Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Thesaurus Knowledge and Probabilistic Topic Models
Jul 31, 2017
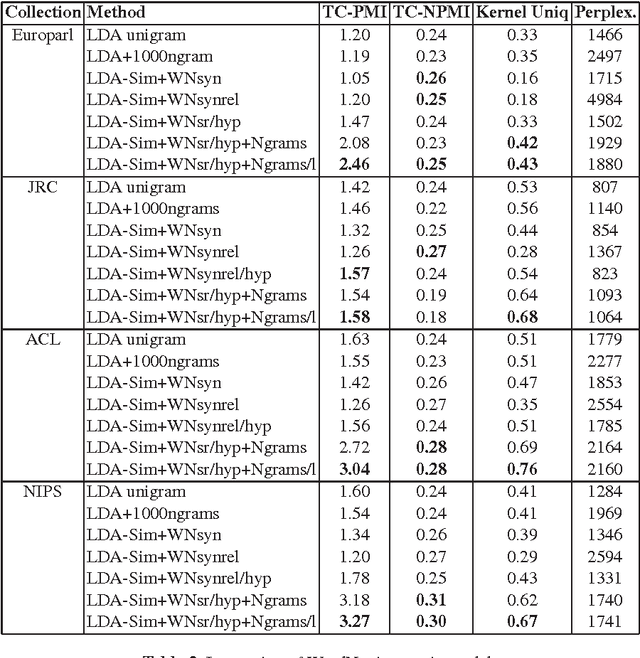
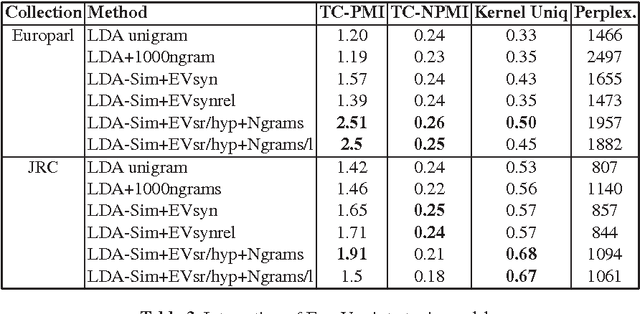

In this paper we present the approach of introducing thesaurus knowledge into probabilistic topic models. The main idea of the approach is based on the assumption that the frequencies of semantically related words and phrases, which are met in the same texts, should be enhanced: this action leads to their larger contribution into topics found in these texts. We have conducted experiments with several thesauri and found that for improving topic models, it is useful to utilize domain-specific knowledge. If a general thesaurus, such as WordNet, is used, the thesaurus-based improvement of topic models can be achieved with excluding hyponymy relations in combined topic models.
* Accepted to AIST-2017 conference (http://aistconf.ru/). The final
publication will be available at link.springer.com
Via