 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Stochastic Bandit Algorithms under Probabilistic Unbounded Adversarial Attack
Feb 17, 2020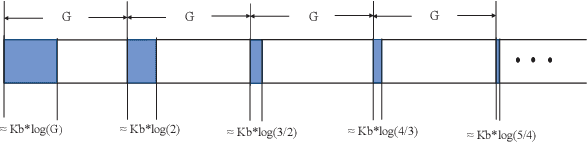
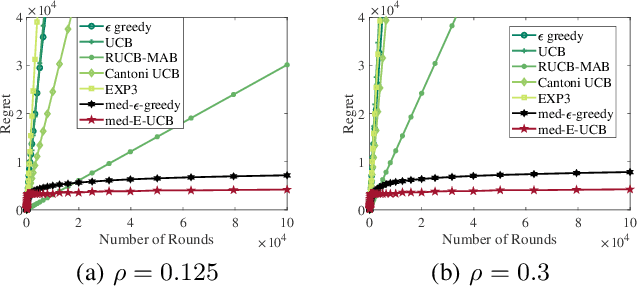
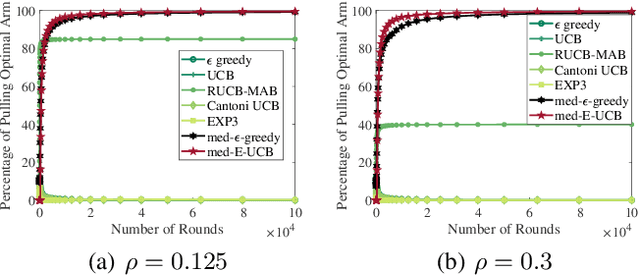
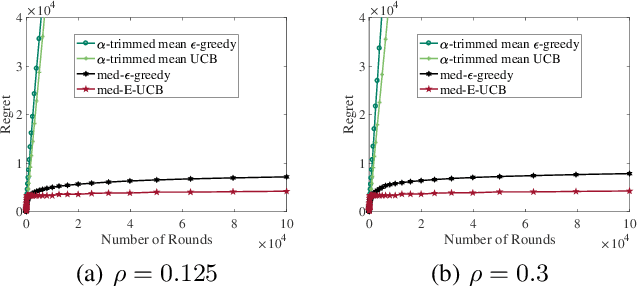
The multi-armed bandit formalism has been extensively studied under various attack models, in which an adversary can modify the reward revealed to the player. Previous studies focused on scenarios where the attack value either is bounded at each round or has a vanishing probability of occurrence. These models do not capture powerful adversaries that can catastrophically perturb the revealed reward. This paper investigates the attack model where an adversary attacks with a certain probability at each round, and its attack value can be arbitrary and unbounded if it attacks. Furthermore, the attack value does not necessarily follow a statistical distribution. We propose a novel sample median-based and exploration-aided UCB algorithm (called med-E-UCB) and a median-based $\epsilon$-greedy algorithm (called med-$\epsilon$-greedy). Both of these algorithms are provably robust to the aforementioned attack model. More specifically we show that both algorithms achieve $\mathcal{O}(\log T)$ pseudo-regret (i.e., the optimal regret without attacks). We also provide a high probability guarantee of $\mathcal{O}(\log T)$ regret with respect to random rewards and random occurrence of attacks. These bounds are achieved under arbitrary and unbounded reward perturbation as long as the attack probability does not exceed a certain constant threshold. We provide multiple synthetic simulations of the proposed algorithms to verify these claims and showcase the inability of existing techniques to achieve sublinear regret. We also provide experimental results of the algorithm operating in a cognitive radio setting using multiple software-defined radios.