 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations for Unfairness in Anomaly Detection -- Case Studies in Facial Imaging Data
Jul 29, 2024
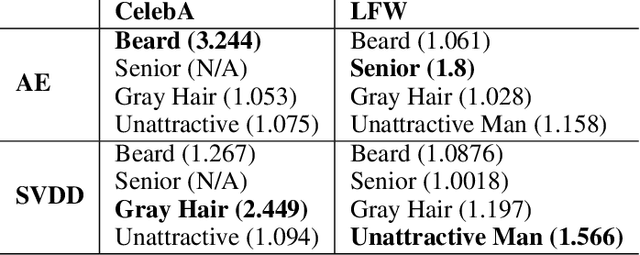
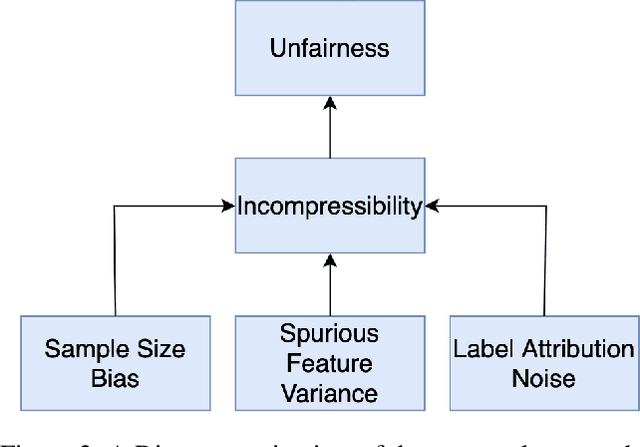
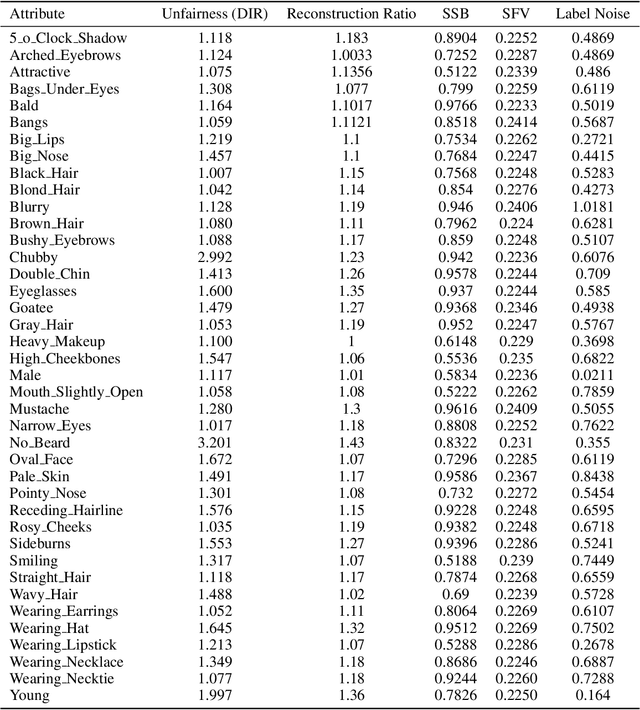
Deep anomaly detection (AD) is perhaps the most controversial of data analytic tasks as it identifies entities that are then specifically targeted for further investigation or exclusion. Also controversial is the application of AI to facial imaging data. This work explores the intersection of these two areas to understand two core questions: "Who" these algorithms are being unfair to and equally important "Why". Recent work has shown that deep AD can be unfair to different groups despite being unsupervised with a recent study showing that for portraits of people: men of color are far more likely to be chosen to be outliers. We study the two main categories of AD algorithms: autoencoder-based and single-class-based which effectively try to compress all the instances with those that can not be easily compressed being deemed to be outliers. We experimentally verify sources of unfairness such as the under-representation of a group (e.g. people of color are relatively rare), spurious group features (e.g. men are often photographed with hats), and group labeling noise (e.g. race is subjective). We conjecture that lack of compressibility is the main foundation and the others cause it but experimental results show otherwise and we present a natural hierarchy amongst them.
