Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Sign Language from semantics, approaching "from the target and back"
Paper and Code
Jul 25, 2017
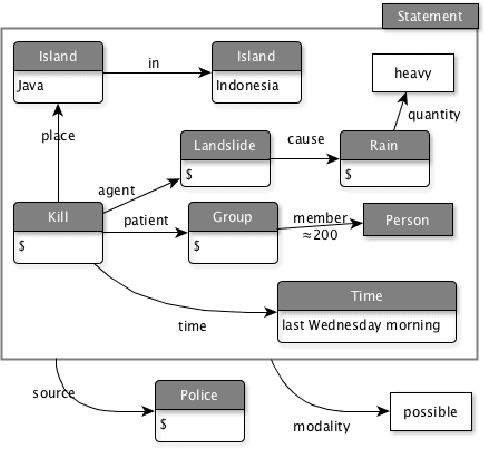
We present a Sign Language modelling approach allowing to build grammars and create linguistic input for Sign synthesis through avatars. We comment on the type of grammar it allows to build, and observe a resemblance between the resulting expressions and traditional semantic representations. Comparing the ways in which the paradigms are designed, we name and contrast two essentially different strategies for building higher-level linguistic input: "source-and-forward" vs. "target-and-back". We conclude by favouring the latter, acknowledging the power of being able to automatically generate output from semantically relevant input straight into articulations of the target language.
View paper on