 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointExplainer: Towards Transparent Parkinson's Disease Diagnosis
May 04, 2025Deep neural networks have shown potential in analyzing digitized hand-drawn signals for early diagnosis of Parkinson's disease. However, the lack of clear interpretability in existing diagnostic methods presents a challenge to clinical trust. In this paper, we propose PointExplainer, an explainable diagnostic strategy to identify hand-drawn regions that drive model diagnosis. Specifically, PointExplainer assigns discrete attribution values to hand-drawn segments, explicitly quantifying their relative contributions to the model's decision. Its key components include: (i) a diagnosis module, which encodes hand-drawn signals into 3D point clouds to represent hand-drawn trajectories, and (ii) an explanation module, which trains an interpretable surrogate model to approximate the local behavior of the black-box diagnostic model. We also introduce consistency measures to further address the issue of faithfulness in explanations. Extensive experiments on two benchmark datasets and a newly constructed dataset show that PointExplainer can provide intuitive explanations with no diagnostic performance degradation. The source code is available at https://github.com/chaoxuewang/PointExplainer.
LSTM-CNN: An efficient diagnostic network for Parkinson's disease utilizing dynamic handwriting analysis
Nov 20, 2023


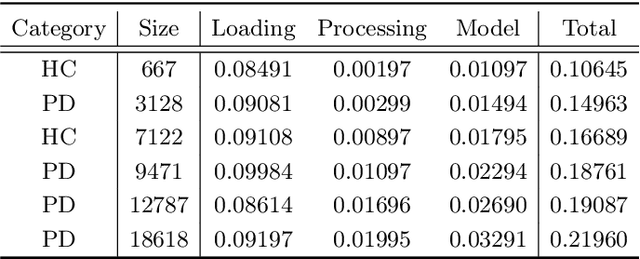
Background and objectives: Dynamic handwriting analysis, due to its non-invasive and readily accessible nature, has recently emerged as a vital adjunctive method for the early diagnosis of Parkinson's disease. In this study, we design a compact and efficient network architecture to analyse the distinctive handwriting patterns of patients' dynamic handwriting signals, thereby providing an objective identification for the Parkinson's disease diagnosis. Methods: The proposed network is based on a hybrid deep learning approach that fully leverages the advantages of both long short-term memory (LSTM) and convolutional neural networks (CNNs). Specifically, the LSTM block is adopted to extract the time-varying features, while the CNN-based block is implemented using one-dimensional convolution for low computational cost. Moreover, the hybrid model architecture is continuously refined under ablation studies for superior performance. Finally, we evaluate the proposed method with its generalization under a five-fold cross-validation, which validates its efficiency and robustness. Results: The proposed network demonstrates its versatility by achieving impressive classification accuracies on both our new DraWritePD dataset ($96.2\%$) and the well-established PaHaW dataset ($90.7\%$). Moreover, the network architecture also stands out for its excellent lightweight design, occupying a mere $0.084$M of parameters, with a total of only $0.59$M floating-point operations. It also exhibits near real-time CPU inference performance, with inference times ranging from $0.106$ to $0.220$s. Conclusions: We present a series of experiments with extensive analysis, which systematically demonstrate the effectiveness and efficiency of the proposed hybrid neural network in extracting distinctive handwriting patterns for precise diagnosis of Parkinson's disease.
Optimal Image Transport on Sparse Dictionaries
Nov 03, 2023



In this paper, we derive a novel optimal image transport algorithm over sparse dictionaries by taking advantage of Sparse Representation (SR) and Optimal Transport (OT). Concisely, we design a unified optimization framework in which the individual image features (color, textures, styles, etc.) are encoded using sparse representation compactly, and an optimal transport plan is then inferred between two learned dictionaries in accordance with the encoding process. This paradigm gives rise to a simple but effective way for simultaneous image representation and transformation, which is also empirically solvable because of the moderate size of sparse coding and optimal transport sub-problems. We demonstrate its versatility and many benefits to different image-to-image translation tasks, in particular image color transform and artistic style transfer, and show the plausible results for photo-realistic transferred effects.
Semi-sparsity Priors for Image Structure Analysis and Extraction
Aug 17, 2023



