 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDP: Learnable Dynamic Precision for Efficient Deep Neural Network Training and Inference
Mar 15, 2022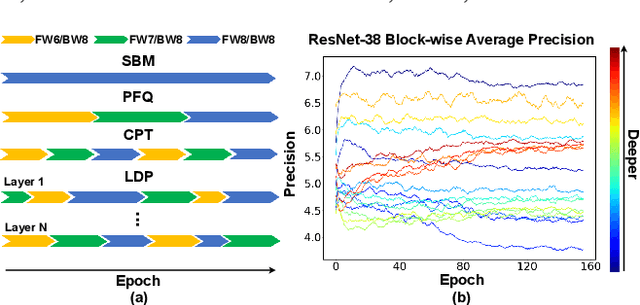

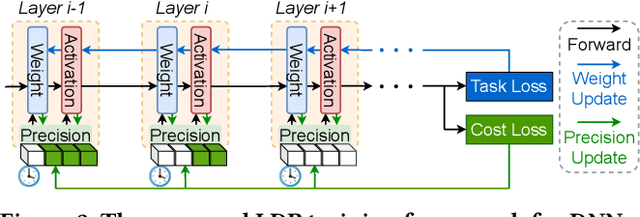

Low precision deep neural network (DNN) training is one of the most effective techniques for boosting DNNs' training efficiency, as it trims down the training cost from the finest bit level. While existing works mostly fix the model precision during the whole training process, a few pioneering works have shown that dynamic precision schedules help DNNs converge to a better accuracy while leading to a lower training cost than their static precision training counterparts. However, existing dynamic low precision training methods rely on manually designed precision schedules to achieve advantageous efficiency and accuracy trade-offs, limiting their more comprehensive practical applications and achievable performance. To this end, we propose LDP, a Learnable Dynamic Precision DNN training framework that can automatically learn a temporally and spatially dynamic precision schedule during training towards optimal accuracy and efficiency trade-offs. It is worth noting that LDP-trained DNNs are by nature efficient during inference. Furthermore, we visualize the resulting temporal and spatial precision schedule and distribution of LDP trained DNNs on different tasks to better understand the corresponding DNNs' characteristics at different training stages and DNN layers both during and after training, drawing insights for promoting further innovations. Extensive experiments and ablation studies (seven networks, five datasets, and three tasks) show that the proposed LDP consistently outperforms state-of-the-art (SOTA) low precision DNN training techniques in terms of training efficiency and achieved accuracy trade-offs. For example, in addition to having the advantage of being automated, our LDP achieves a 0.31\% higher accuracy with a 39.1\% lower computational cost when training ResNet-20 on CIFAR-10 as compared with the best SOTA method.
O-HAS: Optical Hardware Accelerator Search for Boosting Both Acceleration Performance and Development Speed
Aug 17, 2021
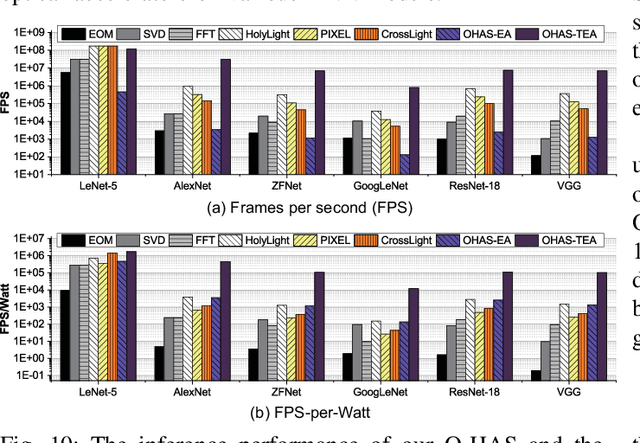

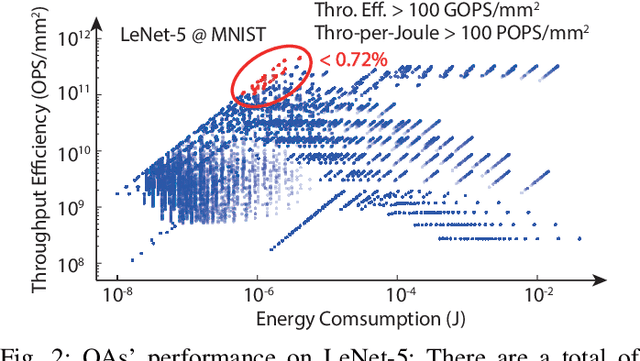
The recent breakthroughs and prohibitive complexities of Deep Neural Networks (DNNs) have excited extensive interest in domain-specific DNN accelerators, among which optical DNN accelerators are particularly promising thanks to their unprecedented potential of achieving superior performance-per-watt. However, the development of optical DNN accelerators is much slower than that of electrical DNN accelerators. One key challenge is that while many techniques have been developed to facilitate the development of electrical DNN accelerators, techniques that support or expedite optical DNN accelerator design remain much less explored, limiting both the achievable performance and the innovation development of optical DNN accelerators. To this end, we develop the first-of-its-kind framework dubbed O-HAS, which for the first time demonstrates automated Optical Hardware Accelerator Search for boosting both the acceleration efficiency and development speed of optical DNN accelerators. Specifically, our O-HAS consists of two integrated enablers: (1) an O-Cost Predictor, which can accurately yet efficiently predict an optical accelerator's energy and latency based on the DNN model parameters and the optical accelerator design; and (2) an O-Search Engine, which can automatically explore the large design space of optical DNN accelerators and identify the optimal accelerators (i.e., the micro-architectures and algorithm-to-accelerator mapping methods) in order to maximize the target acceleration efficiency. Extensive experiments and ablation studies consistently validate the effectiveness of both our O-Cost Predictor and O-Search Engine as well as the excellent efficiency of O-HAS generated optical accelerators.