Identification and Uses of Deep Learning Backbones via Pattern Mining
Mar 27, 2024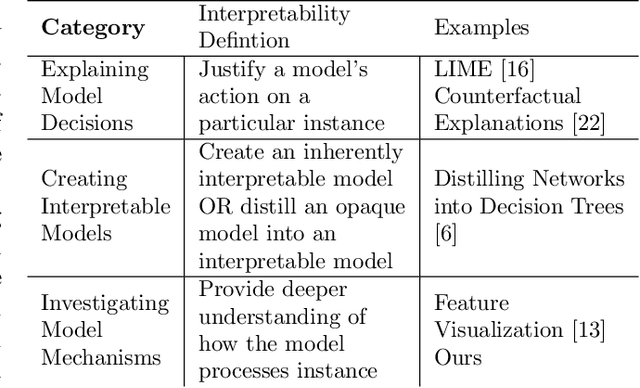
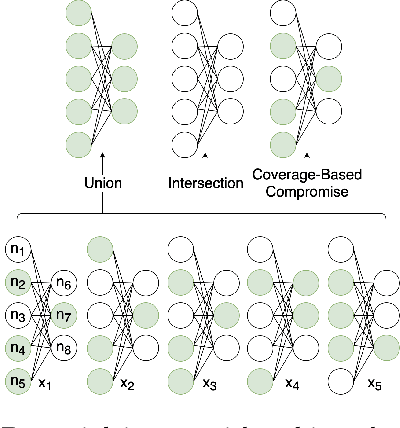
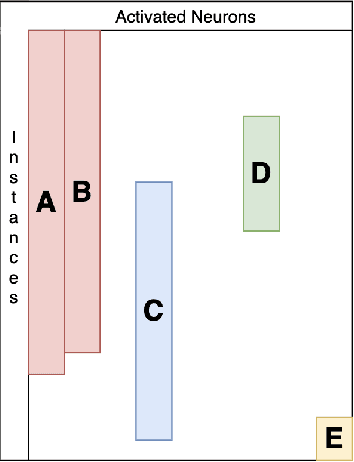
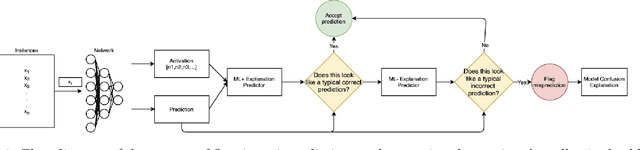
Deep learning is extensively used in many areas of data mining as a black-box method with impressive results. However, understanding the core mechanism of how deep learning makes predictions is a relatively understudied problem. Here we explore the notion of identifying a backbone of deep learning for a given group of instances. A group here can be instances of the same class or even misclassified instances of the same class. We view each instance for a given group as activating a subset of neurons and attempt to find a subgraph of neurons associated with a given concept/group. We formulate this problem as a set cover style problem and show it is intractable and presents a highly constrained integer linear programming (ILP) formulation. As an alternative, we explore a coverage-based heuristic approach related to pattern mining, and show it converges to a Pareto equilibrium point of the ILP formulation. Experimentally we explore these backbones to identify mistakes and improve performance, explanation, and visualization. We demonstrate application-based results using several challenging data sets, including Bird Audio Detection (BAD) Challenge and Labeled Faces in the Wild (LFW), as well as the classic MNIST data.
Cooperative Knowledge Distillation: A Learner Agnostic Approach
Feb 02, 2024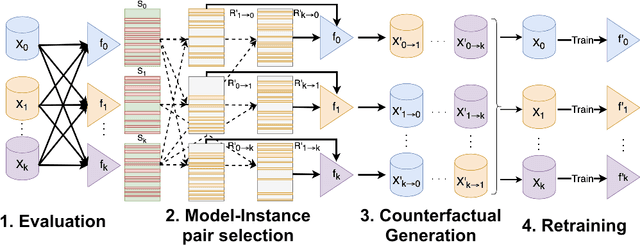
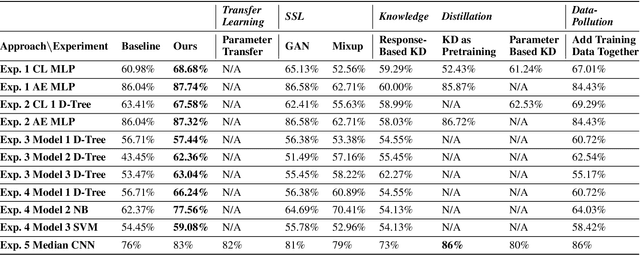
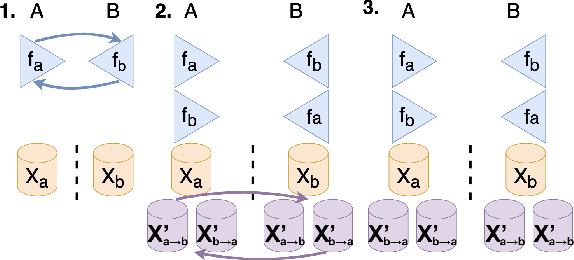
Knowledge distillation is a simple but powerful way to transfer knowledge between a teacher model to a student model. Existing work suffers from at least one of the following key limitations in terms of direction and scope of transfer which restrict its use: all knowledge is transferred from teacher to student regardless of whether or not that knowledge is useful, the student is the only one learning in this exchange, and typically distillation transfers knowledge only from a single teacher to a single student. We formulate a novel form of knowledge distillation in which many models can