 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Predictions on Highly Unbalanced Data Using Open Source Synthetic Data Upsampling
Jul 22, 2025



Unbalanced tabular data sets present significant challenges for predictive modeling and data analysis across a wide range of applications. In many real-world scenarios, such as fraud detection, medical diagnosis, and rare event prediction, minority classes are vastly underrepresented, making it difficult for traditional machine learning algorithms to achieve high accuracy. These algorithms tend to favor the majority class, leading to biased models that struggle to accurately represent minority classes. Synthetic data holds promise for addressing the under-representation of minority classes by providing new, diverse, and highly realistic samples. This paper presents a benchmark study on the use of AI-generated synthetic data for upsampling highly unbalanced tabular data sets. We evaluate the effectiveness of an open-source solution, the Synthetic Data SDK by MOSTLY AI, which provides a flexible and user-friendly approach to synthetic upsampling for mixed-type data. We compare predictive models trained on data sets upsampled with synthetic records to those using standard methods, such as naive oversampling and SMOTE-NC. Our results demonstrate that synthetic data can improve predictive accuracy for minority groups by generating diverse data points that fill gaps in sparse regions of the feature space. We show that upsampled synthetic training data consistently results in top-performing predictive models, particularly for mixed-type data sets containing very few minority samples.
Benchmarking Synthetic Tabular Data: A Multi-Dimensional Evaluation Framework
Apr 02, 2025Evaluating the quality of synthetic data remains a key challenge for ensuring privacy and utility in data-driven research. In this work, we present an evaluation framework that quantifies how well synthetic data replicates original distributional properties while ensuring privacy. The proposed approach employs a holdout-based benchmarking strategy that facilitates quantitative assessment through low- and high-dimensional distribution comparisons, embedding-based similarity measures, and nearest-neighbor distance metrics. The framework supports various data types and structures, including sequential and contextual information, and enables interpretable quality diagnostics through a set of standardized metrics. These contributions aim to support reproducibility and methodological consistency in benchmarking of synthetic data generation techniques. The code of the framework is available at https://github.com/mostly-ai/mostlyai-qa.
TabularARGN: A Flexible and Efficient Auto-Regressive Framework for Generating High-Fidelity Synthetic Data
Jan 21, 2025Synthetic data generation for tabular datasets must balance fidelity, efficiency, and versatility to meet the demands of real-world applications. We introduce the Tabular Auto-Regressive Generative Network (TabularARGN), a flexible framework designed to handle mixed-type, multivariate, and sequential datasets. By training on all possible conditional probabilities, TabularARGN supports advanced features such as fairness-aware generation, imputation, and conditional generation on any subset of columns. The framework achieves state-of-the-art synthetic data quality while significantly reducing training and inference times, making it ideal for large-scale datasets with diverse structures. Evaluated across established benchmarks, including realistic datasets with complex relationships, TabularARGN demonstrates its capability to synthesize high-quality data efficiently. By unifying flexibility and performance, this framework paves the way for practical synthetic data generation across industries.
Strong statistical parity through fair synthetic data
Nov 06, 2023AI-generated synthetic data, in addition to protecting the privacy of original data sets, allows users and data consumers to tailor data to their needs. This paper explores the creation of synthetic data that embodies Fairness by Design, focusing on the statistical parity fairness definition. By equalizing the learned target probability distributions of the synthetic data generator across sensitive attributes, a downstream model trained on such synthetic data provides fair predictions across all thresholds, that is, strong fair predictions even when inferring from biased, original data. This fairness adjustment can be either directly integrated into the sampling process of a synthetic generator or added as a post-processing step. The flexibility allows data consumers to create fair synthetic data and fine-tune the trade-off between accuracy and fairness without any previous assumptions on the data or re-training the synthetic data generator.
Rule-adhering synthetic data -- the lingua franca of learning
Sep 12, 2022

