 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Chronic Kidney Disease(CKD) at the Initial Stage: A Novel Hybrid Feature-selection Method and Robust Data Preparation Pipeline for Different ML Techniques
Mar 02, 2022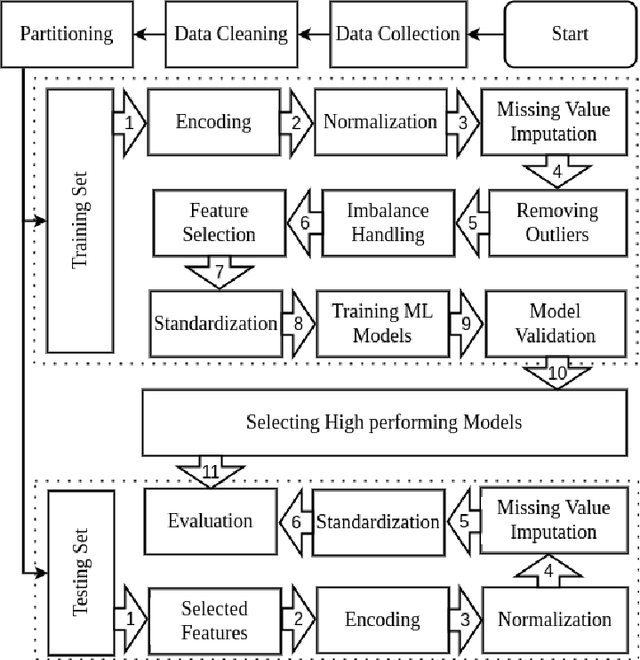

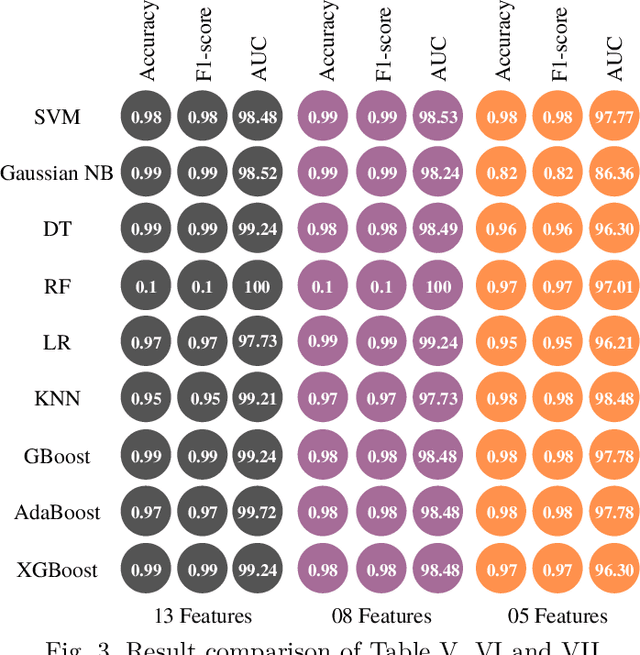
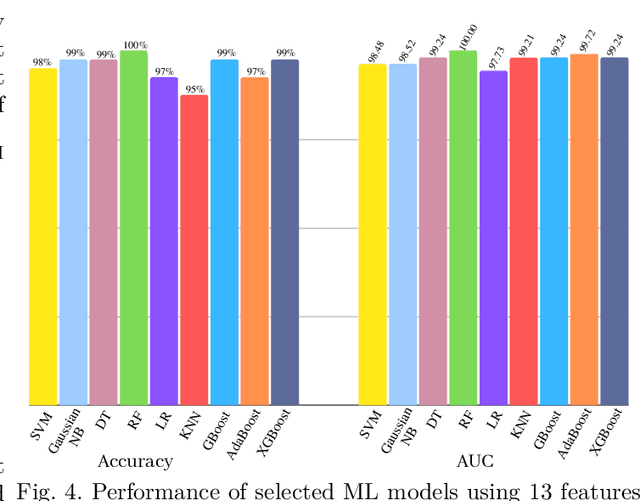
Chronic Kidney Disease (CKD) has infected almost 800 million people around the world. Around 1.7 million people die each year because of it. Detecting CKD in the initial stage is essential for saving millions of lives. Many researchers have applied distinct Machine Learning (ML) methods to detect CKD at an early stage, but detailed studies are still missing. We present a structured and thorough method for dealing with the complexities of medical data with optimal performance. Besides, this study will assist researchers in producing clear ideas on the medical data preparation pipeline. In this paper, we applied KNN Imputation to impute missing values, Local Outlier Factor to remove outliers, SMOTE to handle data imbalance, K-stratified K-fold Cross-validation to validate the ML models, and a novel hybrid feature selection method to remove redundant features. Applied algorithms in this study are Support Vector Machine, Gaussian Naive Bayes, Decision Tree, Random Forest, Logistic Regression, K-Nearest Neighbor, Gradient Boosting, Adaptive Boosting, and Extreme Gradient Boosting. Finally, the Random Forest can detect CKD with 100% accuracy without any data leakage.