CPS technologies suffer from imbalanced and missing sample data, which makes the training of IDS difficult. In this paper, we propose a generative adversarial network (GAN) based intrusion detection system (G-IDS), where GAN generates synthetic samples, and IDS gets trained on them along with the original ones. G-IDS also fixes the difficulties of imbalanced or missing data problems. We model a network security dataset for an emerging CPS using NSL KDD-99 dataset and evaluate our proposed model's performance using different metrics. We find that our proposed G-IDS model performs much better in attack detection and model stabilization during the training process than a standalone IDS.
Y-GAN: A Generative Adversarial Network for Depthmap Estimation from Multi-camera Stereo Images
Jun 03, 2019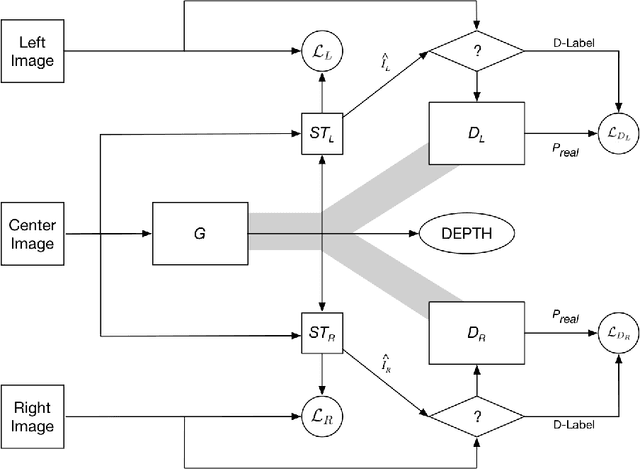
Depth perception is a key component for autonomous systems that interact in the real world, such as delivery robots, warehouse robots, and self-driving cars. Tasks in autonomous robotics such as 3D object recognition, simultaneous localization and mapping (SLAM), path planning and navigation, require some form of 3D spatial information. Depth perception is a long-standing research problem in computer vision and robotics and has had a long history. Many approaches using deep learning, ranging from structure from motion, shape-from-X, monocular, binocular, and multi-view stereo, have yielded acceptable results. However, there are several shortcomings of these methods such as requiring expensive hardware, needing supervised training data, no ground truth data for comparison, and disregard for occlusion. In order to address these shortcomings, this work proposes a new deep convolutional generative adversarial network architecture, called Y-GAN, that uses data from three cameras to estimate a depth map for each frame in a multi-camera video stream.
Learning User Preferences via Reinforcement Learning with Spatial Interface Valuing
Feb 02, 2019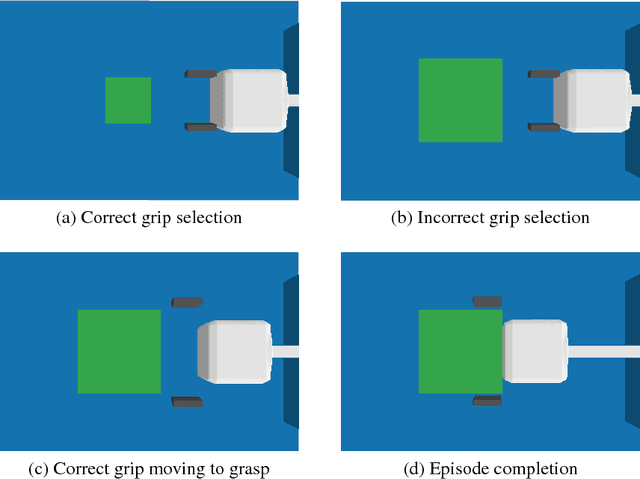



Interactive Machine Learning is concerned with creating systems that operate in environments alongside humans to achieve a task. A typical use is to extend or amplify the capabilities of a human in cognitive or physical ways, requiring the machine to adapt to the users' intentions and preferences. Often, this takes the form of a human operator providing some type of feedback to the user, which can be explicit feedback, implicit feedback, or a combination of both. Explicit feedback, such as through a mouse click, carries a high cognitive load. The focus of this study is to extend the current state of the art in interactive machine learning by demonstrating that agents can learn a human user's behavior and adapt to preferences with a reduced amount of explicit human feedback in a mixed feedback setting. The learning agent perceives a value of its own behavior from hand gestures given via a spatial interface. This feedback mechanism is termed Spatial Interface Valuing. This method is evaluated experimentally in a simulated environment for a grasping task using a robotic arm with variable grip settings. Preliminary results indicate that learning agents using spatial interface valuing can learn a value function mapping spatial gestures to expected future rewards much more quickly as compared to those same agents just receiving explicit feedback, demonstrating that an agent perceiving feedback from a human user via a spatial interface can serve as an effective complement to existing approaches.