 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental study for early diagnosing Parkinson's disease using machine learning
Oct 20, 2023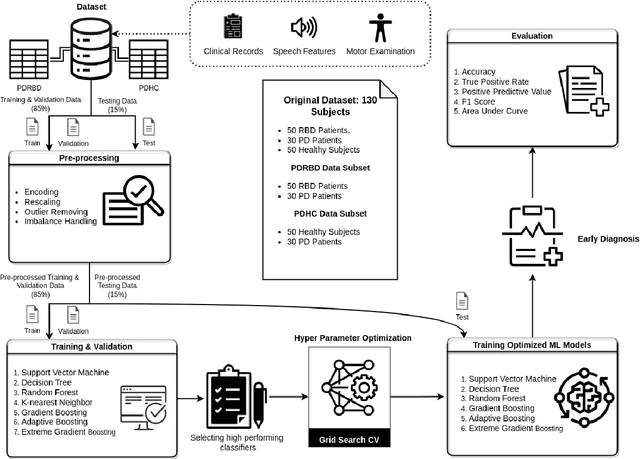
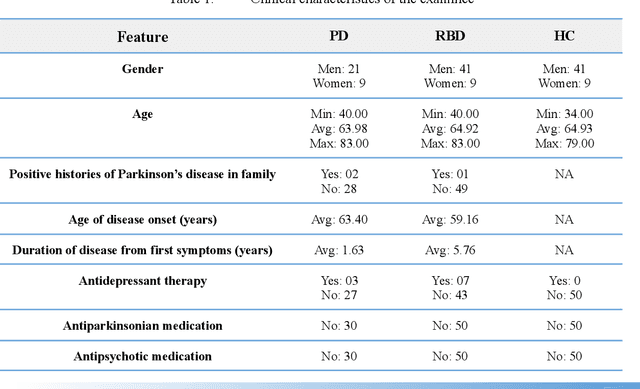
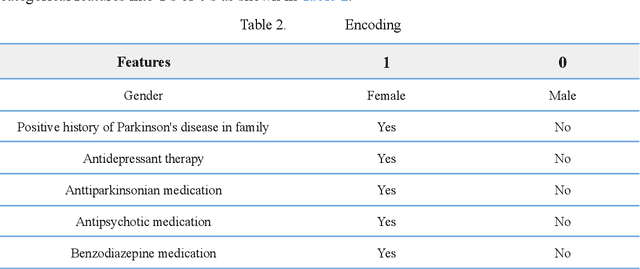
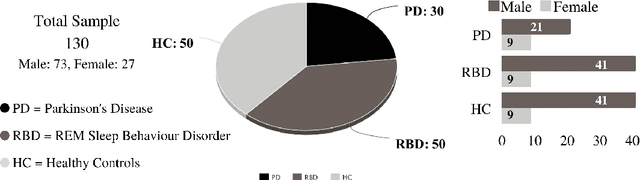
One of the most catastrophic neurological disorders worldwide is Parkinson's Disease. Along with it, the treatment is complicated and abundantly expensive. The only effective action to control the progression is diagnosing it in the early stage. However, this is challenging because early detection necessitates a large and complex clinical study. This experimental work used Machine Learning techniques to automate the early detection of Parkinson's Disease from clinical characteristics, voice features and motor examination. In this study, we develop ML models utilizing a public dataset of 130 individuals, 30 of whom are untreated Parkinson's Disease patients, 50 of whom are Rapid Eye Movement Sleep Behaviour Disorder patients who are at a greater risk of contracting Parkinson's Disease, and 50 of whom are Healthy Controls. We use MinMax Scaler to rescale the data points, Local Outlier Factor to remove outliers, and SMOTE to balance existing class frequency. Afterwards, apply a number of Machine Learning techniques. We implement the approaches in such a way that data leaking and overfitting are not possible. Finally, obtained 100% accuracy in classifying PD and RBD patients, as well as 92% accuracy in classifying PD and HC individuals.
Streamlining Brain Tumor Classification with Custom Transfer Learning in MRI Images
Oct 19, 2023Brain tumors are increasingly prevalent, characterized by the uncontrolled spread of aberrant tissues in the brain, with almost 700,000 new cases diagnosed globally each year. Magnetic Resonance Imaging (MRI) is commonly used for the diagnosis of brain tumors and accurate classification is a critical clinical procedure. In this study, we propose an efficient solution for classifying brain tumors from MRI images using custom transfer learning networks. While several researchers have employed various pre-trained architectures such as RESNET-50, ALEXNET, VGG-16, and VGG-19, these methods often suffer from high computational complexity. To address this issue, we present a custom and lightweight model using a Convolutional Neural Network-based pre-trained architecture with reduced complexity. Specifically, we employ the VGG-19 architecture with additional hidden layers, which reduces the complexity of the base architecture but improves computational efficiency. The objective is to achieve high classification accuracy using a novel approach. Finally, the result demonstrates a classification accuracy of 96.42%.
