 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge9th Workshop on Sign Language Translation and Avatar Technologies (SLTAT 2025)
Aug 11, 2025

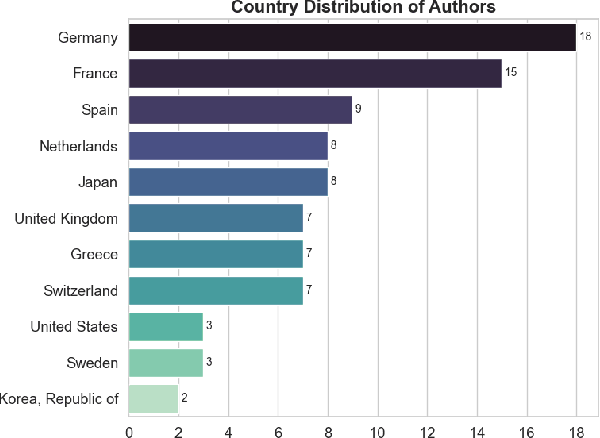
The Sign Language Translation and Avatar Technology (SLTAT) workshops continue a series of gatherings to share recent advances in improving deaf / human communication through non-invasive means. This 2025 edition, the 9th since its first appearance in 2011, is hosted by the International Conference on Intelligent Virtual Agents (IVA), giving the opportunity for contamination between two research communities, using digital humans as either virtual interpreters or as interactive conversational agents. As presented in this summary paper, SLTAT sees contributions beyond avatar technologies, with a consistent number of submissions on sign language recognition, and other work on data collection, data analysis, tools, ethics, usability, and affective computing.
Représentation graphique de la langue des signes française et édition logicielle
Jun 26, 2023Cet article propose une m\'ethode pour d\'efinir une forme graphique \'editable standardis\'ee pour les langues des signes, ainsi qu'une proposition "AZVD" et un \'editeur logiciel associ\'e. Inspir\'ee d'une part par les r\'egularit\'es observ\'ees dans les pratiques spontan\'ees de locuteurs pratiquant la sch\'ematisation, la d\'emarche tente garantir un syst\`eme qualifi\'e d'adoptable. Li\'ee d'autre part au mod\`ele formel de repr\'esentation AZee, elle vise \'egalement \`a sp\'ecifier un syst\`eme dont toutes les productions ont une lecture d\'etermin\'ee au point o\`u elles sont automatiquement synth\'etisables par un avatar. -- This paper proposes a definition method for an editable standard graphical form of Sign Language discourse representation. It also puts forward a tentative system "AZVD", and presents an associated software editor. The system is inspired by the regularities observed in spontaneous diagrams produced by some language users, in order to make it as adoptable as possible. Moreover, it is built upon the formal representation model AZee, so that any graphical instance produced by the system determines its own read-out form, to the point that they can be automatically synthesised by an avatar.
Example-Based Machine Translation from Text to a Hierarchical Representation of Sign Language
May 06, 2022

This article presents an original method for Text-to-Sign Translation. It compensates data scarcity using a domain-specific parallel corpus of alignments between text and hierarchical formal descriptions of Sign Language videos in AZee. Based on the detection of similarities present in the source text, the proposed algorithm recursively exploits matches and substitutions of aligned segments to build multiple candidate translations for a novel statement. This helps preserving Sign Language structures as much as possible before falling back on literal translations too quickly, in a generative way. The resulting translations are in the form of AZee expressions, designed to be used as input to avatar synthesis systems. We present a test set tailored to showcase its potential for expressiveness and generation of idiomatic target language, and observed limitations. This work finally opens prospects on how to evaluate translation and linguistic aspects, such as accuracy and grammatical fluency.
A human-editable Sign Language representation for software editing---and a writing system?
Nov 05, 2018

