 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Sparsification of Graph Convolutional Networks without Sacrificing the Accuracy
Aug 06, 2022
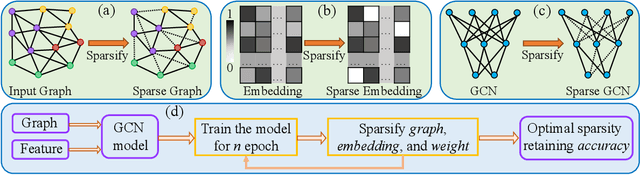

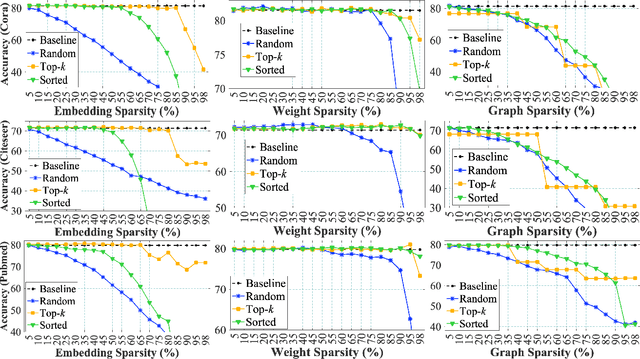
Graph Neural Networks (GNNs) are widely used to perform different machine learning tasks on graphs. As the size of the graphs grows, and the GNNs get deeper, training and inference time become costly in addition to the memory requirement. Thus, without sacrificing accuracy, graph sparsification, or model compression becomes a viable approach for graph learning tasks. A few existing techniques only study the sparsification of graphs and GNN models. In this paper, we develop a SparseGCN pipeline to study all possible sparsification in GNN. We provide a theoretical analysis and empirically show that it can add up to 11.6\% additional sparsity to the embedding matrix without sacrificing the accuracy of the commonly used benchmark graph datasets.
MarkovGNN: Graph Neural Networks on Markov Diffusion
Feb 05, 2022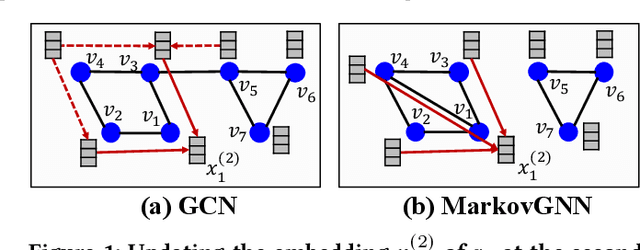

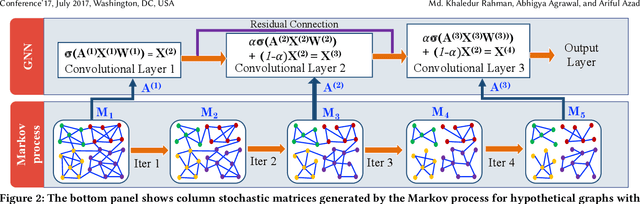
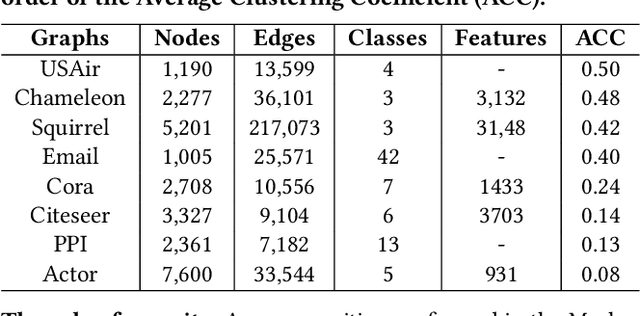
Most real-world networks contain well-defined community structures where nodes are densely connected internally within communities. To learn from these networks, we develop MarkovGNN that captures the formation and evolution of communities directly in different convolutional layers. Unlike most Graph Neural Networks (GNNs) that consider a static graph at every layer, MarkovGNN generates different stochastic matrices using a Markov process and then uses these community-capturing matrices in different layers. MarkovGNN is a general approach that could be used with most existing GNNs. We experimentally show that MarkovGNN outperforms other GNNs for clustering, node classification, and visualization tasks. The source code of MarkovGNN is publicly available at \url{https://github.com/HipGraph/MarkovGNN}.