* 6 pages, 9 figures, 4 tables
Detecting Chronic Kidney Disease(CKD) at the Initial Stage: A Novel Hybrid Feature-selection Method and Robust Data Preparation Pipeline for Different ML Techniques
Mar 02, 2022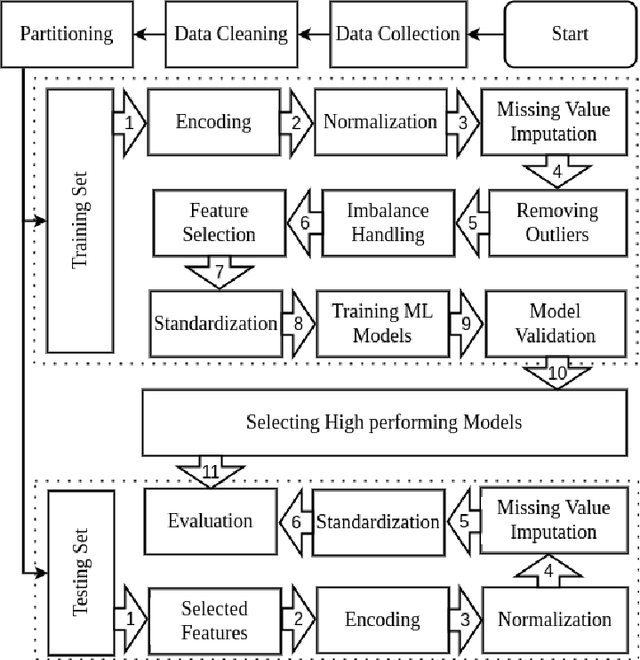

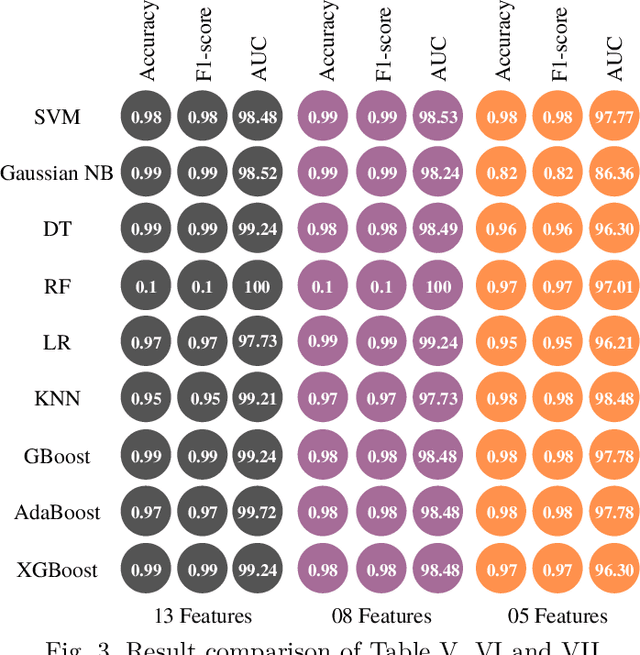
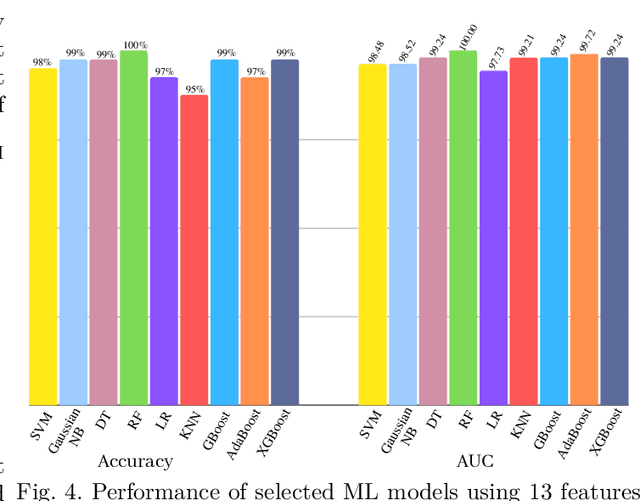
Chronic Kidney Disease (CKD) has infected almost 800 million people around the world. Around 1.7 million people die each year because of it. Detecting CKD in the initial stage is essential for saving millions of lives. Many researchers have applied distinct Machine Learning (ML) methods to detect CKD at an early stage, but detailed studies are still missing. We present a structured and thorough method for dealing with the complexities of medical data with optimal performance. Besides, this study will assist researchers in producing clear ideas on the medical data preparation pipeline. In this paper, we applied KNN Imputation to impute missing values, Local Outlier Factor to remove outliers, SMOTE to handle data imbalance, K-stratified K-fold Cross-validation to validate the ML models, and a novel hybrid feature selection method to remove redundant features. Applied algorithms in this study are Support Vector Machine, Gaussian Naive Bayes, Decision Tree, Random Forest, Logistic Regression, K-Nearest Neighbor, Gradient Boosting, Adaptive Boosting, and Extreme Gradient Boosting. Finally, the Random Forest can detect CKD with 100% accuracy without any data leakage.
