 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning in Topology-based Representation for Human Body Movement with Whole Arm Manipulation
Sep 12, 2018
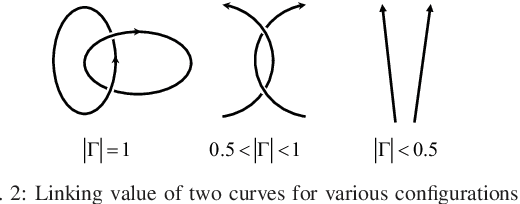
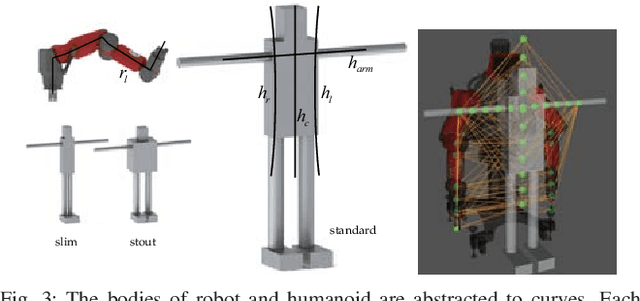
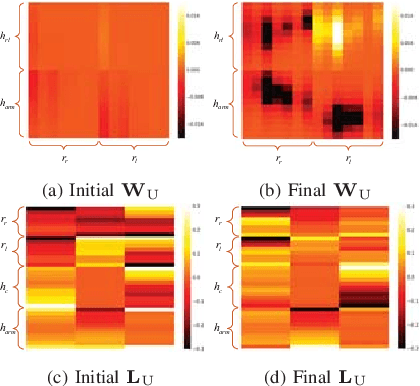
Moving a human body or a large and bulky object can require the strength of whole arm manipulation (WAM). This type of manipulation places the load on the robot's arms and relies on global properties of the interaction to succeed---rather than local contacts such as grasping or non-prehensile pushing. In this paper, we learn to generate motions that enable WAM for holding and transporting of humans in certain rescue or patient care scenarios. We model the task as a reinforcement learning problem in order to provide a behavior that can directly respond to external perturbation and human motion. For this, we represent global properties of the robot-human interaction with topology-based coordinates that are computed from arm and torso positions. These coordinates also allow transferring the learned policy to other body shapes and sizes. For training and evaluation, we simulate a dynamic sea rescue scenario and show in quantitative experiments that the policy can solve unseen scenarios with differently-shaped humans, floating humans, or with perception noise. Our qualitative experiments show the subsequent transporting after holding is achieved and we demonstrate that the policy can be directly transferred to a real world setting.
Rearrangement with Nonprehensile Manipulation Using Deep Reinforcement Learning
Mar 15, 2018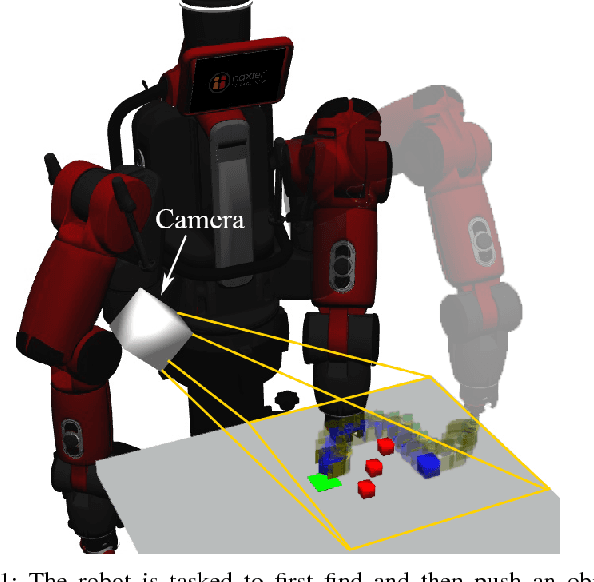
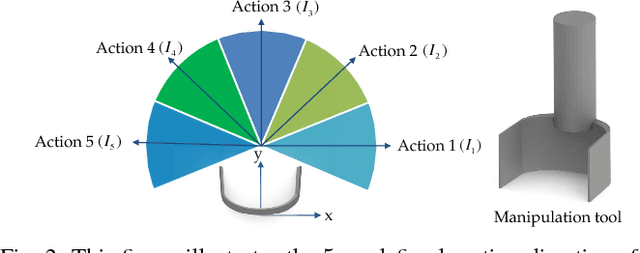
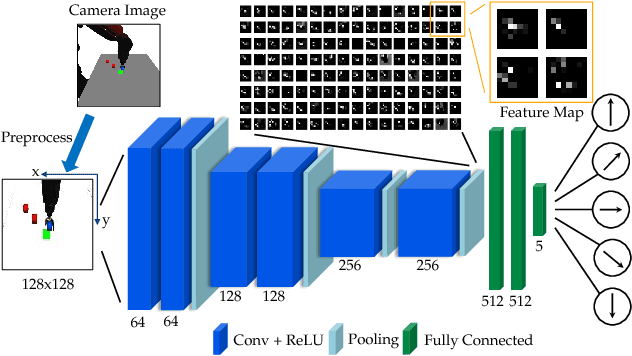
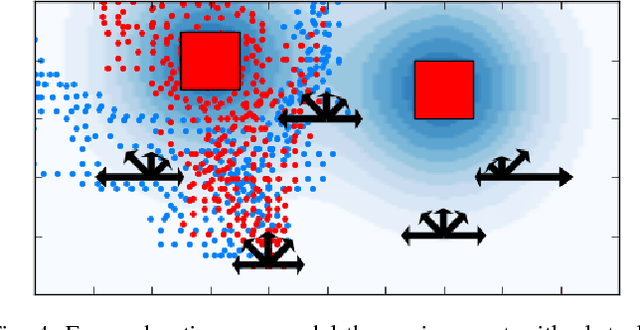
Rearranging objects on a tabletop surface by means of nonprehensile manipulation is a task which requires skillful interaction with the physical world. Usually, this is achieved by precisely modeling physical properties of the objects, robot, and the environment for explicit planning. In contrast, as explicitly modeling the physical environment is not always feasible and involves various uncertainties, we learn a nonprehensile rearrangement strategy with deep reinforcement learning based on only visual feedback. For this, we model the task with rewards and train a deep Q-network. Our potential field-based heuristic exploration strategy reduces the amount of collisions which lead to suboptimal outcomes and we actively balance the training set to avoid bias towards poor examples. Our training process leads to quicker learning and better performance on the task as compared to uniform exploration and standard experience replay. We demonstrate empirical evidence from simulation that our method leads to a success rate of 85%, show that our system can cope with sudden changes of the environment, and compare our performance with human level performance.