 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing Tabular Data Access with an Open$\unicode{x2013}$Source Synthetic$\unicode{x2013}$Data SDK
Aug 01, 2025Machine learning development critically depends on access to high-quality data. However, increasing restrictions due to privacy, proprietary interests, and ethical concerns have created significant barriers to data accessibility. Synthetic data offers a viable solution by enabling safe, broad data usage without compromising sensitive information. This paper presents the MOSTLY AI Synthetic Data Software Development Kit (SDK), an open-source toolkit designed specifically for synthesizing high-quality tabular data. The SDK integrates robust features such as differential privacy guarantees, fairness-aware data generation, and automated quality assurance into a flexible and accessible Python interface. Leveraging the TabularARGN autoregressive framework, the SDK supports diverse data types and complex multi-table and sequential datasets, delivering competitive performance with notable improvements in speed and usability. Currently deployed both as a cloud service and locally installable software, the SDK has seen rapid adoption, highlighting its practicality in addressing real-world data bottlenecks and promoting widespread data democratization.
Improving Predictions on Highly Unbalanced Data Using Open Source Synthetic Data Upsampling
Jul 22, 2025



Unbalanced tabular data sets present significant challenges for predictive modeling and data analysis across a wide range of applications. In many real-world scenarios, such as fraud detection, medical diagnosis, and rare event prediction, minority classes are vastly underrepresented, making it difficult for traditional machine learning algorithms to achieve high accuracy. These algorithms tend to favor the majority class, leading to biased models that struggle to accurately represent minority classes. Synthetic data holds promise for addressing the under-representation of minority classes by providing new, diverse, and highly realistic samples. This paper presents a benchmark study on the use of AI-generated synthetic data for upsampling highly unbalanced tabular data sets. We evaluate the effectiveness of an open-source solution, the Synthetic Data SDK by MOSTLY AI, which provides a flexible and user-friendly approach to synthetic upsampling for mixed-type data. We compare predictive models trained on data sets upsampled with synthetic records to those using standard methods, such as naive oversampling and SMOTE-NC. Our results demonstrate that synthetic data can improve predictive accuracy for minority groups by generating diverse data points that fill gaps in sparse regions of the feature space. We show that upsampled synthetic training data consistently results in top-performing predictive models, particularly for mixed-type data sets containing very few minority samples.
TabularARGN: A Flexible and Efficient Auto-Regressive Framework for Generating High-Fidelity Synthetic Data
Jan 21, 2025Synthetic data generation for tabular datasets must balance fidelity, efficiency, and versatility to meet the demands of real-world applications. We introduce the Tabular Auto-Regressive Generative Network (TabularARGN), a flexible framework designed to handle mixed-type, multivariate, and sequential datasets. By training on all possible conditional probabilities, TabularARGN supports advanced features such as fairness-aware generation, imputation, and conditional generation on any subset of columns. The framework achieves state-of-the-art synthetic data quality while significantly reducing training and inference times, making it ideal for large-scale datasets with diverse structures. Evaluated across established benchmarks, including realistic datasets with complex relationships, TabularARGN demonstrates its capability to synthesize high-quality data efficiently. By unifying flexibility and performance, this framework paves the way for practical synthetic data generation across industries.
Strong statistical parity through fair synthetic data
Nov 06, 2023AI-generated synthetic data, in addition to protecting the privacy of original data sets, allows users and data consumers to tailor data to their needs. This paper explores the creation of synthetic data that embodies Fairness by Design, focusing on the statistical parity fairness definition. By equalizing the learned target probability distributions of the synthetic data generator across sensitive attributes, a downstream model trained on such synthetic data provides fair predictions across all thresholds, that is, strong fair predictions even when inferring from biased, original data. This fairness adjustment can be either directly integrated into the sampling process of a synthetic generator or added as a post-processing step. The flexibility allows data consumers to create fair synthetic data and fine-tune the trade-off between accuracy and fairness without any previous assumptions on the data or re-training the synthetic data generator.
Rule-adhering synthetic data -- the lingua franca of learning
Sep 12, 2022

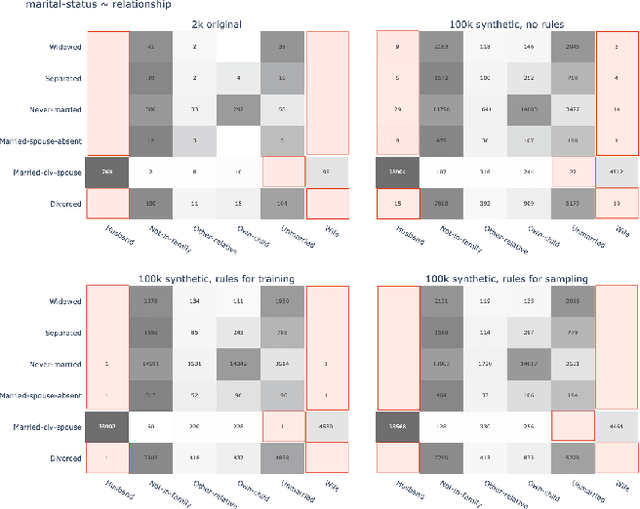

AI-generated synthetic data allows to distill the general patterns of existing data, that can then be shared safely as granular-level representative, yet novel data samples within the original semantics. In this work we explore approaches of incorporating domain expertise into the data synthesis, to have the statistical properties as well as pre-existing domain knowledge of rules be represented. The resulting synthetic data generator, that can be probed for any number of new samples, can then serve as a common source of intelligence, as a lingua franca of learning, consumable by humans and machines alike. We demonstrate the concept for a publicly available data set, and evaluate its benefits via descriptive analysis as well as a downstream ML model.