 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Generative ConvNets for Exemplar-based Texture Synthesis
Dec 17, 2019

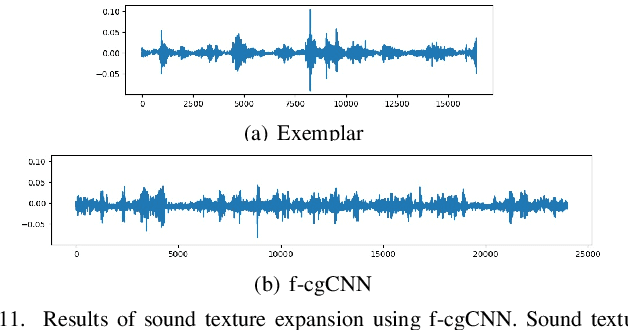

The goal of exemplar-based texture synthesis is to generate texture images that are visually similar to a given exemplar. Recently, promising results have been reported by methods relying on convolutional neural networks (ConvNets) pretrained on large-scale image datasets. However, these methods have difficulties in synthesizing image textures with non-local structures and extending to dynamic or sound textures. In this paper, we present a conditional generative ConvNet (cgCNN) model which combines deep statistics and the probabilistic framework of generative ConvNet (gCNN) model. Given a texture exemplar, the cgCNN model defines a conditional distribution using deep statistics of a ConvNet, and synthesize new textures by sampling from the conditional distribution. In contrast to previous deep texture models, the proposed cgCNN dose not rely on pre-trained ConvNets but learns the weights of ConvNets for each input exemplar instead. As a result, the cgCNN model can synthesize high quality dynamic, sound and image textures in a unified manner. We also explore the theoretical connections between our model and other texture models. Further investigations show that the cgCNN model can be easily generalized to texture expansion and inpainting. Extensive experiments demonstrate that our model can achieve better or at least comparable results than the state-of-the-art methods.