A Comprehensive Analytical Survey on Unsupervised and Semi-Supervised Graph Representation Learning Methods
Dec 20, 2021
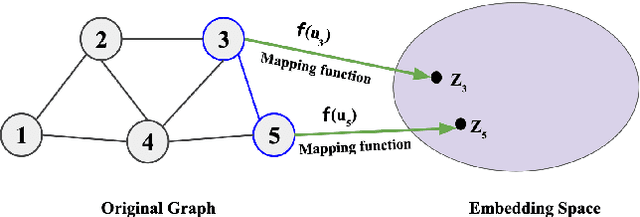
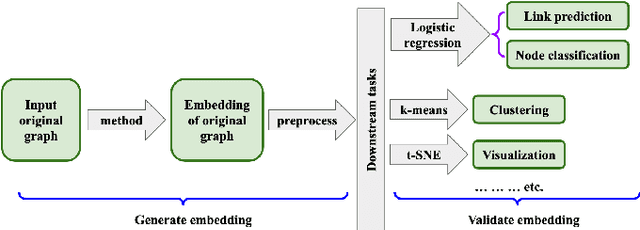
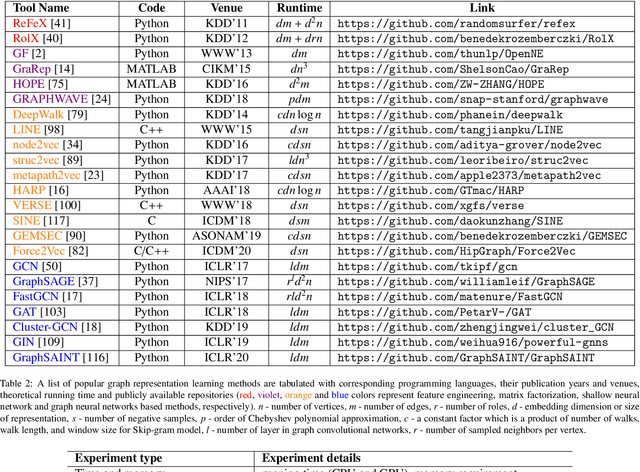
Graph representation learning is a fast-growing field where one of the main objectives is to generate meaningful representations of graphs in lower-dimensional spaces. The learned embeddings have been successfully applied to perform various prediction tasks, such as link prediction, node classification, clustering, and visualization. The collective effort of the graph learning community has delivered hundreds of methods, but no single method excels under all evaluation metrics such as prediction accuracy, running time, scalability, etc. This survey aims to evaluate all major classes of graph embedding methods by considering algorithmic variations, parameter selections, scalability, hardware and software platforms, downstream ML tasks, and diverse datasets. We organized graph embedding techniques using a taxonomy that includes methods from manual feature engineering, matrix factorization, shallow neural networks, and deep graph convolutional networks. We evaluated these classes of algorithms for node classification, link prediction, clustering, and visualization tasks using widely used benchmark graphs. We designed our experiments on top of PyTorch Geometric and DGL libraries and run experiments on different multicore CPU and GPU platforms. We rigorously scrutinize the performance of embedding methods under various performance metrics and summarize the results. Thus, this paper may serve as a comparative guide to help users select methods that are most suitable for their tasks.