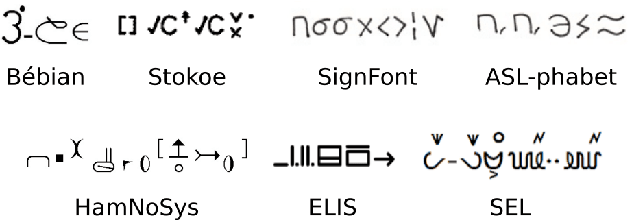
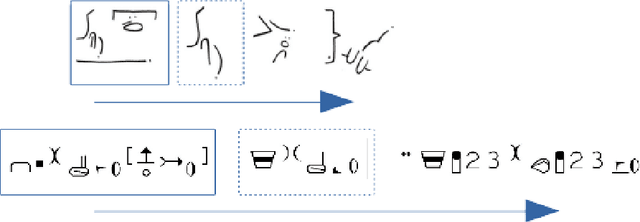
To equip SL with software properly, we need an input system to represent and manipulate signed contents in the same way that every day software allows to process written text. Refuting the claim that video is good enough a medium to serve the purpose, we propose to build a representation that is: editable, queryable, synthesisable and user-friendly---we define those terms upfront. The issue being functionally and conceptually linked to that of writing, we study existing writing systems, namely those in use for vocal languages, those designed and proposed for SLs, and more spontaneous ways in which SL users put their language in writing. Observing each paradigm in turn, we move on to propose a new approach to satisfy our goals of integration in software. We finally open the prospect of our proposition being used outside of this restricted scope, as a writing system in itself, and compare its properties to the other writing systems presented.
Synthesising Sign Language from semantics, approaching "from the target and back"
Jul 25, 2017
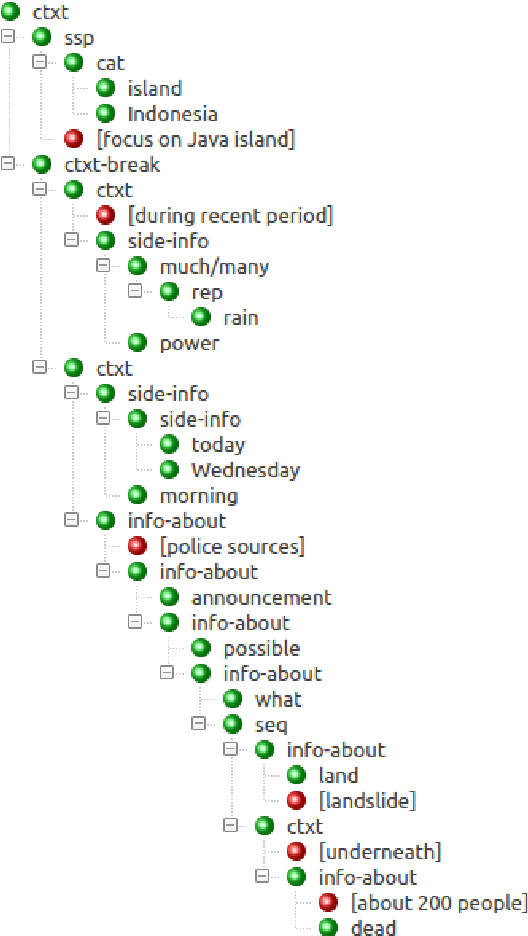
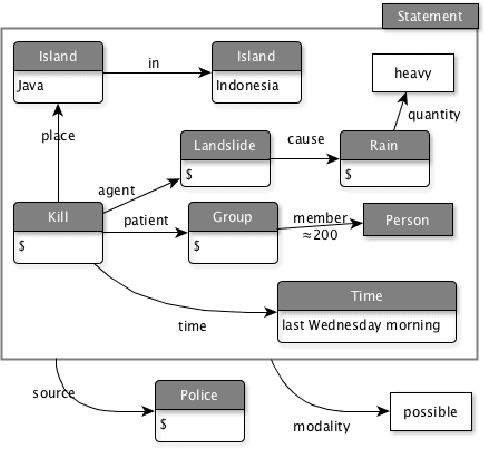
We present a Sign Language modelling approach allowing to build grammars and create linguistic input for Sign synthesis through avatars. We comment on the type of grammar it allows to build, and observe a resemblance between the resulting expressions and traditional semantic representations. Comparing the ways in which the paradigms are designed, we name and contrast two essentially different strategies for building higher-level linguistic input: "source-and-forward" vs. "target-and-back". We conclude by favouring the latter, acknowledging the power of being able to automatically generate output from semantically relevant input straight into articulations of the target language.