 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeY-GAN: A Generative Adversarial Network for Depthmap Estimation from Multi-camera Stereo Images
Paper and Code
Jun 03, 2019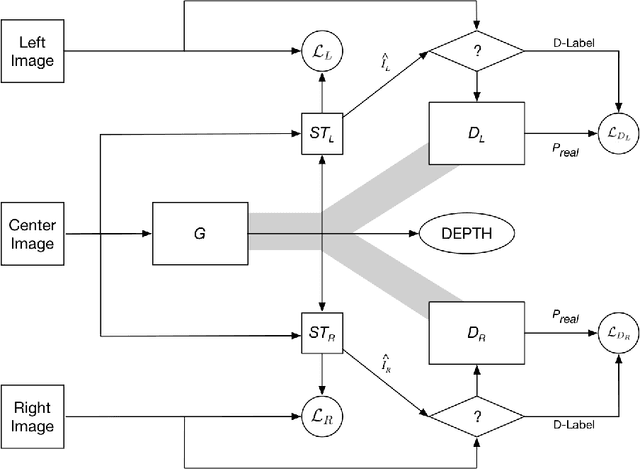
Depth perception is a key component for autonomous systems that interact in the real world, such as delivery robots, warehouse robots, and self-driving cars. Tasks in autonomous robotics such as 3D object recognition, simultaneous localization and mapping (SLAM), path planning and navigation, require some form of 3D spatial information. Depth perception is a long-standing research problem in computer vision and robotics and has had a long history. Many approaches using deep learning, ranging from structure from motion, shape-from-X, monocular, binocular, and multi-view stereo, have yielded acceptable results. However, there are several shortcomings of these methods such as requiring expensive hardware, needing supervised training data, no ground truth data for comparison, and disregard for occlusion. In order to address these shortcomings, this work proposes a new deep convolutional generative adversarial network architecture, called Y-GAN, that uses data from three cameras to estimate a depth map for each frame in a multi-camera video stream.