 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Learning for Optimal Individualized Dose Intervals
Feb 24, 2022

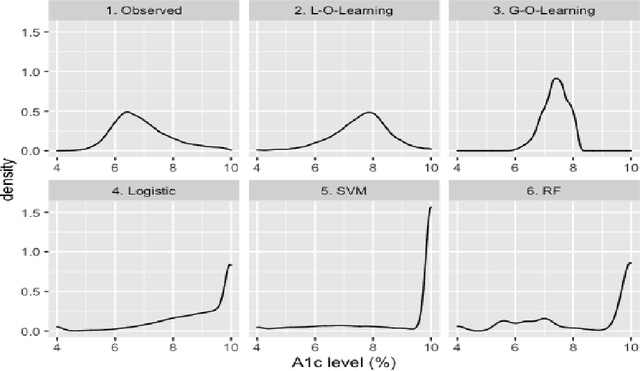
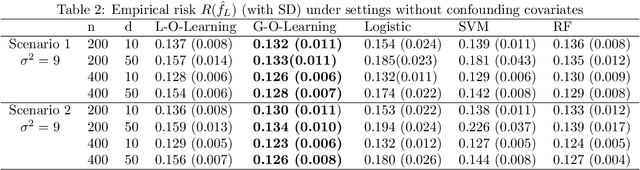
We study the problem of learning individualized dose intervals using observational data. There are very few previous works for policy learning with continuous treatment, and all of them focused on recommending an optimal dose rather than an optimal dose interval. In this paper, we propose a new method to estimate such an optimal dose interval, named probability dose interval (PDI). The potential outcomes for doses in the PDI are guaranteed better than a pre-specified threshold with a given probability (e.g., 50%). The associated nonconvex optimization problem can be efficiently solved by the Difference-of-Convex functions (DC) algorithm. We prove that our estimated policy is consistent, and its risk converges to that of the best-in-class policy at a root-n rate. Numerical simulations show the advantage of the proposed method over outcome modeling based benchmarks. We further demonstrate the performance of our method in determining individualized Hemoglobin A1c (HbA1c) control intervals for elderly patients with diabetes.
Robust Sample Weighting to Facilitate Individualized Treatment Rule Learning for a Target Population
May 03, 2021
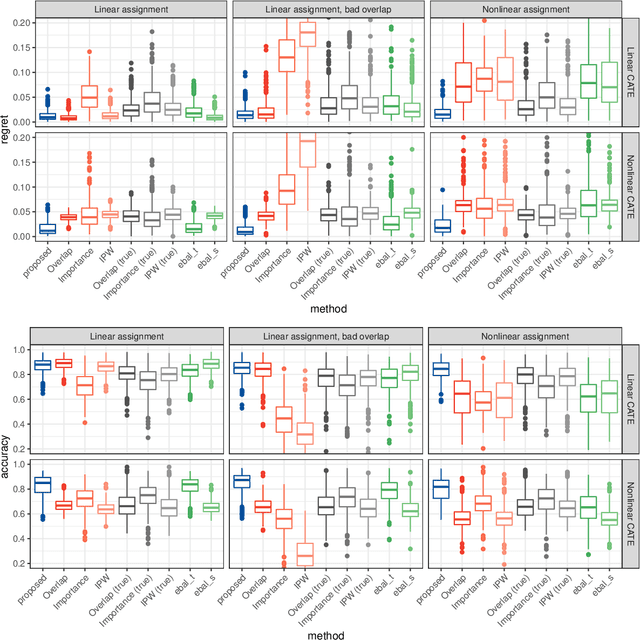
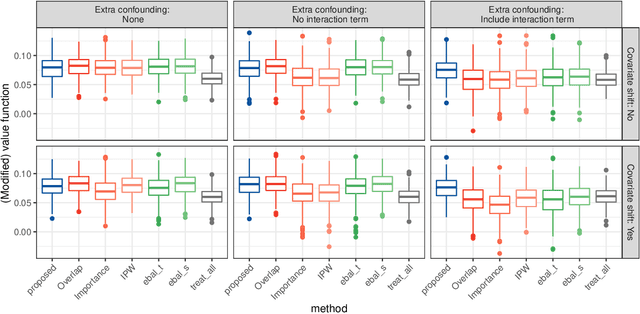
Learning individualized treatment rules (ITRs) is an important topic in precision medicine. Current literature mainly focuses on deriving ITRs from a single source population. We consider the observational data setting when the source population differs from a target population of interest. We assume subject covariates are available from both populations, but treatment and outcome data are only available from the source population. Although adjusting for differences between source and target populations can potentially lead to an improved ITR for the target population, it can substantially increase the variability in ITR estimation. To address this dilemma, we develop a weighting framework that aims to tailor an ITR for a given target population and protect against high variability due to superfluous covariate shift adjustments. Our method seeks covariate balance over a nonparametric function class characterized by a reproducing kernel Hilbert space and can improve many ITR learning methods that rely on weights. We show that the proposed method encompasses importance weights and the so-called overlap weights as two extreme cases, allowing for a better bias-variance trade-off in between. Numerical examples demonstrate that the use of our weighting method can greatly improve ITR estimation for the target population compared with other weighting methods.