Image structure-texture decomposition is a long-standing and fundamental problem in both image processing and computer vision fields. In this paper, we propose a generalized semi-sparse regularization framework for image structural analysis and extraction, which allows us to decouple the underlying image structures from complicated textural backgrounds. Combining with different textural analysis models, such a regularization receives favorable properties differing from many traditional methods. We demonstrate that it is not only capable of preserving image structures without introducing notorious staircase artifacts in polynomial-smoothing surfaces but is also applicable for decomposing image textures with strong oscillatory patterns. Moreover, we also introduce an efficient numerical solution based on an alternating direction method of multipliers (ADMM) algorithm, which gives rise to a simple and maneuverable way for image structure-texture decomposition. The versatility of the proposed method is finally verified by a series of experimental results with the capability of producing comparable or superior image decomposition results against cutting-edge methods.
A Light-weight CNN Model for Efficient Parkinson's Disease Diagnostics
Feb 02, 2023



In recent years, deep learning methods have achieved great success in various fields due to their strong performance in practical applications. In this paper, we present a light-weight neural network for Parkinson's disease diagnostics, in which a series of hand-drawn data are collected to distinguish Parkinson's disease patients from healthy control subjects. The proposed model consists of a convolution neural network (CNN) cascading to long-short-term memory (LSTM) to adapt the characteristics of collected time-series signals. To make full use of their advantages, a multilayered LSTM model is firstly used to enrich features which are then concatenated with raw data and fed into a shallow one-dimensional (1D) CNN model for efficient classification. Experimental results show that the proposed model achieves a high-quality diagnostic result over multiple evaluation metrics with much fewer parameters and operations, outperforming conventional methods such as support vector machine (SVM), random forest (RF), lightgbm (LGB) and CNN-based methods.
Semi-Sparsity for Smoothing Filters
Jul 24, 2021


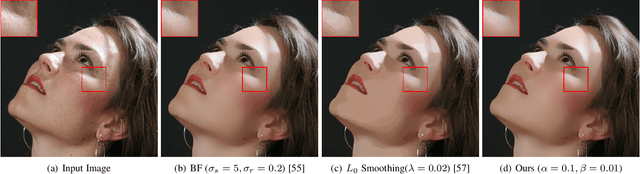
In this paper, we propose an interesting semi-sparsity smoothing algorithm based on a novel sparsity-inducing optimization framework. This method is derived from the multiple observations, that is, semi-sparsity prior knowledge is more universally applicable, especially in areas where sparsity is not fully admitted, such as polynomial-smoothing surfaces. We illustrate that this semi-sparsity can be identified into a generalized $L_0$-norm minimization in higher-order gradient domains, thereby giving rise to a new "feature-aware" filtering method with a powerful simultaneous-fitting ability in both sparse features (singularities and sharpening edges) and non-sparse regions (polynomial-smoothing surfaces). Notice that a direct solver is always unavailable due to the non-convexity and combinatorial nature of $L_0$-norm minimization. Instead, we solve the model based on an efficient half-quadratic splitting minimization with fast Fourier transforms (FFTs) for acceleration. We finally demonstrate its versatility and many benefits to a series of signal/image processing and computer vision applications.
Intrinsic Image Transfer for Illumination Manipulation
Jul 01, 2021



This paper presents a novel intrinsic image transfer (IIT) algorithm for illumination manipulation, which creates a local image translation between two illumination surfaces. This model is built on an optimization-based framework consisting of three photo-realistic losses defined on the sub-layers factorized by an intrinsic image decomposition. We illustrate that all losses can be reduced without the necessity of taking an intrinsic image decomposition under the well-known spatial-varying illumination illumination-invariant reflectance prior knowledge. Moreover, with a series of relaxations, all of them can be directly defined on images, giving a closed-form solution for image illumination manipulation. This new paradigm differs from the prevailing Retinex-based algorithms, as it provides an implicit way to deal with the per-pixel image illumination. We finally demonstrate its versatility and benefits to the illumination-related tasks such as illumination compensation, image enhancement, and high dynamic range (HDR) image compression, and show the high-quality results on natural image datasets.