A Comparative Study of Sentiment Analysis Using NLP and Different Machine Learning Techniques on US Airline Twitter Data
Oct 02, 2021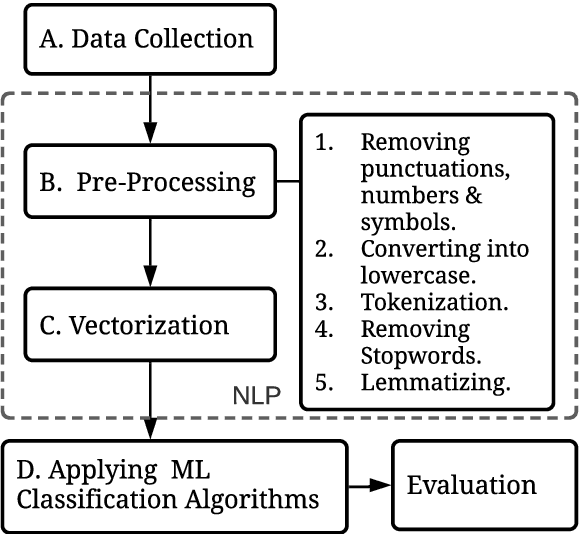
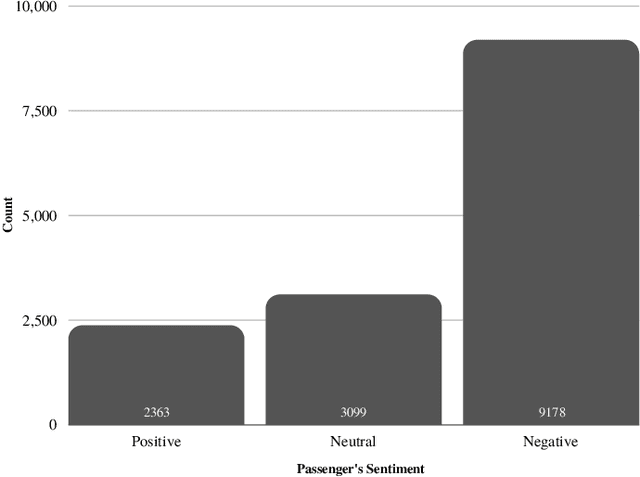

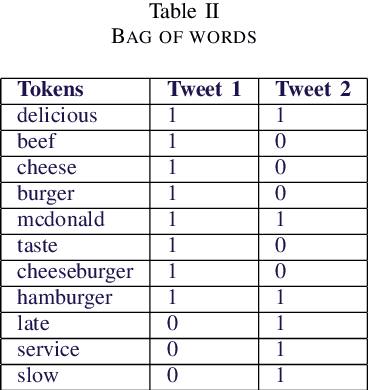
Today's business ecosystem has become very competitive. Customer satisfaction has become a major focus for business growth. Business organizations are spending a lot of money and human resources on various strategies to understand and fulfill their customer's needs. But, because of defective manual analysis on multifarious needs of customers, many organizations are failing to achieve customer satisfaction. As a result, they are losing customer's loyalty and spending extra money on marketing. We can solve the problems by implementing Sentiment Analysis. It is a combined technique of Natural Language Processing (NLP) and Machine Learning (ML). Sentiment Analysis is broadly used to extract insights from wider public opinion behind certain topics, products, and services. We can do it from any online available data. In this paper, we have introduced two NLP techniques (Bag-of-Words and TF-IDF) and various ML classification algorithms (Support Vector Machine, Logistic Regression, Multinomial Naive Bayes, Random Forest) to find an effective approach for Sentiment Analysis on a large, imbalanced, and multi-classed dataset. Our best approaches provide 77% accuracy using Support Vector Machine and Logistic Regression with Bag-of-Words technique.