FusedMM: A Unified SDDMM-SpMM Kernel for Graph Embedding and Graph Neural Networks
Nov 07, 2020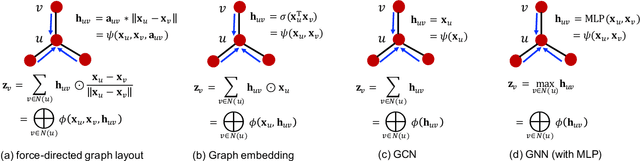
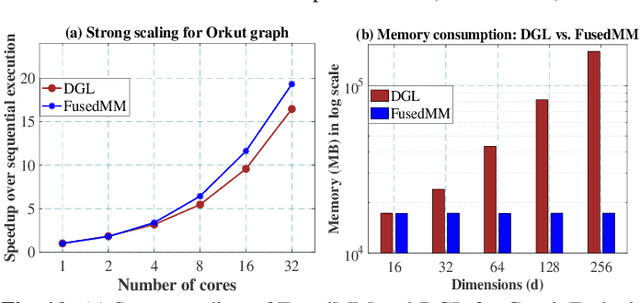
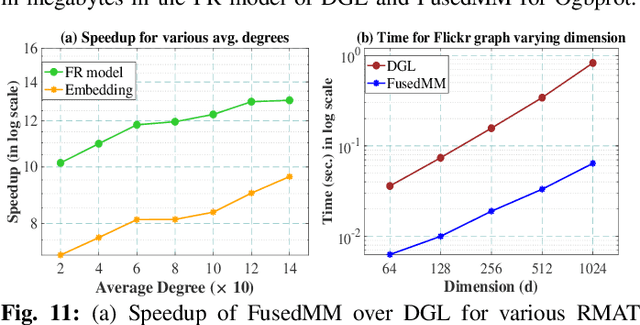
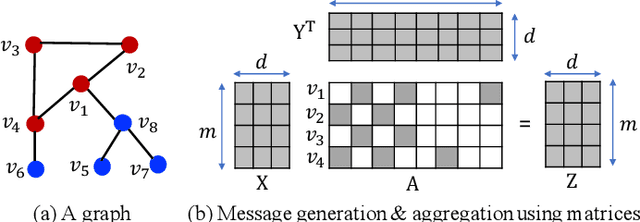
We develop a fused matrix multiplication kernel that unifies sampled dense-dense matrix multiplication and sparse-dense matrix multiplication under a single operation called FusedMM. By using user-defined functions, FusedMM can capture almost all computational patterns needed by popular graph embedding and GNN approaches. FusedMM is an order of magnitude faster than its equivalent kernels in Deep Graph Library. The superior performance of FusedMM comes from the low-level vectorized kernels, a suitable load balancing scheme and an efficient utilization of the memory bandwidth. FusedMM can tune its performance using a code generator and perform equally well on Intel, AMD and ARM processors. FusedMM speeds up an end-to-end graph embedding algorithm by up to 28x on different processors.