act as both students and teachers which we call cooperative distillation. The models cooperate as follows: a model (the student) identifies specific deficiencies in it's performance and searches for another model (the teacher) who encodes learned knowledge into instructional virtual instances via counterfactual instance generation. Because different models may have different strengths and weaknesses, all models can act as either students or teachers (cooperation) when appropriate and only distill knowledge in areas specific to their strengths (focus). Since counterfactuals as a paradigm are not tied to any specific algorithm, we can use this method to distill knowledge between learners of different architectures, algorithms, and even feature spaces. We demonstrate that our approach not only outperforms baselines such as transfer learning, self-supervised learning, and multiple knowledge distillation algorithms on several datasets, but it can also be used in settings where the aforementioned techniques cannot.
Explainable Clustering via Exemplars: Complexity and Efficient Approximation Algorithms
Sep 20, 2022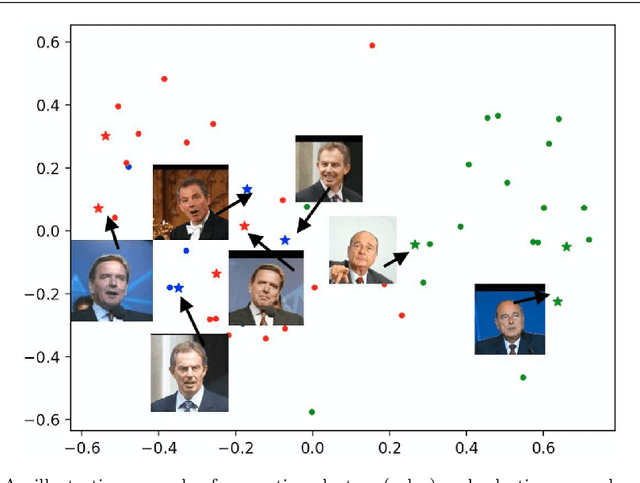

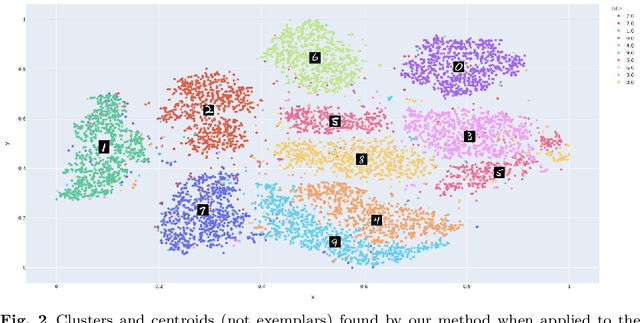
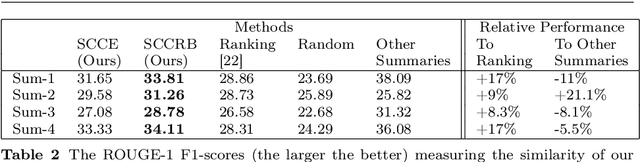
Explainable AI (XAI) is an important developing area but remains relatively understudied for clustering. We propose an explainable-by-design clustering approach that not only finds clusters but also exemplars to explain each cluster. The use of exemplars for understanding is supported by the exemplar-based school of concept definition in psychology. We show that finding a small set of exemplars to explain even a single cluster is computationally intractable; hence, the overall problem is challenging. We develop an approximation algorithm that provides provable performance guarantees with respect to clustering quality as well as the number of exemplars used. This basic algorithm explains all the instances in every cluster whilst another approximation algorithm uses a bounded number of exemplars to allow simpler explanations and provably covers a large fraction of all the instances. Experimental results show that our work is useful in domains involving difficult to understand deep embeddings of images and text.