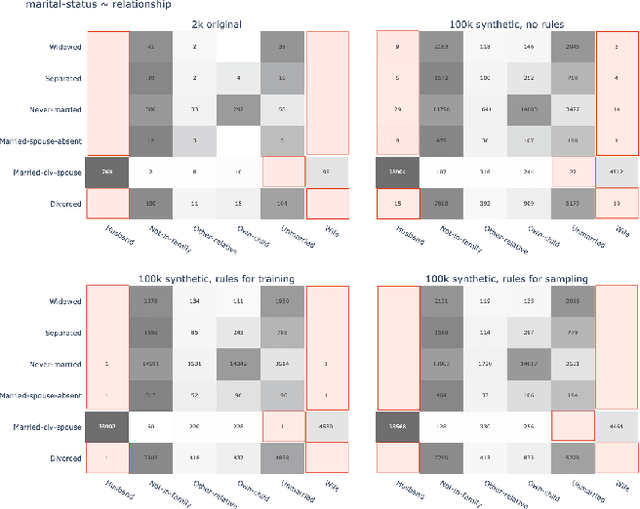

AI-generated synthetic data allows to distill the general patterns of existing data, that can then be shared safely as granular-level representative, yet novel data samples within the original semantics. In this work we explore approaches of incorporating domain expertise into the data synthesis, to have the statistical properties as well as pre-existing domain knowledge of rules be represented. The resulting synthetic data generator, that can be probed for any number of new samples, can then serve as a common source of intelligence, as a lingua franca of learning, consumable by humans and machines alike. We demonstrate the concept for a publicly available data set, and evaluate its benefits via descriptive analysis as well as a downstream ML model.
AI-based Re-identification of Behavioral Clickstream Data
Jan 21, 2022



AI-based face recognition, i.e., the re-identification of individuals within images, is an already well established technology for video surveillance, for user authentication, for tagging photos of friends, etc. This paper demonstrates that similar techniques can be applied to successfully re-identify individuals purely based on their behavioral patterns. In contrast to de-anonymization attacks based on record linkage, these methods do not require any overlap in data points between a released dataset and an identified auxiliary dataset. The mere resemblance of behavioral patterns between records is sufficient to correctly attribute behavioral data to identified individuals. Further, we can demonstrate that data perturbation does not provide protection, unless a significant share of data utility is being destroyed. These findings call for sincere cautions when sharing actual behavioral data with third parties, as modern-day privacy regulations, like the GDPR, define their scope based on the ability to re-identify. This has also strong implications for the Marketing domain, when dealing with potentially re-identify-able data sources like shopping behavior, clickstream data or cockies. We also demonstrate how synthetic data can offer a viable alternative, that is shown to be resilient against our introduced AI-based re-identification attacks.
Holdout-Based Fidelity and Privacy Assessment of Mixed-Type Synthetic Data
Apr 01, 2021

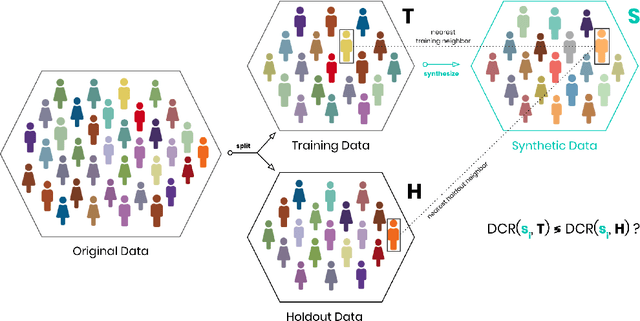

AI-based data synthesis has seen rapid progress over the last several years, and is increasingly recognized for its promise to enable privacy-respecting high-fidelity data sharing. However, adequately evaluating the quality of generated synthetic datasets is still an open challenge. We introduce and demonstrate a holdout-based empirical assessment framework for quantifying the fidelity as well as the privacy risk of synthetic data solutions for mixed-type tabular data. Measuring fidelity is based on statistical distances of lower-dimensional marginal distributions, which provide a model-free and easy-to-communicate empirical metric for the representativeness of a synthetic dataset. Privacy risk is assessed by calculating the individual-level distances to closest record with respect to the training data. By showing that the synthetic samples are just as close to the training as to the holdout data, we yield strong evidence that the synthesizer indeed learned to generalize patterns and is independent of individual training records. We demonstrate the presented framework for seven distinct synthetic data solutions across four mixed-type datasets and compare these to more traditional statistical disclosure techniques. The results highlight the need to systematically assess the fidelity just as well as the privacy of these emerging class of synthetic data generators.