 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundations for Unfairness in Anomaly Detection -- Case Studies in Facial Imaging Data
Paper and Code
Jul 29, 2024
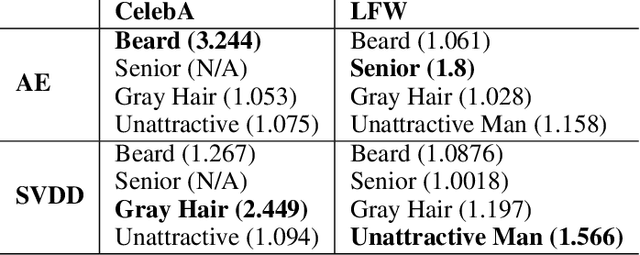
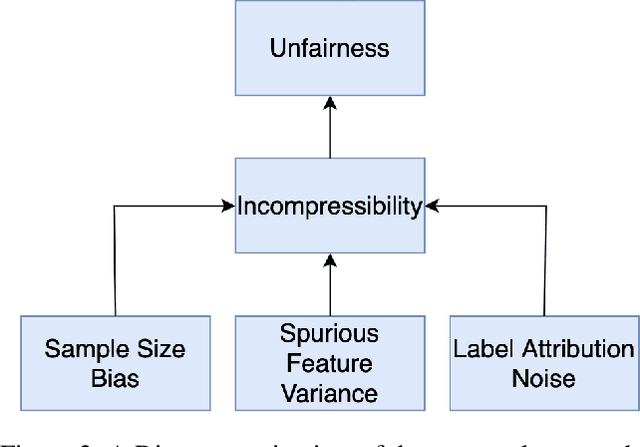
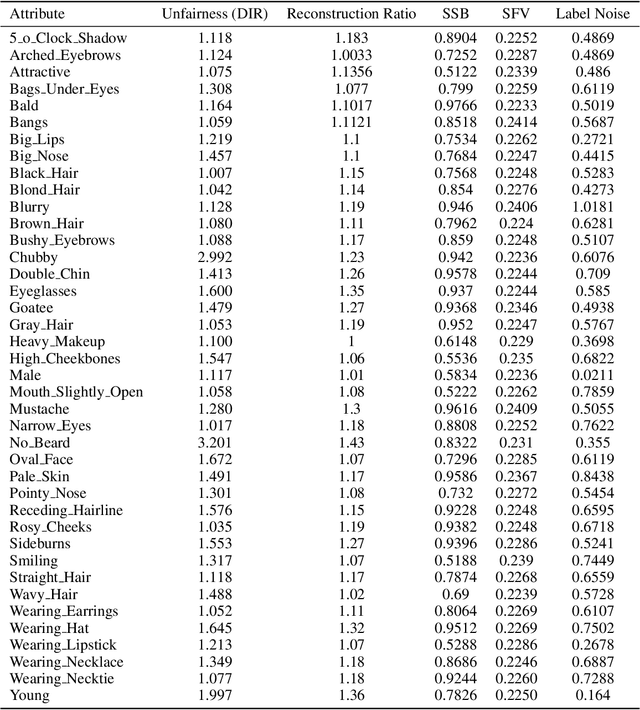
Deep anomaly detection (AD) is perhaps the most controversial of data analytic tasks as it identifies entities that are then specifically targeted for further investigation or exclusion. Also controversial is the application of AI to facial imaging data. This work explores the intersection of these two areas to understand two core questions: "Who" these algorithms are being unfair to and equally important "Why". Recent work has shown that deep AD can be unfair to different groups despite being unsupervised with a recent study showing that for portraits of people: men of color are far more likely to be chosen to be outliers. We study the two main categories of AD algorithms: autoencoder-based and single-class-based which effectively try to compress all the instances with those that can not be easily compressed being deemed to be outliers. We experimentally verify sources of unfairness such as the under-representation of a group (e.g. people of color are relatively rare), spurious group features (e.g. men are often photographed with hats), and group labeling noise (e.g. race is subjective). We conjecture that lack of compressibility is the main foundation and the others cause it but experimental results show otherwise and we present a natural hierarchy amongst them.