Force2Vec: Parallel force-directed graph embedding
Sep 17, 2020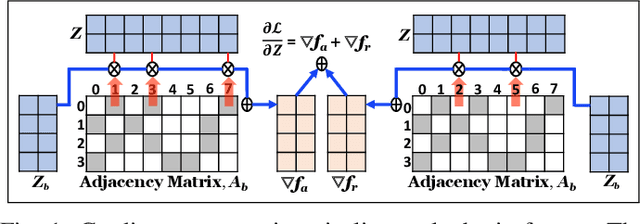
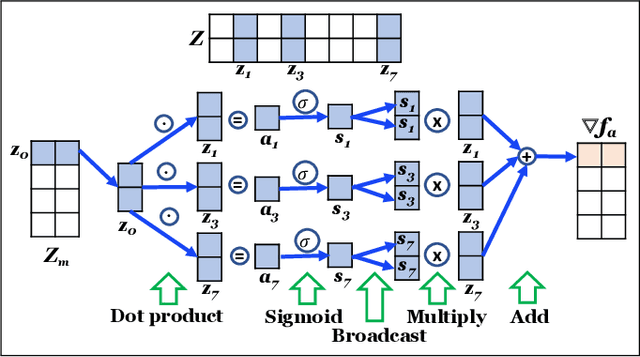
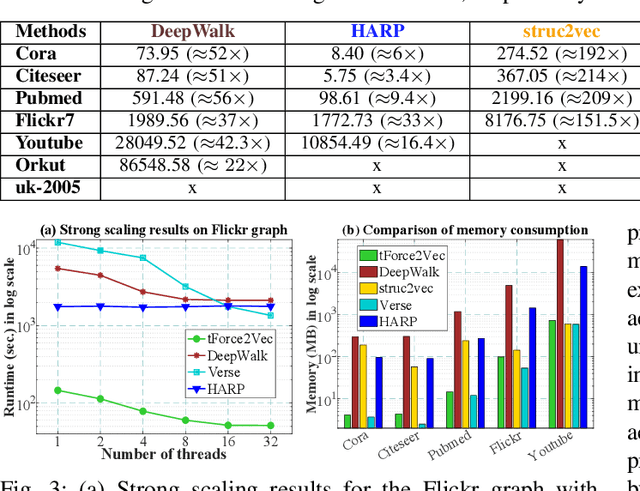

A graph embedding algorithm embeds a graph into a low-dimensional space such that the embedding preserves the inherent properties of the graph. While graph embedding is fundamentally related to graph visualization, prior work did not exploit this connection explicitly. We develop Force2Vec that uses force-directed graph layout models in a graph embedding setting with an aim to excel in both machine learning (ML) and visualization tasks. We make Force2Vec highly parallel by mapping its core computations to linear algebra and utilizing multiple levels of parallelism available in modern processors. The resultant algorithm is an order of magnitude faster than existing methods (43x faster than DeepWalk, on average) and can generate embeddings from graphs with billions of edges in a few hours. In comparison to existing methods, Force2Vec is better in graph visualization and performs comparably or better in ML tasks such as link prediction, node classification, and clustering. Source code is available at https://github.com/HipGraph/Force2Vec.
Training Sensitivity in Graph Isomorphism Network
Aug 19, 2020
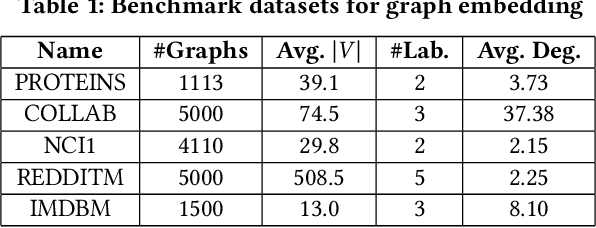
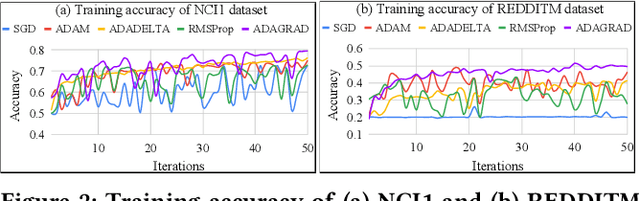

Graph neural network (GNN) is a popular tool to learn the lower-dimensional representation of a graph. It facilitates the applicability of machine learning tasks on graphs by incorporating domain-specific features. There are various options for underlying procedures (such as optimization functions, activation functions, etc.) that can be considered in the implementation of GNN. However, most of the existing tools are confined to one approach without any analysis. Thus, this emerging field lacks a robust implementation ignoring the highly irregular structure of the real-world graphs. In this paper, we attempt to fill this gap by studying various alternative functions for a respective module using a diverse set of benchmark datasets. Our empirical results suggest that the generally used underlying techniques do not always perform well to capture the overall structure from a set of graphs.
* Accepted for publication in CIKM 2020